 Вы можете ознакомиться с тем, как работает кэш данных в СУБД Oracle в этой и этой статьях, мы можем вернуться к кэшу кода, точнее – к библиотечному кэшу (library cache) и к кэшу словаря (dictionary cache). Оба кэша являются частью разделяемого пула (shared pool, или кучи SGA), поэтому мы неизбежно будем знакомиться с некоторыми универсальными механизмами, воздействующими на весь разделяемый пул.
Вы можете ознакомиться с тем, как работает кэш данных в СУБД Oracle в этой и этой статьях, мы можем вернуться к кэшу кода, точнее – к библиотечному кэшу (library cache) и к кэшу словаря (dictionary cache). Оба кэша являются частью разделяемого пула (shared pool, или кучи SGA), поэтому мы неизбежно будем знакомиться с некоторыми универсальными механизмами, воздействующими на весь разделяемый пул.
Так как библиотечный кэш является тем местом, куда попадают инструкции SQL или PL/SQL (в форме, пригодной для выполнения), мы начнем наше путешествие по библиотечному кэшу с момента, когда пользовательская программа посылает Oracle фрагмент текста и ожидает выполнения некоторых действий.
После того, как мы узнаем, что Oracle делает с прежде не встречавшимся фрагментом текста, мы займемся исследованием разных способов повторного выполнения заданного фрагмента и посмотрим, как меняется нагрузка на Oracle, в зависимости от выбранного способа.
Понимание SQL
Давайте рассмотрим процесс парсинга и оптимизации SQL в Oracle. Возьмем за основу следующую инструкцию:
update
t1
set
small_no = small_no + 0.1
where
id = 3
and small_no = 1
;
Насколько сложно будет базе данных Oracle понять, что означает эта инструкция, и выбрать наиболее оптимальный способ ее выполнения? Строго говоря, первая часть вопроса относится к парсингу (parsing), а вторая – к оптимизации. К сожалению многие склонны объединять эти два понятия под одним названием «парсинг».
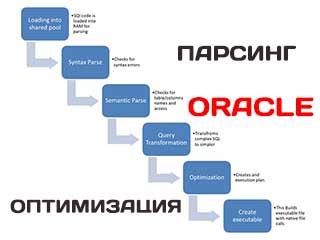
Парсинг команд SQL в базе данных Oracle
Первым делом, разумеется, база данных Oracle проверяет – является ли этот текст допустимой инструкцией SQL – этот шаг известен как синтаксический анализ. Если будет сделан вывод, что это допустимая инструкция, Oracle попробует ответить себе на множество вопросов об этой инструкции, таких как:
- Каков тип объекта
t1?Таблица, представление, синоним или что-то иное. - Являются ли
id и small_noстолбцами объектаt1(может бытьid– это функция, возвращающая целое число)? - Имеет ли столбец
small_noкакие-либо ограничения, которые необходимо проверить перед его изменением? - Имеются ли в объекте какие-либо триггеры, которые должны срабатывать при обновлении?
- Имеются ли какие-нибудь индексы, которые должны обновляться вместе с объектом?
- Имеет ли данный пользователь право изменять объект?
Эта стадия исследования называется семантическим анализом – комбинация синтаксического и семантического анализа как раз и называется парсингом.
Оптимизация инструкций SQL в базе Oracle
Как только будет выяснено, что инструкция является допустимой и пользователь обладает всеми необходимыми правами для ее выполнения, Oracle начинает оптимизировать SQL и в ходе оптимизации пытается ответить еще на ряд вопросов, таких как:
- Имеются ли какие-либо индексы, включающие столбцы
idи/илиsmall_no, которые могут помочь в выполнении? - Какие статистики доступны для столбцов, таблиц и индексов?
После этого оптимизатор собирает дополнительную информацию о системе (значения различных параметров – динамических переменных и статистик) и запускает сложную процедуру, определяющую путь выполнения инструкции. Но об этой стадии мы побеседуем потом. А сейчас я хочу поговорить об основах парсинга.
