 В предыдущей статье мы обсудили традиционные модели данных, такие как иерархическая, сетевая, реляционная. Обсудили их структуру, организацию, а также указали на их преимущества и недостатки. Но существуют и другие, менее распространенные, но набирающие популярность модели. Их мы и обсудим в данной статье.
В предыдущей статье мы обсудили традиционные модели данных, такие как иерархическая, сетевая, реляционная. Обсудили их структуру, организацию, а также указали на их преимущества и недостатки. Но существуют и другие, менее распространенные, но набирающие популярность модели. Их мы и обсудим в данной статье.
Модель «Сущность-атрибут-значение» (EAV)
В англоязычной терминологии модель САЗ (Сущность-Атрибут-Значение) носит название EAV (Entity-Atribute-Value). В русскоязычном сообществе разработчиков приложений баз данных подход обсуждался в 1990-х годах как «вертикальное хранение атрибутов», в противовес реляционной модели, где атрибуты располагаются горизонтально.
Суть подхода состоит в максимальном упрощении структуры хранения данных, что обеспечивает высокую гибкость изменения логической схемы данных. Вертикальное хранилище атрибутов представляет собой похожую на таблицу структуру, состоящую из трёх столбцов:
- столбец «Сущность». Содержит уникальный идентификатор сущности. Также может представлять собой пару (идентификатор, временная метка) для отражения хронологии событий и фактов;
- столбец «Атрибут». Название свойства сущности, как правило — ссылка (короткий идентификатор) на таблицу атрибутов в метаданных;
- столбец «Значение». Непосредственно значение атрибута.
Использование реляционной терминологии «таблица» и «столбец» для описания модели САЗ вызвана, во-первых, стереотипом наиболее понятным для большинства разработчиков, во-вторых, тем фактом, что вертикальное хранение в большинстве известных автору случаев было реализовано средствами реляционной СУБД.
На самом деле не столь важно, сгруппированы ли тройки САЗ в длинную таблицу, или же речь идёт о записях, объединённых в двунаправленный список. Все они суть способы представления разреженной матрицы САЗ, столбцы которой представляют собой все определённые в системе атрибуты, строки — все имеющиеся сущности, а на пересечении строки и столбца находится соответствующее значение, если оно имеется.
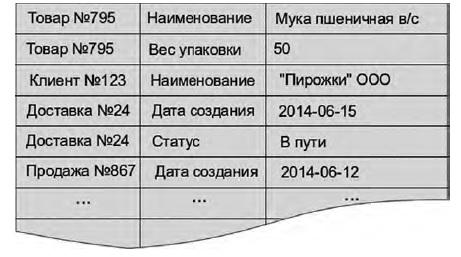
Рис. 1. Представление САЗ в виде таблицы
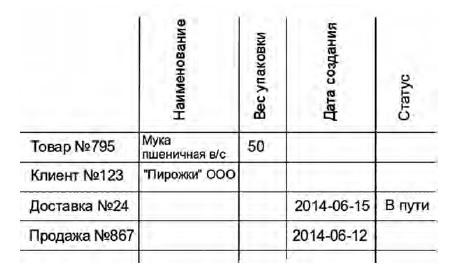
Рис. 2. Матрица САЗ является разреженной
Немного углубясь в историю, можно обнаружить гораздо более древний и широко известный в классическом программировании подход ассоциативных массивов, состоящих из пар «ключ-значение». Этот путь прямиком приводит нас в 1960-е годы к языку Лисп. Базы данных, использующие такой поход, применялись ещё до эпохи массового распространения реляционных СУБД. Только и разница, что теперь вместо простого ключа используется составной. Записывали раньше в массив пару («Товар№795/Наименование», «Мука пшеничная в/с»), теперь же ключом ассоциативного списка становится пара атрибутов, а в программе оперируем уже тройками.
Развивая подход, получаем современные многомерные кубы, где ключом является набор величин, а значением — некоторая агрегированная величина.
Обратимся к практической стороне использования модели. САЗ даёт возможность менять логическую схему данных, что называется, «на лету». Действительно, достаточно добавить в метаданные описание нового атрибута и связать его с типами сущностей, как все приложения могут считывать и записывать значения данного атрибута, не принимая во внимание структурные изменения. Для сравнения, в реляционной БД добавление колонки в таблицу вызовет изменение структуры соответствующих наборов данных на стороне приложения по горизонтали, в противном случае колонка останется невидимой.
Интересную возможность представляют запросы по значениям атрибутов вне учёта сущностей. Например, следующий простой запрос выведет нам все сущности, у которых, во-первых, имеется атрибут «вес», а, во-вторых, этот вес находится в заданных рамках.
