Системы управления базами данных (СУБД) организует и структурирует данные таким образом, чтобы пользователи и прикладные программы могли их сохранять и выбирать из базы данных. Структуры данных и способы доступа к ним, обеспечиваемые конкретной СУБД, называются ее моделью данных. Модель данных определяет как "индивидуальность" СУБД, так и круг приложений, для которых она подходит наилучшим образом.
SQL представляет собой язык для работы с реляционными базами данных и основан на реляционной модели данных. Что это такое? В каком виде информация хранится в реляционной базе данных? Чем реляционные базы данных отличаются от более ранних баз данных, таких как иерархические и сетевые? Какими преимуществами и недостатками обладает реляционная модель? В данной статье описана реляционная модель данных, поддерживаемая языком SQL, и приведено ее сравнение с более ранними стратегиями организации баз данных.
Ранние модели данных
Когда в 1970-80-х годах стали популярны базы данных, появилось множество различных моделей данных. Каждая из них имела свои преимущества и недостатки, которые сыграли ключевую роль в развитии реляционной модели данных, появившейся во многом благодаря стремлению упростить и упорядочить ранние модели данных. Чтобы понять роль SQL и реляционных баз данных и оценить их вклад в развитие СУБД, следует кратко изучить ряд моделей данных, предшествовавших появлению SQL.
Системы управления файлами
До появления СУБД все данные, которые содержались в компьютерной системе постоянно, хранились в виде отдельных файлов. Система управления файлами, которая обычно являлась частью операционной системы, следила за именами файлов и их размещением. Системы управления файлами широко используются и сегодня — вероятно, вы знакомы со структурой папок и файлов, предоставляемой файловыми системами операционных систем Microsoft Windows или Macintosh компании Apple. Аналогичные файловые системы используются и в UNIX- серверах и всех коммерческих вычислительных системах.
В системах управления файлами модели данных, как правило, отсутствуют; эти системы ничего не знают о внутреннем содержимом файлов. В лучшем случае файловая система поддерживает информацию о "типе файла" наряду с его именем, позволяя отличить документ текстового редактора от файла, содержащего данные о начисленной зарплате. Знание о содержимом файла — какие данные в нем хранятся и как они организованы — удел прикладных программ, использующих этот файл, как показано на рис. 1. В этом приложении начисления зарплаты каждая из программ на языке программирования COBOL, работающая с основным файлом с информацией о сотрудниках, содержит описание файла (file description, FD), в котором указана схема размещения данных в файле. Если структура данных изменяется — например, при решении хранить некоторую дополнительную информацию о каждом сотруднике— должны быть соответствующим образом модифицированы все программы, работающие с данным файлом. Это не слишком большая проблема в случае файла с документом текстового редактора или электронных таблиц, которые обычно обрабатываются одной программой. Но при корпоративной работе с данными файлы зачастую совместно используются десятками, а то и сотнями программ (см. рис. 1). При увеличении количества файлов и программ отделу обработки данных придется тратить больше усилий на поддержание работоспособности старых программ, чем на разработку новых.
Проблемы сопровождения больших систем, основанных на файлах, привели в конце 1960-х годов к появлению СУБД. В основе СУБД лежала простая идея: изъять из отдельных программ определение структуры содержимого файла и хранить это определение вместе с данными, в базе данных. Используя информацию, хранящуюся в базе данных, СУБД может играть существенно более активную роль как в управлении данными, так и в изменениях структуры данных. Кроме того, СУБД представляют собой расширения систем управления файлами, а не их замену. СУБД используют системы управления файлами (обычно входящими в состав операционных систем) для хранения структур баз данных. Затем пользователь базы данных обращается к СУБД, которая работает с деталями физического хранения информации. Это тот уровень абстракции, который обеспечивает физическую независимость данных.