Чтобы показать, какой объем работы проделывает версия 11g (11.2.0.2, в данном случае) для парсинга даже простой инструкции, я очистил разделяемый пул (причины я объясню чуть ниже) вызовом alter system flush shared_pool; enabled sql_trace, выполнил запрос, приведенный выше, и затем запустил утилиту tkprof для анализа полученного файла трассировки. Заключительный раздел в файле, произведенном утилитой tkprof, содержал следующую сводную информацию:
1 session in tracefile. 2 user SQL statements in trace file. 15 internal SQL statements in trace file. 17 SQL statements in trace file. 17 unique SQL statements in trace file. 737 lines in trace file. 0 elapsed seconds in trace file.
Итак, в трассировочном файле хранятся сведения о выполнении двух «пользовательских» (user) инструкциях SQL: первая – это инструкция alter session set sql_trace true;, которую я выполнил, чтобы включить sql_trace, и вторая – моя инструкция update. Однако, Oracle выполнил еще 15 внутренних (internal) инструкций SQL – вспомогательных инструкций, с помощью которых Oracle собрал всю информацию, необходимую для парсинга и оптимизации моей тестовой инструкции. Инструкции этого типа обычно называют системно-рекурсивными (sys-recursive) инструкциями. Если вы думаете, что 15 дополнительны инструкций – это много, значит вы еще не видели всю картину целиком. Ниже приводится статистики, отражающие работу этих 15 инструкций:
OVERALL TOTALS FOR ALL RECURSIVE STATEMENTS call count cpu elapsed disk query current rows ------- ------ ------- ---------- ---------- --------- --------- --------- Parse 15 0.01 0.00 0 0 0 0 Execute 99 0.06 0.05 0 0 0 0 Fetch 189 0.03 0.01 0 388 0 633 ------- ------ ------- ---------- ---------- --------- --------- --------- total 303 0.10 0.07 0 388 0 633 Misses in library cache during parse: 15 Misses in library cache during execute: 15
В строке Parse можно видеть число вызовов parse для передачи 15 внутренних инструкций механизму Oracle. Но взгляните на цифры ниже – общее число вызовов execute для выполнения всех этих инструкций составило 99, и 189 вызовами fetch было извлечено 633 строки информации. Объем выполняемой работы поражает.
В действительности этот демонстрационный пример не совсем точно отражает нагрузку, и я могу показать расхождения, если воспользуюсь еще одной таблицей в той же схеме. Вторая таблица называется t1a и является точной копией таблицы t1 – вплоть до определения первичного ключа. Если сейчас запустить ту же инструкцию update, подставив имя t1a вместо t1, утилита tkprof сгенерирует следующие результаты.
OVERALL TOTALS FOR ALL RECURSIVE STATEMENTS call count cpu elapsed disk query current rows ------- ------ -------- --------- ---------- --------- --------- --------- Parse 15 0.00 0.00 0 0 0 0 Execute 43 0.00 0.00 0 0 0 0 Fetch 51 0.00 0.00 0 135 0 526 ------- ------ -------- --------- ---------- --------- --------- --------- total 109 0.00 0.00 0 135 0 526 Misses in library cache during parse: 0
Даже при том, что число вызовов parse осталось тем же, появились любопытные расхождения в числе вызовов execute и fetch. Существует еще одно важное отличие в значении Misses in library cache. Эта последняя деталь многое говорит нам о том, как Oracle пытается добиться максимальной эффективности при обработке инструкций SQL, и дает некоторые подсказки, касающиеся кэширования выполняемого кода, если знать, как правильно интерпретировать результаты.
Интерпретация результатов tkprof
Прежде чем выполнить первую инструкцию, я очистил разделяемый пул. Сделано это было для того, чтобы удалить любые, выполнявшиеся прежде, инструкции из библиотечного кэша, вместе с информацией о привилегиях и зависимостях, а также все определения объектов из кэша словаря.
