
Доступный в Интернете словарь Merriam-Webster определяет базу данных как большой набор данных, организованный специальным образом для обеспечения быстрого поиска и извлечения данных (например, с помощью компьютера).
Система управления базами данных (СУБД), как правило, представляет собой комплект библиотек, приложений и утилит, освобождающих разработчика приложения от груза забот, касающихся деталей хранения и управления данными. СУБД также предоставляет средства поиска и обновления записей.
За многие годы для решения различных видов проблем хранения данных было создано множество СУБД.
Типы баз данных
В 1960-70-х годах разрабатывались базы данных, которые тем или иным способом решали проблему повторяющихся групп. Эти методы привели к созданию моделей систем управления базами данных. Основой для таких моделей, используемых и по сей день, послужили исследования, проводимые в компании IBM.
Одним из основополагающих факторов проектирования ранних СУБД была эффективность. Гораздо легче манипулировать записями базы данных, имеющими фиксированную длину или, по крайней мере, фиксированное количество элементов в записи (столбцов в строке). Так удается избежать проблемы повторяющихся групп. Тот, кто программировал на каком-либо процедурном языке, без труда поймет, что в этом случае можно прочитать каждую запись базы данных в простую структуру C. Однако в реальной жизни такие удачные ситуации встречаются редко, поэтому программистам приходится обрабатывать не так удобно структурированные данные.
База данных с сетевой структурой
Сетевая модель вводит в базы данных указатели - записи, содержащие ссылки на другие записи. Так, можно хранить запись для каждого заказчика. Каждый заказчик в течение некоторого времени разместил у нас множество заказов. Данные расположены так, что запись заказчика содержит указатель ровно на одну запись заказа. Каждая запись заказа содержит как данные по этому конкретному заказу, так и указатель на другую запись заказа. Тогда в приложении-конвертере валют, которым мы занимались ранее, можно было бы использовать структуру, которая выглядела бы примерно так (рис. 1.):
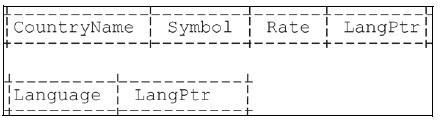
Рис. 1. Структура записей конвертера валют
Данные загружаются и получается связанный (отсюда и название модели – сетевая) список для языков (рис. 2):
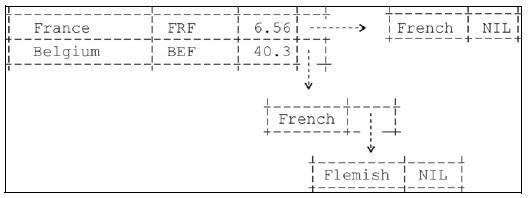
Рис. 2. Связанный список
Два разных типа записей, представленные на рисунке, будут храниться отдельно, каждый - в своей собственной таблице.
Конечно же, было бы более целесообразно, если бы названия языков не повторялись в базе снова и снова. Вероятно, лучше ввести третью таблицу, в которой содержались бы языки и идентификатор (часто в этом качестве используется целое число), который бы использовался для ссылки на запись таблицы языков из записей другого типа. Такой идентификатор называется ключом.
У сетевой модели базы данных есть несколько важных преимуществ. Если нужно найти все записи одного типа, относящиеся к определенной записи другого типа (например, языки, на которых говорят в одной из стран), то можно сделать это очень быстро, следуя по указателям, начиная с указанной записи.
Есть, однако, и недостатки. Если нам нужен перечень стран, в которых говорят по-французски, придется пройти по ссылкам всех записей стран, и для больших баз данных такая операция будет выполняться очень медленно. Это можно исправить, создав другие связанные списки указателей специально для языков, но такое решение быстро становится слишком сложным и, конечно же, не является универсальным, поскольку необходимо заранее решить, как будут организованы ссылки.
К тому же, писать приложение, использующее сетевую модель базы данных, достаточно утомительно, потому что обычно ответственность за создание и поддержание указателей по мере обновления и удаления записей лежит на приложении.
Иерархическая модель базы данных
В конце 1960-х годов IBM использовала в СУБД IMS иерархическую модель построения базы. В этой модели проблема повторяющихся групп решалась за счет представления одних записей как состоящих из множеств других.
Это можно представить как «спецификацию материалов», которая применяется для описания составляющих сложного продукта. Например, машина состоит (скажем) из шасси, кузова, двигателя и четырех колес. Каждый из этих основных компонентов в свою очередь состоит из некоторых других. Двигатель включает в себя несколько цилиндров, головку цилиндра и коленчатый вал. Эти компоненты опять-таки состоят из более мелких; так мы доходим до гаек и болтов, которыми комплектуются любые составляющие автомобиля.
