
Наконец-то пришло время взглянуть на планы выполнения. Прежде чем мы начнем, вспомним изученные теоретические основы. В предыдущей статье объясняется, как логические операции сопоставляются с физическим исполнением, и рассказывается об извлечении данных и более сложных операциях.
Понимание этих алгоритмов позволит нам интерпретировать планы выполнения и лучше понять их компоненты.
Cобираем все вместе: как оптимизатор создает План выполнения
Результатом работы оптимизатора PostgreSQL является план выполнения. В то время как запрос определяет, что нужно сделать, план выполнения определяет, как выполнять операции SQL.
Задача оптимизатора - построить наилучший возможный физический план, реализующий определенный логический план. Это непростой процесс: иногда сложная логическая операция заменяется несколькими физическими операциями, или несколько логических операций объединяются в одну физическую.
Для построения плана оптимизатор использует правила преобразования, эвристики и алгоритмы оптимизации на основе стоимости. Правило преобразует план в другой план с меньшей стоимостью. Например, фильтрация и проекция уменьшают размер набора данных и, следовательно, должны выполняться как можно раньше; правило может переупорядочить операции, чтобы фильтрация и проекция выполнялись раньше. Алгоритм оптимизации выбирает план с самой низкой оценкой стоимости. Однако количество возможных планов (пространство планов) для запроса, содержащего несколько операций, огромно - оно слишком велико, чтобы алгоритм мог рассмотреть все возможные варианты. Ведь время, потраченное на выбор правильного алгоритма, добавляется к общему времени выполнения запроса. Эвристики используются для уменьшения количества планов, рассматриваемых оптимизатором.
Чтение Планов выполнения
Перефразируя Элвиса: поменьше абстракций, побольше действия. Мы уже готовы увидеть настоящие планы выполнения. Запрос из листинга 4.1 выбирает все рейсы, которые вылетели из аэропорта Джона Кеннеди (JFK) 14 августа 2020 г. и прибыли в аэропорт О'Хара (ORD). Для каждого рейса рассчитывается общее количество пассажиров.
Листинг 4.1 ❖ Запрос количества пассажиров на конкретных рейсах
SELECT f.flight_no,
f.actual_departure,
count(passenger_id) passengers
FROM flight f
JOIN booking_leg bl ON bl.flight_id = f.flight_id
JOIN passenger p ON p.booking_id=bl.booking_id
WHERE f.departure_airport = 'JFK'
AND f.arrival_airport = 'ORD'
AND f.actual_departure BETWEEN '2020-08-14' AND '2020-08-15'
GROUP BY f.flight_id, f.actual_departure;
Логический план этого запроса показан в листинге 4.2.
Листинг 4.2 ❖ Логический план запроса из листинга 4.1
project f.flight_no, f.actual_departure, count(p.passenger_id)[] (
group [f.flight_no, f.actual_departure] (
filter [f.departure_airport = 'JFK'] (
filter [f.arrival_airport = 'ORD'] (
filter [f.actual_departure >= '2020-08-14'](
filter [f.actual_departure <= '2020-08-15' ] (
join [bl.flight_id = f.flight_id] (
access (flights f),
join(bl.booking_id=p.booking_id (
access (booking_leg bl),
access (passenger p)
))))))))
Логический план показывает, какие логические операции следует выполнить, но не предоставляет подробной информации о том, как они будут выполняться. Планировщик создает для этого запроса план выполнения, показанный на рис. 4.1.
Чтобы получить план выполнения запроса, выполняется команда EXPLAIN. Она принимает любую грамматически правильную инструкцию SQL в качестве параметра и возвращает ее план выполнения.
Мы рекомендуем запускать примеры кода, приведенные в этой статье, и изучать планы выполнения. Однако учтите: выбор правильного плана выполнения - недетерминированный процесс. Планы, создаваемые вашей локальной базой данных, могут слегка отличаться от планов, показанных в этой книге; даже когда планы идентичны, время выполнения может отличаться в зависимости от аппаратного обеспечения и конфигурации.

Рис. 4.1 ❖ План выполнения
Надеемся, что если вы посмотрите на рис. 4.1, то ценность предыдущих статей станет очевидной - каждая строка плана представляет собой операцию, описанную ранее, поэтому ясно, что происходит за кулисами. Обратите внимание, что, помимо названий алгоритмов, каждая строка плана выполнения включает в себя несколько загадочных цифр в скобках. Все встанет на свои места, если вспомнить эту публикацию, в которой обсуждалось, как рассчитывается стоимость различных алгоритмов.