SELECT *
FROM eav
WHERE attribite = ’Вес’ AND value BETWEEN 10 AND 50В рамках корпоративной БД, в результатах такого запроса можно будет обнаружить не только упакованные товары, но и разнообразные весовые коэффициенты, отгрузки, приёмки, характеристики сотрудников, параметры оборудования, рецептуры технологий и многое другое. Неплохой инструмент для исследования семантики.
Однако, такие запросы без учёта контекста, например, типа сущности, достаточно редки. Для отображения связей приходится вводить специальные атрибуты, ссылочная целостность по значениям которых без типизации сущностей не реализуется в принципе, а при наличии типизации реализуется с высокими накладными расходами.
Расширенная модель САЗ носит название EAV/CR (EAV with classes and relationships), то есть САЗ с классами (типами) и связями. В дальнейшем будем называть её РСАЗ.
РСАЗ явным образом поддерживает для каждой сущности понятие класса (типа). Это означает, что запросы теперь можно ограничивать только сущностями заданного типа, чтобы избежать приведённой выше неоднозначности выборки по значениям атрибутов.
Связи между сущностями также поддерживаются в явном виде, кроме того структура, задающая связи, подлежит унификации.
Ограничения целостности могут быть описаны на уровне метаданных, но способ их реализации не оговорён. Например, в реляционной БД таким механизмом могут являться триггеры таблиц метаданных.
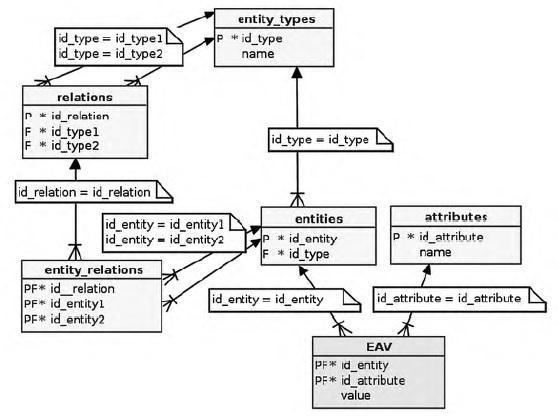
Рис. 3. Пример реализации расширенной модели САЗ
Запросы, относящиеся к категории CRUD[1], также не представляют особенных трудностей, за исключением необходимости транспонировать результат в табличную форму. В рамках реализующего САЗ реляционного подхода такие макрозапросы состоят из большого числа мелких подзапросов в соответствии с числом выводимых колонок-атрибутов.
SELECT
(SELECT value FROM eav
WHERE entity = 'Товар795'
AND attribute = ’Наименование’
) AS "Наименование",
(SELECT value FROM eav
WHERE entity = 'Товар795'
AND attribute = ’Вес упаковки’
) AS "Вес упаковки"Для сравнения, запрос в рамках реляционной БД выглядит куда более лаконичным.
SELECT name AS "Наименование", weight AS "Вес упаковки"
FROM goods
WHERE name = ’Товар795’Наибольшую сложность представляют собой запросы ad hoc («по месту», в контексте СУБД — произвольные запросы пользователей), запросы с агрегацией и запросы с большим числом связей между сущностями. Текст становится неудобочитаемым, а эффективность выполнения реляционной СУБД вызывает сомнения без дополнительной оптимизации физического хранения и прямых подсказок оптимизатору со стороны программиста.
Следующий запрос выводит все номера доставленных заказов, в которых имеется товар «Мука пшеничная в/с», и его вес превышает 100 кг.
SELECT num AS "Номер заказа",
SUM(amount) AS "Количество"
FROM
(SELECT orders.value AS num, order items2.value AS amount
FROM eav orders
INNER JOIN entities el
ON orders.id entity = el.id entity
INNER JOIN entity types etl
ON el.id type = etl.id type
INNER JOIN attributes al
ON al.id attribute = orders.id attribute
INNER JOIN eav orders2
ON orders.id entity = orders2.id entity
INNER JOIN attributes a2
ON a2.id attribute = orders2.id attribute
INNER JOIN entity relations er
ON er.id entity1 = orders.id entity
INNER JOIN eav order items
ON er.id entity2 = order items.id entity
INNER JOIN entities e3
ON order items.id entity = e3.id entity
INNER JOIN entity types et3
ON e3.id type = et3.id type
INNER JOIN attributes a3
ON a3.id attribute = order items.id attribute
INNER JOIN eav order items2
ON order items2.id entity = order items.id entity
INNER JOIN attributes a4
ON a4.id attribute = order items2.id attribute
WHERE et1.name = ’Заказ’ AND a1.name = ’Номер’ AND
a2.name = ’Статус’ AND
a2.value = ’Доставлен’ et3.name = ’Предмет заказа’ AND
a3.name = ’Название’ AND a3.value = ’Мука пшеничная в/с’ a4.name = ’Вес’ AND
a4.value > 100 AND ) AS selected orders
GROUP BY numНесмотря на относительную простоту первоначального запроса, при реализации РСАЗ в рамках реляционной БД необходимо определить целых 12 соединений!