Иерархическая модель базы данных применяется до сих пор. Иерархическая СУБД способна оптимизировать хранение данных в том, что касается некоторых отдельных вопросов, например можно без труда определить, в каком автомобиле используется какая-то конкретная деталь.
Реляционная модель базы данных
Огромный скачок в развитии теории систем управления базами данных произошел в 1970 году, когда был опубликован доклад Е. Ф. Код- да (E. F. Codd) «Реляционная модель для больших разделяемых банков данных» («A Relational Model of Data for Large Shared Data Banks»), см. эту ссылку. В этом поистине революционном труде вводилось понятие отношений и было показано, как использовать таблицы для представления фактов, которые устанавливают отношения с объектами «реального мира» и, следовательно, хранят данные о них.
К этому времени уже стало очевидно, что эффективность, достижение которой первоначально являлось основополагающим при проектировании базы, не так важна, как целостность данных. Реляционная модель придает гораздо большее значение целостности данных, чем любая другая ранее применявшаяся модель.
Реляционную систему управления базами данных определяет набор правил. Во-первых, запись таблицы носит название «кортеж», и именно этот термин используется в части документации на PostgreSQL. Кортеж - это упорядоченная группа компонентов (или атрибутов), каждый из которых принадлежит определенному типу. Все кортежи построены по одному шаблону, во всех одинаковое количество компонентов одинаковых типов. Приведем пример набора кортежей:
{"France", "FRF", 6.56}
{"Belgium", "BEF", 40.1}Каждый из этих кортежей состоит из трех атрибутов: названия страны (строковый тип), валюты (строковый тип) и валютного курса (тип с плавающей точкой). В реляционной базе данных все записи, добавляемые в это множество (или таблицу), должны следовать этой же форме, поэтому записи, представленные ниже, не могут быть добавлены:
Более того, ни в одной таблице не может быть повторения кортежей. То есть в любой таблице реляционной базы данных повторяющиеся строки или записи не разрешены.
Такая мера может выглядеть как драконовская, поскольку может показаться, что для системы, которая хранит заказы, размещаемые клиентами, это означает, что один клиент не сможет заказать какой-то продукт дважды.
Каждый атрибут записи должен быть «атомарным», то есть представлять собой простую порцию информации, а не другую запись или список других аргументов. Кроме того, типы соответствующих атрибутов в каждой записи должны совпадать, как было показано выше. Технически это означает, что они должны быть получены из одного и того же набора значений или домена. Практически же все они должны быть или строками, или целыми числами, или числами с плавающей точкой, или же принадлежать какому-то другому типу, поддерживаему СУБД.
Атрибут, по которому отличают записи, во всем остальном идентичные, называется ключом. В некоторых случаях в качестве ключа может выступать комбинация из нескольких атрибутов.
Атрибут (или атрибуты), предназначенный для того, чтобы отличить некоторую запись таблицы от всех остальных записей этой таблицы (или, другими словами, сделать запись уникальной), называется первичным ключом. В реляционной базе данных каждое отношение (таблица) должно иметь первичный ключ, то есть что-то, что делало бы каждую запись отличной от всех остальных в этой таблице.
Последнее правило, определяющее структуру реляционной базы данных, - это ссылочная целостность. Такое требование объясняется тем, что в любой момент времени все записи базы данных должны иметь смысл. Разработчик приложения, взаимодействующего с базой данных, должен быть внимателен, он обязан убедиться, что его код не нарушает целостности базы. Представьте, что происходит при удалении клиента. Если клиент удаляется из отношения CUSTOMER, необходимо удалить и все его заказы из таблицы ORDERS. В противном случае останутся записи о заказах, которым не сопоставлен клиент.
В следующих моих блогах будет представлена более подробная теоретическая и практическая информация о реляционных базах данных. Пока же запомните, что реляционная модель построена на таких математических понятиях, как множества и отношения, и что при создании систем следует придерживаться определенных правил.

Языки запросов SQL и друие
Реляционные системы управления базами данных, конечно же, предоставляют способы добавления и обновления данных, но это не главное, сила таких систем заключается в том, что они предоставляют пользователю возможность задавать вопросы о хранимых данных на специальном языке запросов. В отличие от более ранних баз данных, которые специально проектировались так, чтобы отвечать на определенные типы вопросов, касающихся содержащейся в них информации, реляционные базы данных являются гораздо более гибкими и отвечают на вопросы, которые еще не были известны при создании базы.