А именно план содержит оценки стоимости, ожидаемое количество выходных строк и ожидаемый средний размер («ширину») строк. Все эти значения рассчитываются исходя из статистики базы данных. Значения стоимости включают в себя совокупную стоимость всех предыдущих операций. Для каждой операции есть две оценки стоимости: первая показывает стоимость, необходимую для создания первой строки вывода, в то время как вторая оценивает полную стоимость получения всего результата. Позже в этой статье мы объясним, как оцениваются затраты. Оценки количества и ширины строк вывода необходимы для оценки стоимости вышестоящих операций.
Важно подчеркнуть, что все эти цифры являются приблизительными. Фактические значения, получаемые во время выполнения, могут отличаться от расчетных. Если вы подозреваете, что оптимизатор выбрал план, который не является оптимальным, вам может потребоваться взглянуть на эти оценки. Обычно для хранимых таблиц ошибка небольшая, но она неизбежно увеличивается после каждой следующей операции.
План выполнения представлен в виде дерева физических операций. В этом дереве узлы представляют операции, а стрелки указывают на операнды. На рис. 4.1 может быть непросто разглядеть дерево. Есть несколько инструментов, в том числе pgAdmin, которые могут генерировать графическое представление плана выполнения. На рис. 4.2 показано, как это может выглядеть. Фактически на этом рисунке изображен план выполнения для листинга 4.4, который мы обсудим позже в данной статье.
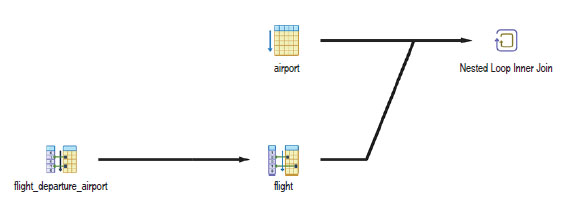
Рис. 4.2 ❖ Графическое представление простого плана выполнения (листинг 4.4)
Для более сложных запросов графическое представление плана выполнения может быть менее полезным - взгляните на представление плана выполнения для листинга 4.1 на рис. 4.3.

Рис. 4.3 ❖ Графическое представление плана выполнения для листинга 4.1
В таких случаях более компактное текстовое представление, как на рис. 4.4, оказывается полезнее.
Теперь вернемся к фактическому выводу команды EXPLAIN, изображенному на рис. 4.1. Он показывает каждый узел дерева в отдельной строке, начинающейся с символа ->, а глубина узла представлена отступом. Поддеревья помещаются после своего родительского узла. Некоторые операции представлены двумя строками.
Выполнение плана начинается с листьев и заканчивается у корня. Это значит, что операция, которая выполняется первой, находится в строке с наибольшим отступом. Конечно, план может содержать несколько листовых узлов, которые выполняются независимо. Как только операция создает выходную строку, эта строка передается следующей операции. Таким образом, не нужно хранить промежуточные результаты между операциями.
На рис. 4.1 выполнение начинается с последней строки, а таблица flight читается с помощью индекса по столбцу departure_airport. Поскольку к таблице применено несколько фильтров, а индексом поддерживается только одно из условий фильтрации, PostgreSQL выполняет операцию index bitmap scan (описанную в данном блоге). Движок обращается к индексу и составляет битовую карту блоков, которые могут содержать необходимые записи. Затем он считывает фактические блоки из базы данных с помощью операции bitmap heap scan, и для каждой записи, извлеченной из базы данных, повторно проверяет (recheck), что найденные в индексе строки являются текущими, и применяет фильтрацию (filter) для дополнительных условий по столбцам arrival_airport и schedule_departure, для которых у нас нет индексов.

Рис. 4.4 ❖ Альтернативное текстовое представление того же плана выполнения
Результат соединяется с таблицей booking_leg. PostgreSQL использует последовательное сканирование для доступа к этой таблице и алгоритм соединения хешированием по условию bl.flight_id = f.flight_id.
Затем таблица passenger читается последовательным сканированием (поскольку на ней нет никаких индексов), и снова используется алгоритм соединения хешированием по условию p.booking_id = bl.booking_id.
Последняя выполняемая операция - группировка и вычисление агрегатной функции sum. После сортировки выясняется, что критериям поиска удовлетворяет только один рейс. Таким образом, нет необходимости использовать какие-либо алгоритмы группировки, и выполняется подсчет всех пассажиров на найденном рейсе.