Снова приведём для сравнения запрос к таблицам реляционной СУБД.
SELECT o.num AS "Номер",
SUM(oi.amount) AS "Количество"
FROM orders o
INNER JOIN order_items oi ON o.id = oi.id_order
WHERE o.state = 'Доставлен'
AND oi.name = 'Мука'
AND oi.amount > 100
GROUP BY o.numВ структуре запроса к РСАЗ можно выделить шаблонные конструкции, необходимые для фильтрации по типу сущности и названию атрибута. Если ввести поверх SQL надстройку над языком в виде макроопределений или даже просто определить соответствующие виды, то число соединений можно сократить, увеличив наглядность кода.
CREATE VIEW eav_t
AS
SELECT eav.id_entity,
e.id_type,
et.name AS type_name,
eav.id_attribute,
a.name AS attr_name,
eav.value
FROM eav
INNER JOIN entities e ON eav.id_entity = e.id_entity
INNER JOIN entity_types et1 ON e.id_type = et.id_type
INNER JOIN attributes a ON a.id_attribute =
eav.id_attributeТеперь наш запрос примет более удобочитаемый вид.
SELECT num AS "Номер заказа",
SUM(amount) AS "Количество"
FROM
(SELECT orders.value AS num, order_items2.value AS amount
FROM eav_t orders
INNER JOIN eav_t orders2
ON orders.id_entity = orders2.id_entity
INNER JOIN entity_relations er
ON er.id_entity1 = orders.id_entity
INNER JOIN eav_t order_items
ON er.id_entity2 = order_items.id_entity
INNER JOIN eav_t order_items2
ON order_items2.id_entity = order_items.id_entity
WHERE orders.type_name = 'Заказ' AND
orders.attr_name = 'Номер' AND
orders2.attr_name = 'Статус' AND
orders2.value = 'Доставлен'
order_items.type_name = 'Предмет заказа' AND
order_items.attr_name = 'Название' AND
order_items.value = 'Мука пшеничная в/с'
order_items2.attr_name = 'Вес' AND
order_items2.value > 100 AND
) AS selected_orders
GROUP BY numСледует понимать, что несмотря на некоторое упрощение текста запроса и явное задание четырёх соединений вместо двенадцати, оптимизатор реляционной СУБД все равно будет вынужден оперировать двенадцатью соединениями.
Другой важный аспект — «волшебный» тип колонки «Значение». Все наши предыдущие примеры неявно предполагали некий аналог универсального типа Variant, который может хранить разнообразные величины.
На практике реляционные СУБД такой тип не поддерживают, нет его и в стандарте SQL. Поэтому используются различные собственные реализации «универсального» типа данных для колонки «Значение»:
- строковый или бинарный тип с конвертацией в другие типы данных. Недостатком является более низкое быстродействие по сравнению с хранением в формате встроенных типов СУБД;
- несколько колонок разного типа, например «Значение-строка», «Значение-целое», «Значение-дата» и т. д. Конвертация данных не требуется, но манипуляции с чтением-записью значений в зависимости от типа атрибута усложняют запросы, необходимо наращивать язык с помощью тех же видов или хранимых процедур. Другой недостаток — разрежённость хранения, ведь если определить 5 колонок для значений разного типа, то только одно значение в каждой строке будет использовано. Некоторые СУБД, например, SQL Server 2008 и выше предлагают оптимизированное хранение для таких разреженных колонок (подробнее см. sparse columns);
- отдельные таблицы, содержащие значения только заданного типа, связанные с основной eav по короткому уникальному идентификатору. Недостаток — необходимость дополнительных соединений, в том числе внешних (LEFT JOIN вместо INNER JOIN);
- смешанные подходы, например, создание отдельных таблиц только для хранения длинных текстовых и бинарных значений атрибутов.
Модель САЗ: плюсы и минусы
Преимуществами модели САЗ являются:
- гибкость схемы данных и возможность её изменения в динамике;
- высокая степень унификации и повторного использования структур хранения;
- возможность выполнения контекстно-независимых запросов, например, не принимающих в расчёт тип сущностей;
- возможность реализации на основе реляционной СУБД;
- относительно простая базовая концепция.