Предложенная Коддом реляционная модель использует тот факт, что отношения определяют множества, а множества можно обрабатывать математически. Кодд предположил, что в запросах мог бы применяться такой раздел теоретической логики, как исчисление предикатов, на его основе и построены языки запросов. Такой подход обеспечивает беспрецедентную производительность поиска и выборки множеств данных.
Одним из первых был реализован язык запросов QUEL, он использовался в созданной в конце 1970х годов базе данных Ingres. Еще один язык запросов, в котором применялся другой метод, назывался QBE (Query By Example - запрос по примеру). Приблизительно в то же самое время группа, работающая в исследовательском центре IBM, разработала язык структурированных запросов SQL (Structured Query Language), это название обычно произносится как «сиквел».
SQL - это стандартный язык запросов, наиболее распространенным его определением является стандарт ISO/IEC 9075:1992, «Information Technology — Database Languages — SQL» (или, проще говоря, SQL92) и его американский аналог ANSI X3.135-1992, отличающийся от первого лишь несколькими страницами обложки. Эти стандарты заменили ранее существовавший SQL89. На самом деле есть и более поздний стандарт, SQL99, но он еще не получил распространения, к тому же большая часть обновлений не затрагивает ядро языка SQL.
Существуют три уровня соответствия SQL92: Entry SQL, Intermediate SQL и Full SQL. Самым распространенным является уровень «Entry», и PostgreSQL очень близок к такому соответствию, хотя есть и небольшие различия. Разработчики занимаются исправлением незначительных упущений, и с каждой новой версией PostgreSQL становится все ближе к стандарту.
В языке SQL три типа команд:
- Data Manipulation Language (DML) — язык манипулирования данными. Это та часть SQL, которая используется в 90% случаев. Она состоит из команд добавления, удаления, обновления и, что важнее всего, выборки данных из базы данных.
- Data Definition Language (DDL) — язык определения данных. Это команды для создания таблиц и управления другими аспектами базы данных, структурированными на более высоком уровне, чем относящиеся к ним данные.
- Data Control Language (DCL) — язык управления данными
Это набор команд, контролирующих права доступа к данным. Многие пользователи баз данных никогда не применяют такие команды, поскольку работают в больших компаниях, где есть специальный администратор базы данных (или даже несколько), который занимается управлением базой данных, в его функции входит и контроль за правами доступа.
SQL
SQL практически повсеместно признан стандартным языком запросов и, как уже упоминалось, описан во многих международных стандартах. В наши дни почти каждая СУБД в той или иной степени поддерживает SQL. Это способствует унификации, т. к. приложение, написанное с применением SQL в качестве интерфейса к базе данных, может быть перенесено и использоваться на другой базе, при этом стоимость такого переноса в терминах затраченного времени и прилагаемых усилий будет невелика.
Однако под давлением рынка производители баз данных вынуждены создавать отличающиеся друг от друга продукты. Так появилось несколько диалектов SQL, чему способствовало и то, что в стандарте, описывающем язык, не определены команды для многих задач администрирования базы данных, которые представляют собой необходимую и очень важную составляющую при использовании базы в реальном мире. Поэтому существуют различия между диалектами SQL, принятыми (например) в Oracle, SQL Server и PostgreSQL.
SQL будет описываться на протяжении всей книги, пока же приведем несколько примеров, чтобы показать, на что этот язык похож. Оказывается, для того чтобы начать работать с SQL, не обязательно изучать его формальные правила.
Создадим при помощи SQL новую таблицу в базе данных. В этом примере создается таблица для товаров, предлагаемых на продажу, которые войдут в заказ:
CREATE TABLE item
(
item_id serial,
description char(64) not null,
cost_price numeric(7,2),
sell_price numeric(7,2)
);Здесь мы определили, что таблице необходим идентификатор, который бы действовал как первичный ключ, и что он должен автоматически генерироваться системой управления базой данных. Идентификатор имеет тип serial, а это означает, что каждый раз при добавлении нового элемента item в последовательности будет создан новый, уникальный item_id. Описание (description) - это текстовый атрибут, состоящий из 64 символов. Себестоимость (cost_price) и цена продажи (sell_price) определяются как числа с плавающей точкой, с двумя знаками после запятой.