В следующем разделе рассматривается, что еще можно почерпнуть из плана выполнения и почему это важно.
Планы выполнения
Часто, когда мы объясняем, как читать планы выполнения, слушателей поражает размер плана даже для относительно простого запроса, а ведь в плане выполнения более сложного запроса могут быть сотни строк. Чтобы прочитать даже такой простой план, как на рис. 4.1, может потребоваться некоторое время. Иногда, хотя каждая строчка плана сама по себе понятна, остается вопрос: «Вот у меня медленный запрос, и вы говорите, чтобы я посмотрел план выполнения. Но там сотни строк, и что мне с этим делать? С чего начать?»
Хорошая новость заключается в том, что в большинстве случаев вам не нужно читать весь план, чтобы понять, что именно замедляет выполнение. В этом разделе мы подробнее познакомимся с интерпретацией планов выполнения.
Что происходит во время оптимизации?
Как упоминалось в блоге, оптимизатор выполняет два вида преобразований: заменяет логические операции соответствующими физическими алгоритмами выполнения и (возможно) изменяет структуру логического выражения, изменяя порядок, в котором выполняются логические операции.
Первый шаг - это переписывание запроса. На этом этапе оптимизатор PostgreSQL улучшает код, раскрывая подзапросы, заменяя представления их текстовым видом и т. д. Важно помнить, что этот шаг происходит всегда. Учебники по SQL, рассказывая о концепции представления, часто говорят, что «представления можно использовать как таблицы», и это вводит в заблуждение. В большинстве случаев представления заменяются их исходным кодом. Тем не менее «в большинстве случаев» не значит «всегда». В главе 7 обсуждаются представления и то, как оптимизатор обрабатывает их, а также связанные с ними потенциальные проблемы производительности.
Следующим шагом после переписывания запроса выполняется то, что мы обычно и называем оптимизацией. Она включает:
- определение возможных порядков операций;
- определение возможных алгоритмов выполнения для каждой операции;
- сравнение стоимости разных планов;
- выбор оптимального плана выполнения.
Многие разработчики SQL предполагают, что PostgreSQL выполняет запросы, обращаясь к таблицам в том порядке, в котором они указаны в предложении FROM, и соединяя их в том же самом порядке.
Однако в большинстве случаев порядок соединений не сохраняется. В следующих статьях мы более подробно обсудим, что влияет на порядок операций, а пока посмотрим, как оценить план выполнения.
Почему планов выполнения так много?
Мы несколько раз отмечали, что одна инструкция SQL может выполняться разными способами, используя разные планы исполнения. На самом деле могут быть сотни, тысячи или даже миллионы возможных способов выполнения одной команды! Эта статья дает представление о том, откуда берутся эти цифры. Планы могут отличаться:
- порядком операций;
- алгоритмами, используемыми для соединений и других операций (такими как вложенные циклы или соединение хешированием);
- методами получения данных (такими как индексный доступ или полное сканирование).
Говоря формально, оптимизатор находит лучший план, вычисляя стоимости всех возможных планов, а затем сравнивая их. Но поскольку мы знаем, что для выполнения каждого соединения есть три основных алгоритма, даже простой запрос из трех таблиц порождает девять возможных планов выполнения; учитывая 12 возможных порядков соединения, это дает 108 возможных планов (3 * 3 * 12 = 108). А если мы учтем все возможные методы извлечения данных для каждой таблицы, то количество планов увеличится до нескольких тысяч.
К счастью, PostgreSQL не проверяет все возможные планы.
Алгоритм оптимизации основан на принципе оптимальности: поддерево оптимального плана оптимально для соответствующего подзапроса. План можно рассматривать как композицию из нескольких составных частей или поддеревьев. Поддерево плана - это план, который включает в себя некоторую операцию исходного плана в качестве корневого узла и все ее дочерние узлы, то есть все операции, которые являются аргументами операции, выбранной в качестве корня поддерева. Оптимизатор строит оптимальный план, начиная с самых маленьких поддеревьев (то есть с доступа к отдельным таблицам), и постепенно создает более сложные поддеревья, включающие больше операций, выполняя на каждом шаге лишь несколько сравнений стоимости. Алгоритм является исчерпывающим: он строит оптимальный план, несмотря на то что значительная часть возможных планов не рассматривается.
Например, в предыдущем примере, как только оптимизатор выберет правильный алгоритм извлечения данных для одной из трех таблиц, он не будет рассматривать планы, которые не используют этот оптимальный алгоритм.