К недостаткам следует отнести:
- сложность манипуляций данными вне CRUD-запросов;
- как следствие, необходимость вводить собственный язык манипуляции данными;
- в случае реализации на основе реляционной СУБД, более низкая производительность за счёт большего числа соединений в запросах;
- как следствие, необходимость оптимизации физического хранения и прямых подсказок оптимизатору со стороны программиста, что снижает масштабируемость по мере роста объёма данных.
Несмотря на свою гибкость, модель САЗ имеет ряд недостатков, а рекомендовать её реализацию на основе реляционной СУБД можно лишь в отдельных случаях. Также модель не слишком хорошо подходит в ситуации схем с большим количеством связей между сущностями и жёсткими ограничениями ссылочной целостности.
В наиболее дружественном для программиста и пользователя варианте, это должна быть полноценная СУБД, реализующая модель САЗ на физическом уровне и предоставляющая разработчику готовый входной язык определения структур и манипуляции данными, а не надстройка над реляционной СУБД.
Неполно структурированные модели данных
К неполно структурированным моделям данных (НСМД, в англоязычной терминологии semi-structured data models) относятся те способы их организации, в которых схема и данные не разделены. Обратите внимание, схема не «зашита» в данные, подобно встроенной DTD в XML- файле, а отсутствует в явном виде, при этом данные остаются структурированными.
В русскоязычной среде нередко используется термин-калька «полуструктурированные данные», не отражающий, на мой взгляд, суть. Степень структурности можно оценить, она варьируется, поэтому данные не могут быть всегда структурированы только наполовину. Другой термин «слабоструктурированные» также не соответствует смыслу. Данные могут быть структурированы «сильно», но при этом все-таки неполно.
Тем не менее, если вы встречаете упоминание о полу- или слабо структурированных данных, то, скорее всего, речь пойдёт о НСМД.
В рамках статьи будет использован термин «неполно структурированные данные» (НСД).
Например, в реляционной БД известно, что в определённой таблице в каждой строке всегда имеется столько значений, сколько определено колонок. Сами значения в каждом поле строки соответствуют типам колонок. Мы не можем добавить дополнительное значение в отдельные строки, не определив новых колонок для всей таблицы.
В случаях, когда исходные данные неполно структурированы, а возможности по их анализу и классификации ограничены, такой подход может оказаться препятствием на пути первичного сбора информации, вынуждая переходить, например, к модели САЗ без всяких ограничений со стороны метаданных.
Другая область применения — обмен информацией в гетерогенной среде. Объект в одной системе может быть упакован (сериализован) в какой-либо из форматов НСМД, затем передан другой системе, которая на базе полученного описания и данных создаст соответствующий объект в своей среде. Согласование схем в данном случае не требуется, хотя для эффективности обработки и лучшей переносимости такие схемы часто формализуют и даже стандартизируют на отраслевом уровне.
Поскольку в НСМД данные остаются структурированными, они могут быть проанализированы и интерпретированы непосредственно в ходе обработки. Таковым, например, является XML, не имеющий ограничений XML-схемы или DTD. Любой разборщик XML позволяет работать с таким нестрогим документом посредством навигации по иерархии тегов и спискам атрибутов.
Например, если интерпретатор умеет выделять в документе информацию по заказам внутри иерархии <order>/<number> независимо от её уровня вложения, то он справится с задачей в обоих приведённых ниже случаях.
<!-- Случай 1. Заказы списком -->
<orders>
<order>
<number>123</number>
<items />
</order>
</orders>
...
<!-- Случай 2. Заказы в составе продаж -->
<sales>
<sale>
<order>
<number>123</number>
</order>
</sale>
</sales>Другим широко распространенным подходом НСМД является JSON (JavaScript Object Notation). По сравнению с XML «без схем», JSON представляет собой менее удобный для восприятия человеком формат. Однако, он более прост для обработки анализаторами и может быть более экономичным по объёму за счёт отсутствия замыкающих тегов.
Как и XML, JSON также может иметь схему данных, содержащую информацию о типах элементов и порядке их следования в документе. Ниже — пример сохранения данных в JSON-документе.
{
"номер_заказа": "123-45",
"дата": "2014-02-15",
"состояние": "выполнен",
"адрес_доставки": {
"улица": "Ивановский пр. 5",
"город": "Крыжополь",
"индекс": "333222"
},
"телефоны": [
{ "тип": "домашний", "номер": "921-1112233" },
{ "тип": "мобильный", "номер": "921-1114455" }
]
}Подходы НСМД тесно связаны с обширной темой самодокументированных данных и понятием «семантический веб» (semantic web). Согласно этой концепции, информация передаётся между системами в НСМД, при этом структура считается самодостаточной для распознавания и интерпретации смысловых и контекстных связей в документе без предварительного согласования схем данных для обмена.