Теперь используем SQL для заполнения только что созданной таблицы. В этом нет ничего сложного:
INSERT INTO item(description, cost_price, sell_price)
values('Fan Small', 9.23, 15.75);
INSERT INTO item(description, cost_price, sell_price)
values('Fan Large', 13.36, 19.95);
INSERT INTO item(description, cost_price, sell_price)
values('Toothbrush', 0.75, 1.45);Основа SQL - это оператор SELECT. Он применяется для создания результирующих множеств - групп записей (или атрибутов записей), которые соответствуют некоторому критерию. Эти критерии могут быть достаточно сложными. Результирующие множества могут использоваться в качестве целевых объектов для изменений, осуществляемых оператором UPDATE, или удалений, выполняемых DELETE.
Вот несколько примеров использования оператора SELECT:
SELECT * FROM customer, orderinfo
WHERE orderinfo.customer_id = customer.customer_id GROUP BY customer_id
SELECT customer.title, customer.fname, customer.lname,
COUNT(orderinfo.orderinfo_id) AS "Number of orders" FROM customer, orderinfo
WHERE customer.customer_id = orderinfo.customer_id
GROUP BY customer.title, customer.fname, customer.lnameЭти операторы SELECT перечисляют все заказы клиентов в указанном порядке и подсчитывают количество заказов, сделанных каждым клиентом.
Например, база данных PostgreSQL предоставляет несколько способов доступа к данным, в частности можно:
- Использовать консольное приложение для выполнения операторов SQL
- Непосредственно встроить SQL в приложение
- Использовать вызовы функций API (Application Programming Interfaces, интерфейсов прикладного программирования) для подготовки и выполнения операторов SQL, просмотра результирующих множеств и обновления данных из множества различных языков программирования
- Прибегнуть к опосредованному доступу к данным базы PostgreSQL с применением драйвера ODBC (Open Database Connection - открытого интерфейса доступа к базам данных) или JDBC (Java Database Connectivity - интерфейса доступа Java-приложений к базам данных) или стандартной библиотеки, такой как DBI для языка Perl
Системы управления базами данных
СУБД, как уже говорилось ранее, - это набор программ, делающих возможным построение баз данных и их использование. В обязанности СУБД входит:
- Создание базы данных. Некоторые системы управляют одним большим файлом и создают одну или несколько баз данных внутри него, другие могут задействовать несколько файлов операционной системы или же непосредственно реализовывать низкоуровневый доступ к разделам диска. Пользователи и разработчики не должны заботиться о низкоуровневой структуре таких файлов, т. к. весь необходимый доступ обеспечивает СУБД.
- Предоставление средств для выполнения запросов и обновлений. СУБД должна обеспечивать возможность запроса данных, удовлетворяющих некоторому критерию, например возможность выбора всех заказов, сделанных некоторым клиентом, но еще не доставленных. До того как SQL получил широкое распространение в качестве стандартного языка, способы выражения таких запросов менялись от системы к системе.
- Многозадачность. Если с базой данных работают несколько приложений или к ней одновременно осуществляют доступ несколько пользователей, то СУБД должна гарантировать, что обработка запроса каждого пользователя не влияет на работу остальных. То есть пользователям приходится ждать, только если кто-то другой записывает данные именно тогда, когда им нужно прочитать (или записать) данные в какой-то элемент. Одновременно может происходить несколько считываний данных. На поверку оказывается, что разные базы данных поддерживают разные уровни многозадачности и что эти уровни даже могут быть настраиваемыми.
- Ведение журнала. СУБД должна вести журнал всех изменений данных за некоторый период времени. Он может использоваться для отслеживания ошибок, а также (может быть, это даже важнее) для восстановления данных в случае сбоя системы, например внепланового выключения питания. Обычно производится резервное копирование данных и ведется журнал транзакций, т. к. резервная копия может быть полезна для восстановления базы данных в случае повреждения диска.
- Обеспечение безопасности базы данных. СУБД должна обеспечивать контроль над доступом, чтобы только зарегистрированные пользователи могли манипулировать данными, хранящимися в базе, и самой структурой базы данных (атрибутами, таблицами и индексами). Обычно для каждой базы определяется иерархия пользователей, во главе этой структуры стоит «суперпользователь», который может изменять все что угодно, дальше идут пользователи, которые могут добавлять и удалять данные, а в самом низу находятся те, кто имеет право только на чтение. СУБД должна иметь средства, позволяющие добавлять и удалять пользователей, а также указывать, к каким возможностям базы данных они могут получить доступ.
- Поддержание ссылочной целостности. Многие СУБД имеют свойства, способствующие поддержанию ссылочной целостности, то есть корректности данных. Обычно, если запрос или обновление нарушает правила реляционной модели, СУБД выдает сообщение об ошибке.