Когда я попытался выполнить первую тестовую инструкцию, Oracle выполнил запрос к базе данных (или, если говорить точнее, к множеству таблиц, известному как словарь данных (data dictionary)), чтобы найти определения всех объектов, на которые ссылается инструкция. Это видно по инструкции, сохраненной в трассировочном файле:
select
obj#, type#, ctime, mtime, stime, status,
dataobj#, flags, oid$, spare1, spare2
from
obj$
where
owner#=:1
and name=:2
and namespace=:3
and remoteowner is null
and linkname is null
and subname is null
;
Данная конкретная инструкция проверяет наличие объекта в указанном пространстве имен и принадлежащего указанной схеме в локальной базе данных. Другие запросы обращаются к таким таблицам, как tab$ – за информацией о таблицах, col$ – за информацией о столбцах, ind$ – за информацией об индексах, icol$ – за информацией о столбцах, для которых определены индексы, и так далее. Однако в качестве примера я выбрал данный запрос потому, что он был выполнен пять раз для первой тестовой инструкции и только два раза – для второй.
В обоих тестах было выполнено два запроса для поиска некоторой информации о таблице (t1 / t1a) и ее первичном ключе (t1_pk /t1a_pk) – но затем в первом тесте было выполнено еще три запроса для поиска информации о паре индексов с именами i_objauth2 и i_objauth1, и таблицы trigger$. Oracle потребовались дополнительные сведения о внутренних таблицах и индексах, чтобы решить, как выполнить рекурсивные инструкции SQL для поиска дополнительной информации о моих таблицах и индексах. Это объясняет, почему для первого тестового запроса потребовалось выполнить больше работы, чем для второго. В ходе выполнения первого теста была выполнена масса «подготовительных» операций, тогда как в ходе выполнения второго теста использовалась кэшированная информация,
оставшаяся после первого теста.
Когда я говорю о кэшированной информации, я не имею в виду кэшированные данные. В данном случае подразумеваются кэшированные метаданные (информация о данных) и код – именно для этой цели и существуют кэш словаря и библиотечный кэш, соответственно. Кэш словаря (также известный как кэш строк (row cache)) хранит информацию об объектах, таких как таблицы, индексы, столбцы, гистограммы, триггеры и так далее. Библиотечный кэш хранит информацию об инструкциях (SQL и PL/SQL), их курсорах, а также массу другой информации о зависимостях объектов и привилегиях.
Изменение числа выполненных запросов во втором тесте наглядно показало, что Oracle использует преимущества, которые дает кэш словаря. Например, чтобы найти информацию об индексе i_objauth1, не потребовалось выполнять какие-либо запросы, потому что эта информация уже была прочитана из словаря данных и скопирована в кэш словаря в процессе выполнения первого теста.
Аналогично, изменение числа промахов в библиотечном кэше (library cache misses) во втором тесте наглядно показало, что Oracle использует преимущества, которые дает библиотечного кэша. Взгляните на следующие строки, которые я извлек из результатов работы утилиты tkprof. После первого теста она сообщила:
Misses in library cache during parse: 15 Misses in library cache during execute: 15
После второго:
Misses in library cache during parse: 0
Промах (miss) библиотечного кэша говорит, что попытка найти в библиотечном кэше (допустимый и действительный) дочерний курсор провалилась, и потому пришлось оптимизировать инструкцию перед ее использованием. В первом тесте пришлось оптимизировать все 15 рекурсивных инструкций SQL. Во втором тесте – ни одной, потому что соответствующие курсоры уже имелись в библиотечном кэше. Первый тест показывает наличие промахов обоих видов – при парсинге и выполнении – каждой инструкции. Отсутствие промахов при выполнении возможно, но в данном случае, я думаю, проявилась ошибка в 11g (см. примечание ниже) – как показала трассировка события 10 053, инструкции оптимизировались один раз в ходе тестирования.
Примечание. В выводе tkprof каждая инструкция должна сопровождаться двумя строками, в которых указывается число промахов библиотечного кэша в ходе выполнения parse и execute. С помощью этой информации можно определить, сколько раз инструкция оптимизировалась в процессе трассировки. К сожалению, похоже, что 11g сообщает о промахах execute сразу после промаха parse, и я полагаю (но не могу этого доказать), что это ошибка. В ранних версиях Oracle статистика Misses in library cache during execute давала удобную возможность определить потери оптимизированных инструкций из-за нехватки памяти – я думаю, что в 11g следует вычитать промахи parse из промахов execute, чтобы получить точное представление о промахах в ходе выполнения.
Далее мы продолжим использовать этот пример в процессе исследования библиотечного кэша и кэша словаря. И начнем с кэша словаря, но уже в новой статье.
