 Пока в нашей базе данных всего две таблицы, и до сих пор мы еще не говорили о том, как принимается решение о том, какие данные попадут в каждую из таблиц; мы делали то, что представлялось нам разумным. На самом деле проектирование схемы базы данных (корректно называть конструкцию, включающую в себя таблицы, столбцы и отношения, схемой) может быть очень сложным занятием.
Пока в нашей базе данных всего две таблицы, и до сих пор мы еще не говорили о том, как принимается решение о том, какие данные попадут в каждую из таблиц; мы делали то, что представлялось нам разумным. На самом деле проектирование схемы базы данных (корректно называть конструкцию, включающую в себя таблицы, столбцы и отношения, схемой) может быть очень сложным занятием.
Проектирование базы данных, состоящей из нескольких десятков таблиц, представляет собой серьезную задачу. Люди, занимающиеся этим, получают деньги за то, что они хорошо делают эту трудную работу.
Несколько эвристических правил
К счастью, для достаточно простых баз данных (приблизительно до десяти таблиц) проектирование не так уж сложно, и вы, приобретя некоторые навыки, сможете создавать разумные конструкции.
В этом разделе рассмотрим простую базу данных, которую мы уже начали создавать, и попытаемся понять, какими соображениями следует руководствоваться, определяя, какие таблицы необходимо создать.
При проектировании базы данных обычно выполняется «нормализация», то есть применяется некоторый набор правил, гарантирующих, что данные будут распределены соответствующим образом. Для начала нам потребуется несколько основных правил. Надеемся (и настаиваем на том, что этого не следует делать), что вам не придет в голову, прочитав эти правила, сразу же взяться за создание базы, состоящей из двадцати таблиц. Эти правила приведены только для того, чтобы облегчить читателям понимание базы данных, которая используется в моем блоге для изучения SQL и PostgreSQL.
Правило первое - разбивайте данные на столбцы
Первое правило состоит в том, что в каждый столбец должен быть помещен один фрагмент информации (атрибут). Это кажется вполне логичным. Уже в электронной таблице информация по каждому клиенту была естественным образом разбита на столбцы так, что, например, фамилия была отделена от почтового индекса.
В электронных таблицах соблюдение этого правила делает более удобной работу с данными, например сортировку по индексу. Что же касается баз данных, важнейшим условием является правильное разбиение данных на атрибуты. Почему это так важно? С практической точки зрения весьма сложно будет указать, что нас интересуют данные, находящиеся с 29-й по 35-ю позицию в столбце адреса, т. к. именно там должен находиться почтовый индекс. Если данных достаточно много, наступит момент, когда индекс появится на другой позиции, и мы получим неверный фрагмент информации. Еще одна причина необходимости корректного разбиения на столбцы состоит в том, что все столбцы базы данных должны содержать данные одного типа.
Правило второе - однозначно идентифицируйте каждую строку
Если вы помните, при попытке однозначно идентифицировать строки в электронной таблице оказалось, что трудно решить, что же является уникальным признаком. Не было первичного ключа. Первичный ключ не обязательно должен представлять собой отдельный уникальный столбец, это может быть и комбинация двух и даже трех столбцов, которая однозначно определяет строку.
В любом случае необходимо задать что-то так, чтобы, используя это что-то, можно было с полной уверенностью сказать: «Глядя на X в этой строке, можно не сомневаться, что его значение будет отличаться от значений всех остальных строк данной таблицы». Если не удается выбрать столбец или комбинацию столбцов, которая однозначно определяла бы строку, необходимо ввести дополнительный столбец, смысл которого будет только в обеспечении уникальности строки. В таблицу customer был введен дополнительный столбец customer_id, и теперь строки идентифицируются однозначно.
Правило третье - удаляйте повторяющуюся информацию
Когда мы пытались сохранить данные о заказах в таблице customer, она становилась некрасивой из-за проблемы повторяющихся групп. Для каждого клиента приходилось повторять информацию о заказе столько раз, сколько требовалось. То есть предугадать, сколько столбцов нужно отвести для заказов, было невозможно. В базе данных количество столбцов фиксируется при проектировании. Так что необходимо заранее решить, сколько потребуется столбцов, какого они будут типа, и дать каждому столбцу название, только тогда можно будет сохранять какие-то данные. Ни в коем случае не храните повторяющиеся группы данных в одной строке.