Документ-ориентированная модель и NoSQL
Документ-ориентированная модель (ДОМ, не путайте с DOM — Document Object Model, объектной моделью документа, используемой при разборе XML) носит такое название, потому что основным её элементом является документ. В отсутствии строгого определения, это понятие соответствует иерархическим XML, JSON-документам и подобным структурам.
Документы организованы в линейные списки — коллекции, которые могут содержать другие коллекции. Таким образом, ДОМ представляет собой синтез иерархической и неполно-структурированной моделей данных.
В отличие от реляционной модели, где каждая строка таблицы имеет строго оговорённое число полей, определяемых заданными колонками и их типами, или от канонической иерархической модели, где каждый сегмент содержит список записей одного типа, документы списка в ДОМ могут иметь структуру с общей и различающимися частями.
Эта возможность позволяет относительно просто расширять структуру хранимой в БД информации. Для аналогичных расширений в реляционной модели приходится создавать таблицы расширений, связанные отношением «один-к-одному» с главной таблицей. Такое расширение в случае иерархии таблиц является выделением подтипов (sub-typing). В случае множественного подчинения речь идёт об агрегации.
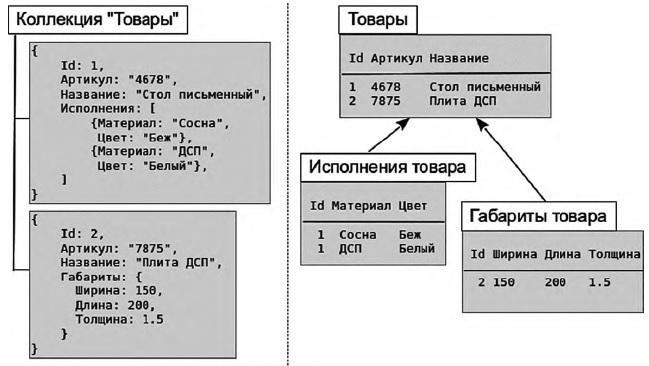
Рис. 4. Расширение структур в документ-ориентированной и реляционной моделях
СУБД, реализующие документ-ориентированную модель, получили название NoSQL, явно обозначающий их отличие от реляционных подходов. В дальнейшем термин NoSQL «лёгким движением руки» превратился в аббревиатуру, которая расшифровывалась уже как Not Only SQL (не только SQL), став обозначением для семейства нереляционных СУБД, созданных преимущественно в последнее десятилетие и в большинстве своём под свободными лицензиями с открытым исходным кодом: Cassandra, CouchDB, MongoDB и многие другие.
Из главы про модель САЗ (нерасширенную) на примере запроса по сущностям, имеющим атрибут «Вес», мы знаем, что отсутствие схемы данных может иметь побочные последствия.
Аналогичным образом этот принцип действует и в ДОМ. Нет схемы — нет однозначной интерпретации элементов данных. Чтобы избавиться от подобных побочных эффектов и уметь отличать вес упакованного товара от веса гружёного контейнера, необходимо вводить схемы данных. И тогда ДОМ превращается в обычную иерархическую модель.
Слабым звеном NoSQL является, как это следует из названия, отсутствие стандартизованного декларативного языка запросов, коим является SQL. Иллюстрация ниже показывает, как переписать SQL-запрос на последовательность команд входного языка MongoDB.
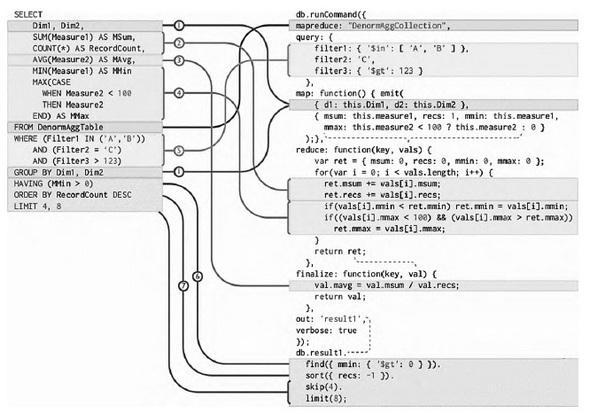
Рис. 5. Сравнение текстов запросов MySQL и MongoDB
Пояснения к трансформации:
- Функции агрегации в MongoDB программируются вручную с использованием механизма map-reduce. Колонки измерений вынесены в map.
- Непосредственная реализация функций агрегации над величинами (мерами).
- Агрегации, зависящие от числа обработанных записей, должны ждать завершения основной функции.