Тем не менее количество рассмотренных планов может быть огромным. Эвристики исключают те части пространства планов, которые вряд ли будут содержать оптимальные планы, уменьшая тем самым количество проверяемых вариантов. Хотя это и помогает оптимизатору быстрее выбирать план выполнения, но может отрицательно сказаться на производительности: существует риск, что самый подходящий план выполнения будет случайно исключен перед сравнением стоимостей.
Хотя эвристики и могут исключить оптимальный план, алгоритм строит лучший план из оставшихся.
Теперь рассмотрим подробнее, как рассчитываются стоимости.
Как рассчитываются стоимости выполнения?
В статье мы обсудили способы измерения производительности алгоритмов баз данных. Мы рассказали о внутренних показателях и установили, что стоимости алгоритмов измеряются количеством операций ввода-вывода и циклов процессора. Теперь мы применим эту теорию на практике.
Стоимость каждого плана выполнения зависит от:
- формул стоимости алгоритмов, используемых в плане;
- статистических данных по таблицам и индексам, включая распределение значений;
- системных настроек (параметров и предпочтений), таких как join_collapse_limit или cpu_index_tuple_cost.
В статье приведены формулы для расчета стоимости каждого алгоритма. Каждая из них зависит от размера обрабатываемых таблиц, а также от ожидаемого размера результирующего множества. И наконец, пользователи могут изменить стоимость по умолчанию для отдельных операций с помощью системных настроек. Выбором оптимального плана можно неявно управлять, изменяя параметры оптимизатора, которые используются при оценке стоимости. Таким образом, при расчете стоимости выполнения планов учитываются все три пункта.
Это нелогично; часто у разработчиков SQL есть подсознательные ожидания, что существует один «наилучший план» и, более того, он одинаков для всех «похожих» запросов. Однако из-за перечисленных факторов оптимизатор может создавать разные планы выполнения для почти идентичных SQL-запросов или даже для одного и того же запроса. Как такое может быть? Оптимизатор выбирает план с лучшей оценкой стоимости. Однако может быть несколько планов с почти одинаковыми стоимостями. Оценка стоимости зависит от статистики базы данных, собранной на основе случайной выборки. Статистика, собранная вчера, может незначительно отличаться от сегодняшней статистики. Из-за этих небольших изменений план, который был лучшим вчера, сегодня может занять второе место. Конечно, статистика также может измениться в результате операций вставки, обновления и удаления.
Рассмотрим несколько примеров. В листингах 4.3 и 4.4 представлены два запроса, которые почти идентичны. Единственная разница состоит в значении, по которому происходит фильтрация. Однако планы выполнения, представленные на рис. 4.5 и 4.6, заметно отличаются.
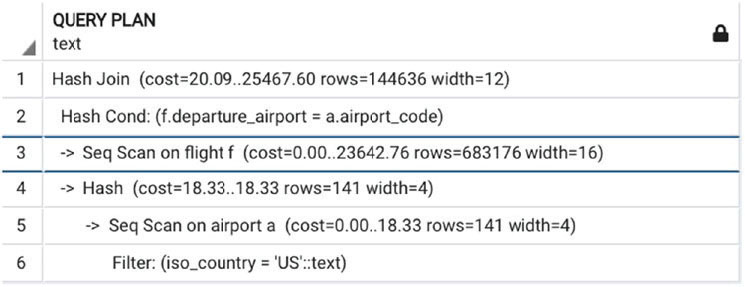
Рис. 4.5 ❖ План выполнения для листинга 4.3
Чем вызвана эта разница? Рисунок 4.7 дает подсказку: первый запрос выбирает значительную часть всех аэропортов, и использование индекса не улучшит производительность. Второй запрос, напротив, выберет только один аэропорт, и в этом случае доступ на основе индекса будет более эффективным.