Обойти это ограничение можно так, как мы это и сделали, - разделив данные о клиентах и заказах на две таблицы и используя столбец customer^ для объединения таблиц в тех случаях, когда потребуется информация из обеих таблиц.
Если говорить более формально, была создана зависимость «многие-к- одному», другими словами, несколько заказов могло быть получено от одного клиента.
Правило четвертое - давайте непротиворечивые названия
Вероятно, это правило сложнее всего выполнить. Как назвать таблицу или столбец? Если название не придумывается, это часто бывает сигналом того, что в конструкции таблицы или столбца что-то неладно.
Многие разработчики баз данных имеют свой собственный набор правил, которыми они руководствуются, именуя таблицы и столбцы для того, чтобы в названиях не было противоречивости. Например, нельзя, чтобы имена каких-то таблиц были существительными в единственном числе, а других - во множественном (не «офис» и «отделы», а «офис» и «отдел»). Если выбрано имя для столбца с идентификаторами, может быть, tablename_id, то следует придерживаться этого правила и в названиях других подобных столбцов. Если вы используете сокращения, делайте это постоянно. Если столбец одной таблицы является ключом для другой, постарайтесь дать им имена, образованные от одной основы.
Цель всех этих действий чрезвычайно проста - таблицы и столбцы должны иметь короткие значащие имена, а процесс присваивания имен в пределах базы данных должен быть последовательным. Достижение такой, казалось бы, простой цели, часто бывает весьма непростым занятием, но и вознаграждение мы получаем не маленькое - ведение базы данных значительно облегчается.
Схема базы данных «Клиенты и заказы»
Можно нарисовать план (схему) базы данных, отразив отношения сущностей. Для нашей базы данных из двух таблиц схематическое изображение представлено на рис. 1:

Рис. 1. База данных «Клиенты и заказы»
Представлены две таблицы, столбцы, типы данных и размеры для каждого столбца, а также показано, что customer_id - это столбец, объединяющий две таблицы. Обратите внимание на направление стрелки - из таблицы orderinfo в таблицу customer. Это означает, что для каждой записи в orderinfo есть не более одной записи в customer, но каждому клиенту может соответствовать несколько заказов.
Очень важно помнить о том, кто есть кто в отношении «один-ко-мно- гим», иначе может возникнуть масса проблем. Заметьте также, что столбец, который будет использоваться для объединения двух таблиц, получил одно и то же имя в обеих таблицах - customer_id. Это не жизненно важно, при желании можно было назвать эти два столбца foo и bar, но постоянство в именовании в дальнейшем очень нам поможет.
В сложных базах данных отсутствие единообразия в названиях (например, customer_id, customer_ident, cust_id или cust_no) может быть чрезвычайно неудобным. Поэтому всегда разумнее потратить время на присваивание хороших и осмысленных имен, это надолго облегчит вам жизнь.

Добавляем таблицы в базу данных
Очевидно, что информация, в данный момент находящаяся в базе данных, является недостаточной, поскольку не известно, из каких пунктов состоит каждый заказ. Если помните, составляющие заказов были опущены сознательно, при этом мы обещали вернуться к этой проблеме позже. Пришло время распределить товары по заказам.
Проблема состоит в том, что заранее не известно, сколько пунктов содержит каждый заказ (аналогично тому, как заранее не известно, сколько заказов может разместить каждый из клиентов). Заказ может включать в себя один, два или даже сто товаров. Необходимо отделить информацию о том, что клиент сделал заказ, от деталей самого заказа. Следует попытаться создать нечто, подобное изображенному на рис. 2:

Рис. 2. Расширяем базу данных «Клиенты и заказы»
Как и при создании таблиц customer и orderinfo, разделим информацию на две таблицы, а затем объединим их. Правда при этом возникает одна небольшая проблема.