- Внутри можно использовать обычную процедурную логику, например, условные переходы.
- Выражения фильтров записываются в близком к ORM стиле.
- Фильтры уровня агрегации должны быть применены к результату map-reduce.
- Восходящая сортировка кодируется единицей «1», нисходящая — «1».
Данная иллюстрация хорошо показывает, чем декларативный язык 4 поколения SQL, отличается от императивного, основанного на языке 3 поколения типа Ява-скрипт.
Для меня же интерпретация данной картинки представила интерес совсем по другой причине: по замыслу авторов подобное переписывание запроса представляет собой более привычный и простой (!) для программиста код...
Коллеги, осваивайте SQL. Всякий раз когда вам кажется, что SQL- запросы слишком трудны, обращайте свой взор на приведённую выше иллюстрацию и оценивайте, во сколько раз код NoSQL будет длиннее.
Ещё одну типичную ситуацию выпукло изобразили редакторы веб-сайта http://www.commitstrip.com. С их любезного разрешения ниже публикуется переведённая мной на русский язык история.
В целом говорить о каких-то новых возможностях NoSQL не приходится. Существует класс задач сбора, хранения и первичной обработки неполно структурированной информации, где продукты данного типа могут быть рассмотрены в качестве альтернативы реляционным СУБД, не имеющих соответствующих расширений для работы с XML или JSON. В остальных же случаях действует простое правило:

Рис. 6. Некомпетентность в SQL — не причина миграции на NoSQL.
Некомпетентность в SQL и реляционных СУБД не может служить серьёзным доводом в выборе NoSQL СУБД.
Многомерные модели данных
Центральным понятием модели является многомерный куб или гиперкуб. С привычным всем стереометрическим кубом сходство можно найти лишь при числе измерений, равном трём. Искать наглядные аналоги гиперкуба в геометрии трудно, а трёх измерений хватает разве что для самых простых аналитических выборок. Положим, например, что при оценке сбыта нужны всего 3 измерения: покупатель, период, товар. Значением узла куба по этим измерениям может быть сумма продаж или количество товара, если он отгружается в сравнимых единицах.
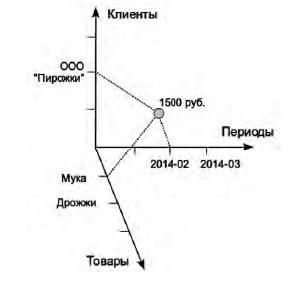
Рис. 7. Данные в ячейках гиперкуба трёхмерной модели
Гиперкуб по сути является многомерным разреженным массивом. Отличия от понятия массива, используемого в программировании незначительны:
- индексы измерений поименованы: вместо целых чисел 1, 2,...N используется их заданное соответствие. Например, 1 — «Мука в/с», 2 — «Дрожжи», 3 — «Сахар» и т. д. — это обычная кодификация;
- для доступа к значениям гиперкуба не обязательно специфицировать все индексы измерений.
Последний пункт требует пояснений. Чтобы получить значение элемента N-мерного массива, необходимо задать индексы по всем измерениям. Следующее выражение возвращает сумму продаж муки клиенту «ООО Пирожки» в марте 2014 года.
Сумма := Сбыт[Индекс("2014-02"), Индекс(”ООО Пирожки”),
Индекс("Мука")];что эквивалентно в нашем примере
Сумма := Сбыт[2, 2, 1];В многомерной модели это необязательно. Если индекс не специфицирован, то вычисляется заданная функция агрегации по всем значениям данного измерения. Например, следующее выражение вернёт сумму продаж любых товаров клиенту «ООО Пирожки» за март 2014 года.
Сумма := Сбыт[Индекс("2014-02"), Индекс("ООО Пирожки"), ?];Немаловажно, что в реализации многомерных моделей агрегаты предварительно вычисляются на этапе заполнения гиперкуба информацией, поэтому скорость выполнения следующих запросов будет примерно одинакова и составляет, как правило, миллисекунды.
Сумма := Сбыт[Индекс("2014-02"), Индекс("ООО Пирожки"),
Индекс("Мука")];
Сумма := Сбыт[?, Индекс("ООО Пирожки"), Индекс("Мука в/с")]; Сумма := Сбыт[?, Индекс("ООО Пирожки"), ?];В статьях нередко смешивают понятия интерактивной аналитической обработки OLAP и гиперкубов, называя последние OLAP-кубами. Такое смешение вызвано давними маркетинговыми причинами: СУБД компании Microsoft, реализующая многомерную модель, вначале носила название Microsoft OLAP.