Листинг 4.3 ❖ Простой запрос с одним условием
SELECT flight_id, scheduled_departure
FROM flight f
JOIN airport a ON departure_airport = airport_code
AND iso_country = 'US'
Листинг 4.4 ❖ Тот же запрос, что и в листинге 4.3, но с другим значением
SELECT flight_id, scheduled_departure
FROM flight f
JOIN airport a ON departure_airport = airport_code
AND iso_country = 'CZ'
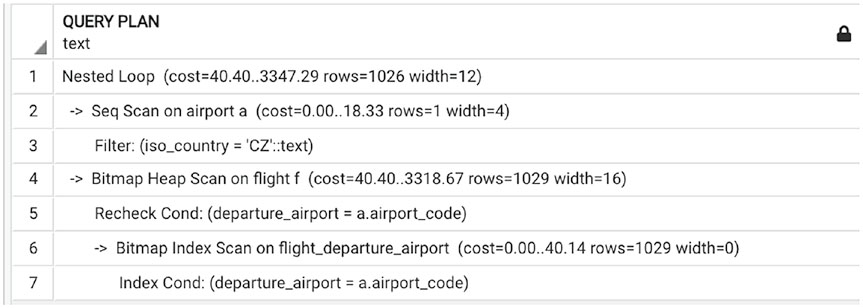
Рис. 4.6 ❖ План выполнения для листинга 4.4
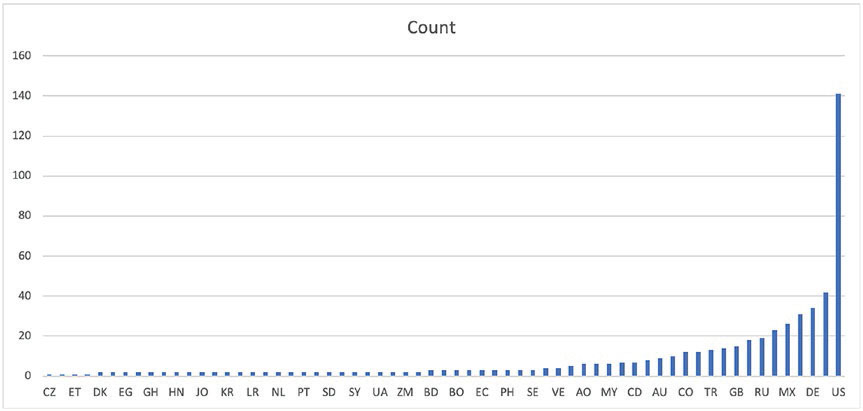
Рис. 4.7 ❖ Гистограмма распределения значений
Почему оптимизатор может ошибаться?
Но как мы можем быть уверены, что выбранный оптимизатором план действительно наилучший? И можно ли вообще найти наилучший план выполнения? Мы потратили довольно много времени на объяснение того, что оптимизатор выполняет свою работу наилучшим образом, если мы не будем ему мешать. Но если это так, то о чем же остальная часть книги? Реальность такова, что ни один оптимизатор не идеален, даже планировщик запросов PostgreSQL.
Во-первых, хотя алгоритм оптимизации математически верен, то есть находит план с лучшей оценкой стоимости, эти оценки по сути своей неточны. Простые формулы, объясненные в этой Статье, действительны только для равномерного распределения данных, но равномерное распределение редко встречается в реальных базах данных. На самом деле оптимизаторы используют более сложные формулы, но они также являются несовершенными приближениями к реальности. Как сказал Джордж Бокс: «Все модели неверны, но некоторые из них полезны».
Во-вторых, системы баз данных, включая PostgreSQL, собирают подробную статистику хранимых данных (обычно в виде гистограмм). Гистограммы значительно улучшают оценки селективности. Но, к сожалению, их нельзя использовать для промежуточных результатов. Ошибки при оценке промежуточных результатов - основная причина, из-за которой у оптимизатора может не получиться построить оптимальный план.
В-третьих, оптимальный план может быть исключен эвристиками, или запрос может быть слишком сложен для точного алгоритма оптимизации. В последнем случае используются алгоритмы приблизительной оптимизации.
Во всех этих ситуациях требуется вмешательство человека, и книга как раз об этом. Теперь, когда мы знаем, что происходит во время оптимизации, мы можем исправить проблему, если что-то работает не так, как надо.
Несмотря на все описанные возможности ошибиться, в большинстве случаев оптимизаторы работают хорошо. Однако мы наблюдаем за поведением всей системы и, следовательно, нам доступно больше информации, чем оптимизатору. Мы можем использовать эти дополнительные знания, чтобы помочь оптимизатору работать еще лучше.
Выводы
В этой гстатье мы рассмотрели планы выполнения: как они создаются, как их читать и понимать. Мы также узнали об оптимизации на основе стоимости и факторах, которые влияют на стоимость планов выполнения.
Хотя стоимостные оптимизаторы обычно хорошо справляются со своей задачей, иногда им нужна помощь, и теперь у нас есть все необходимое, чтобы ее предоставить. В следующих публикациях будет рассмотрено несколько примеров запросов, требующих вмешательства человека для повышения производительности.