Если тщательно проанализировать отношения между заказом и отдельными товарами, станет ясно, что не только каждая запись из or- derinfo может быть связана со многими товарами, но и один и тот же товар может присутствовать во многих заказах (если несколько клиентов заказали один и тот же товар). Попытаемся изобразить эти две таблицы на диаграмме сущностей (рис. 3):
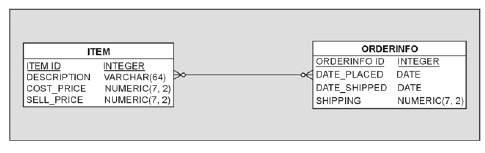
Рис. 3. Отношение между таблицами заказов и товаров
Представлено отношение «многие-ко-многим» - каждый заказ может ссылаться на множество товаров, и каждый товар может появляться во множестве заказов. Это подрывает некоторые из основ реляционных баз данных. Пока не будем вдаваться в детали, заметим только, что в реляционной базе данных никакие две таблицы не должны находится в отношениях «многие-ко-многим».
Можно попытаться обойти эту проблему, создав отдельную запись в каждой строке таблицы item для каждого заказа, но тогда придется многократно повторить описание и информацию о цене для каждого товара, что нарушило бы правило третье (удалять повторяющуюся информацию!).
Что касается нашей проблемы, то для нее существует стандартное решение. Необходимо создать третью таблицу между двумя существующими, она будет реализовывать отношение «многие-ко-многим». Надо сказать, что объяснять сложнее, чем делать, поэтому просто создадим эту третью таблицу, orderline, которая свяжет заказы с товарами.
Создана таблица, строки которой соответствуют каждой строчке заказа (рис. 4). Для каждой отдельной строки можно определить, из какого она заказа, по столбцу orderinfo_id, а товар, на который она ссылается, - по столбцу item_id.
Один товар может присутствовать во многих строках таблицы orderline, а один заказ также может встречаться в нескольких ее строках. Однако каждая строка промежуточной таблицы ссылается только на один товар и может присутствовать только в одном заказе.
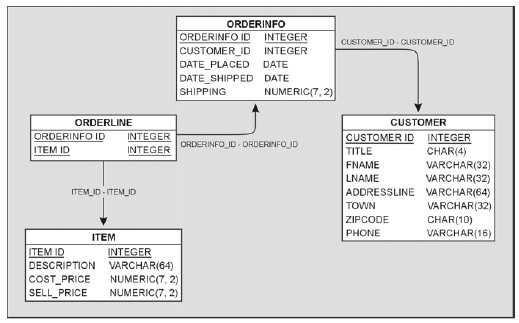
Рис. 4. Добавление в базу данных таблицы orderline
Обратите внимание, что в новую таблицу не введен уникальный идентификатор для каждой строки. Дело в том, что комбинация orderin- fo_id и item_id всегда уникальна. Но и здесь есть одна почти незаметная проблема. Что произойдет, если клиент закажет два экземпляра товара в одном заказе?
Просто ввести еще одну строку в orderline нельзя, поскольку комбинация orderinfo_id и item_id должна быть уникальной. Неужели придется добавить еще одну специальную таблицу для обслуживания заказов, содержащих несколько экземпляров одного товара? К счастью, нет. Есть гораздо более простой способ. Надо просто ввести поле «количество» (quantity) в таблицу orderline, и все будет хорошо.
Завершение первичного проекта
Осталось сохранить еще две порции данных, и в первом приближении основная структура нашей базы данных будет готова. Нас интересуют штрих-код для каждого продукта, а также количество товаров каждого вида, имеющихся на складе.