Значение термина OLAP гораздо шире гиперкубов, поскольку сюда включены все методы интерактивной аналитической обработки данных: хранилища данных (data warehouse), так называемые витрины данных (data mart), добыча данных (data mining) и т. п. Часть перечисленных понятий может быть одновременно объектом пакетной обработки.
Применение многомерных моделей в транзакционной среде, чтобы одна и та же СУБД служила для обработки транзакций и аналитики, не представляет практического интереса по следующим причинам:
- максимальная детализация фактов и событий, необходимая в транзакционной обработке, увеличивает количество измерений, узлов и, соответственно, число предварительно вычисляемых агрегатов, что, в свою очередь, приводит к экспоненциальному росту физического размера БД;
- вставка, обновление и удаление записей приводит к пересчёту значений узлов и агрегатов, что резко увеличивает время и толщину транзакции.
Также следует упомянуть, что многомерная модель может быть реализована средствами реляционной СУБД путём надстраивания метаязыка и исполнительной среды для оперирования многомерными структурами. В этом случае гиперкуб представляется своими двумерными разрезами в виде иерархии таблиц согласно возможным сочетаниям из N измерений по k, где k лежит в диапазоне от 1 до N. Например, рассмотренный выше трёхмерный гиперкуб может храниться в следующей схеме.
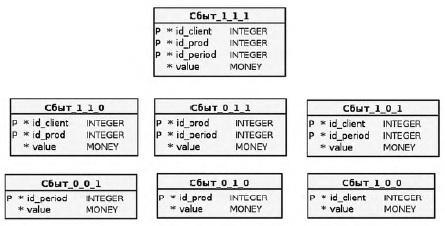
Рис. 8. Реляционная схема хранения трёхмерного гиперкуба
Подобная реализация также имеет название ROLAP (Relational OLAP) и поддерживается большинством систем аналитической обработки.
В общем случае, число необходимых таблиц Mtab для хранения N- мерного гиперкуба определяется как сумма всех возможных сочетаний из N по k, где k меняется от 0 до N.
![]()
В нашем примере при количестве измерений N=3 таблиц должно было быть 23=8, но для простоты исключена таблица с единственной строкой, не содержащая колонок-измерений. Соответствующую величину можно высчитать по наименее детализированной таблице (с одной колонкой- измерением).
Так как в общем случае для N измерений требуется 2N таблиц, их число растёт экспоненциально, поэтому на практике возможности ROLAP ограничиваются их небольшим (N < 10) количеством.
О применимости NoSQL
Как уже было сказано, NoSQL-решения и, в частности, основанные на ДОМ, имеют вполне конкретную область применения: первичный сбор и индексация информации, чью структуру мы не в состоянии классифицировать настолько полно, чтобы спроектировать соответствующую схему базы данных.
Если цель дальнейшей классификации и аналитической обработки собранной информации не ставится, то такую БД можно непосредственно эксплуатировать, используя, например, анализ семантических связей в «кипящей каше» из постоянно поступающих в систему документов. Собственно, исследовательские центры поисковых машин Интернета занимаются в том числе и такими вопросами.
Современные РСУБД, обладающие функциями хранения и обработки XML-документов, предоставляют проектировщику возможность гибридных решений, например, в условиях высокой нагрузки.
С другой стороны, есть класс задач, где исходная информация хорошо структурирована, но использование реляционной модели не является оптимальным. Речь идёт прежде всего о сущностях со сложной и многоуровневой иерархией вложения. Если хранить такие сущности в реляционной СУБД, то каждый тип должен быть в нормализованном виде отражён на десятки таблиц. Соответственно, обработка таких данных будет вызывать проблемы с производительностью, код запросов будет сложен и труден в сопровождении.
В таком случае также имеет смысл обратить внимание на нереляционные решения, но вовсе не на ДОМ-СУБД, а на поддерживающие многомерные и сетевые модели данных.
Приведём и другой тип труднореализуемой в рамках реляционной СУБД задачи. Пусть имеется множество однотипных объектов и связанных с каждым состояния, являющиеся длинным списком значений. Для простоты будем считать их двоичными: Состояние_1 = 0, Состояние_2 = 1, ... Состояние_К = 0. Число N может быть большим: сотни и тысячи состояний.
Упрощённый пример этого типа задач из практики: объектом является пользователи, а в качестве состояний выступают их ответы на длинную анкету из вопросов «да/нет». Другой вариант — пользователи и признаки посещения/непосещения страницы веб-сайта; в этом варианте можно сэкономить на объёме и хранить только посещения. Ещё пример — дискретные состояния системы в виде показания датчиков на заданные моменты времени.
В рамках реляционной модели построить собственно структуру для хранения данных не представляет труда.