Может случиться так, что каждый продукт будет иметь несколько штрих-кодов, потому что если производитель вносит значительные изменения в упаковку продукта, он также часто меняет и штрих-код. Например, все наверняка видели упаковки с надписью «+20% бесплатно», стоимость такой (например) бутылки лимонада не меняется, но зато благодаря этой рекламной акции лимонада вы получаете больше. Обычно в таких случаях производители изменяют штрих-код, но сам продукт, по существу, не меняется. Возникает отношение: множество штрих-кодов для одного продукта. Добавляем таблицу для хранения штрих-кодов (рис. 5):
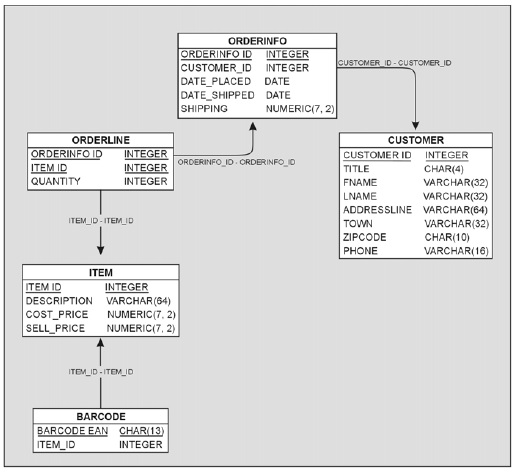
Рис. 5. Добавление в базу данных таблицы BARCODE
Заметьте, что стрелка идет в направлении от таблицы BARCODE к таблице ITEM, потому что именно штрих-кодов может быть несколько для одного товара. Обратите внимание на то, что barcode_ean является первичным ключом, т. к. для каждого штрих-кода должна существовать уникальная строка и (хотя один продукт и может иметь несколько штрих-кодов) ни один штрих-код не может принадлежать более чем одному продукту.
Наконец, последнее добавление, которое следует внести в проект базы данных, - объем запасов каждого продукта.
Есть два пути реализации такого добавления. Если большинство товаров находится на складе, то информация о таких запасах весьма важна, и тогда можно хранить количество продуктов, имеющихся на складе, непосредственно в таблице item.
Но может быть и так, что у нас множество товаров, при этом чаще всего лишь какие-то из них присутствуют на складе, а объем информации, которую приходится хранить для товаров, находящихся на складе, весьма велик. Например, для склада необходимо хранить информацию о размещении, номерах партий и сроках годности. Если в картотеке имеется 500 000 товаров, а на складе есть только 1000, то хранение данных по всем товарам будет просто расточительством. У этой проблемы есть стандартное решение - дополнительная таблица.
Следует создать новую таблицу, в которой хранилась бы «дополнительная информация» (например, сведения о хранении на складе), а затем создать только нужные строки - для продуктов, имеющихся в наличии на складе. Эти данные будут ссылаться на основную таблицу. На самом деле все гораздо проще, чем может показаться из этого объяснения. Окончательный проект первого варианта нашей базы данных, с которым мы будем работать далее, представлен на рис. 2.19:
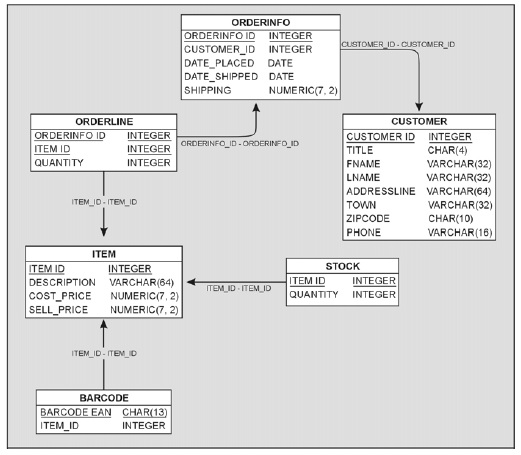
Рис. 2.19. Добавление в базу данных таблицы stock
Обратите внимание , что в таблице stock в качестве уникального ключа выступает item_id, а хранящаяся в ней информация связана непосредственно с товарами, при этом для выполнения соединения с соответ-
ствующим товаром в таблице item используется item_id. Стрелка указывает на таблицу item, потому что это главная таблица, хотя в данном случае и нет отношения «многие-к-одному».
В таком виде схема кажется явно запутанной, ведь хранимой нами дополнительной информации очень мало. Но оставим все как есть для того, чтобы показать, как это делается, а далее в книге расскажем, как получить доступ к данным в случае, если много информации содержится в дополнительных таблицах (таких, как данная). Для тех, кто любит заглядывать вперед, скажем, что будет использоваться «внешнее объединение».
Отметьте также, что названия некоторых столбцов на рисунке подчеркнуты, это означает, что данный столбец или комбинация столбцов (например, в таблице orderinfo) гарантированно уникальны. Они образуют первичный ключ таблицы.