Приведённая схема напоминает уже рассмотренную для хранения модели САЗ. Отличие пока количественное: в САЗ мы оперируем сущностями с единицами и десятками атрибутов, тогда как в данном примере — с сотнями и тысячами.
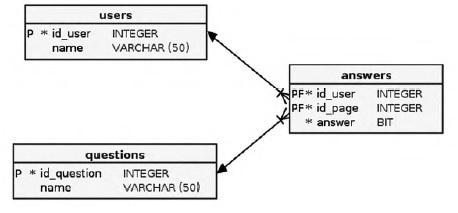
Рис. 9. Реляционная схема хранения множества бинарных состояний объекта
Количественное отличие быстро переходит в качественное, стоит лишь начать производить из БД простейшие выборки аналитического характера, например, «определить количество анкетированных, у которых ответ на Вопрос_1 - да, на Вопрос_3 — нет, на Вопрос_К — да и т.д». Число N будет однозначно определять число соединений в запросе. Для простоты считаем, что id_question соответствует его номеру.
Если N достаточно велико, то время выполнения такого запроса становится неприемлемым для интерактивной аналитической обработки, занимая долгие минуты. На практике, проблемы начинаются уже при N > 10..15, если таблица ответов содержит даже десятки миллионов строк[2], а план выполнения запроса представляет собой скопление вложенных циклов со внутренними хеш-слияниями промежуточных выборок.
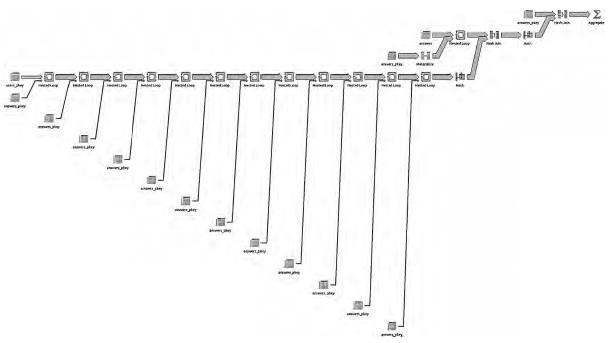
Рис. 10. План выполнения запроса в СУБД PostgreSQL при N = 15
Разумеется, средствами тонкой настройки и покупкой более мощной аппаратуры можно несколько увеличить производительность (более подробно об этом в следующих главах), но увеличив N добавлением ещё нескольких INNER JOIN мы, в лучшем случае, возвращаемся на исходные позиции.
Зная, что начиная с некоторого порога N время выполнения первого запроса будет расти линейно, можно переписать его в другом виде, без соединений, но с необходимостью всякий раз производить полное сканирование длинной таблицы ответов. Сканирование и промежуточное агрегирование на основе хеш-функций также негативно влияет на производительность, но время выполнения становится предсказуемым, хотя в случае N > 20..30 может вновь стать неприемлемым.
SELECT COUNT(1)
FROM
(SELECT id_user, COUNT(1)
FROM answers
WHERE id_question = 1 AND answer = 1
OR id_question = 2 AND answer = 0
...
OR id_question = N AND answer = 1
GROUP BY id_user
HAVING COUNT(1) = N -- соответствует числу вопросов в
запросе
) t
запросе ) tСоответствующий план будет примерно следующим, независимо от N.

Рис. 11. План выполнения запроса в СУБД PostgreSQL
При N порядка сотен, программист начинает сталкиваться с техническими ограничениями СУБД на число соединений в одном запросе и на общую длину текста запроса.
Как можно увидеть, даже в случае очень простых запросов проявляются трудности их реализации. Стоит несколько усложнить условия выборки, например «все пользователи, ответившие на вопросы NNN заданным образом, но по группе вопросов MMM совпадение не превышает 50%», как технические проблемы начинают расти в геометрической прогрессии.
Вариант решения с изменением начальной схемы путём денормализации и транспонирования таблицы ответов в структуру со многими колонками «Вопрос_1»,... «Вопрос_№> также не является возможным по техническим причинам: большинство реляционных СУБД имеет ограничения на число колонок в таблице или на общую длину строки (размер в байтах). Также будет невозможно построить индекс по всей совокупности колонок.
В таких ситуациях необходимо задумываться о нереляционных подходах к организации данных и, прежде всего, о СУБД, реализующие многомерные модели.
[1] CRUD — от англ. Create-Retreive-Update-Delete, типы множественных запросов на создание, считывание, модификацию или удаление единичного экземпляра сущности.
[2] Разумеется, приведённые значения N приблизительны, точные оценки зависят от многих факторов, прежде всего от производительности аппаратуры и конкретной СУБД. Для их получения необходимо производить нагрузочные тесты.