Рис. 1. Приложение для начисления зарплаты, использующее систему управления файлами
Иерархические базы данных
Одной из наиболее важных сфер применения первых СУБД было планирование производства для компаний, занимающихся выпуском продукции. Например, если автомобильная компания хотела выпустить 10000 машин одной модели и 5000 машин другой модели, ей необходимо было знать, сколько деталей следует заказать у своих поставщиков. Чтобы ответить на этот вопрос, необходимо выяснить, из каких частей состоит изделие, затем определить, из каких деталей состоят эти части, и т.д. Например, машина состоит из двигателя, корпуса и ходовой части; двигатель состоит из клапанов, цилиндров, свечей и т.д. Для обработки таких списков частей идеально подходят компьютеры.
Список составных частей изделия по своей природе является иерархической структурой. Для хранения данных, имеющих такую структуру, была разработана иерархическая модель данных, которую иллюстрирует рис. 2. В этой модели каждая запись базы данных представляла конкретную деталь. Между записями существовали отношения предок-потомок, связывающие каждую часть с деталями, входящими в нее.
При доступе к информации, содержащейся в базе данных, программа могла выполнить следующие задачи:
- найти конкретную деталь (такую, как левая дверь) по ее номеру;
- перейти "вниз" к первому потомку (ручка двери);
- перейти "вверх" к предку (кузов);
- перейти "в сторону" к другому потомку (правая дверь).

Рис. 2. Иерархическая база данных, содержащая информацию о составных частях
Таким образом, для чтения информации из иерархической базы данных требовалась возможность перемещения по записям, за один шаг переходя на одну запись вверх, вниз или в сторону.
Одной из наиболее популярных иерархических СУБД была Information Management System (IMS) компании IBM, появившаяся в 1968 году. Ниже перечислены преимущества IMS и реализованной в ней иерархической модели.
- Простая структура. Организацию базы данных IMS легко понять. Иерархия базы данных напоминает структуру компании или генеалогическое дерево.
- Использование отношений "предок-потомок". СУБД IMS позволяла легко представлять отношения "предок-потомок", такие как "А является частью В" или "А принадлежит В".
- Производительность. В СУБД IMS отношения "предок-потомок" реализованы в виде физических указателей из одной записи на другую, вследствие чего перемещение по базе данных выполняется очень быстро.
СУБД IMS все еще остается одной из распространенных СУБД для мэйнфреймов компании IBM. Обладающая очень высокой производительностью, она идеально подходит для приложений, связанных с обработкой большого числа транзакций, таких как транзакции с кредитными карточками или резервирование авиабилетов. Хотя за последние пару десятилетий производительность реляционных баз данных возросла столь существенно, что описанное преимущество IMS стало не столь важным, большое количество корпоративных данных, хранящихся в базах данных IMS, и множество старых приложений, работающих с этими данными, гарантируют, что СУБД IMS будет использоваться еще много лет.
Сетевые базы данных
Если структура данных оказывалась сложнее, чем обычная иерархия, простота организации иерархической базы данных становилась ее недостатком. Например, в базе данных для хранения заказов один заказ может участвовать в трех различных отношениях "предок-потомок", связывающих заказ с покупателем, разместившим его, продавцом, принявшим его, и с заказанным товаром, что проиллюстрировано на рис. 3. Такие структуры данных не соответствовали строгой иерархии IMS.

Рис. 3. Множественные отношения “предок-потомок”
В связи с этим для таких приложений, как обработка заказов, была разработана новая, сетевая, модель данных. Она расширила иерархическую модель, позволяя одной записи участвовать в нескольких отношениях "предок-потомок", именуемых множествами (set) (рис. 4). В 1971 году на конференции по языкам обработки данных (Conference on Data Systems Languages, CODASYL) был опубликован официальный стандарт сетевых баз данных, который известен как модель CODASYL. Компания IBM не стала разрабатывать собственную сетевую СУБД, но в 1970-х годах независимые производители программного обеспечения реализовали сетевую модель в таких продуктах, как IDMS компании Cullinet, Total компании Cincom и СУБД Adabas, которые приобрели большую популярность. Однако IBM усовершенствовала IMS, обеспечив путь обхода правила единственного предка в классических иерархических структурах, в котором дополнительные предки рассматриваются как логические. Эта модель данных, ставшая известной как расширенная иерархическая модель, сделала базу данных IMS конкурентом сетевых СУБД.
С точки зрения программиста, доступ к сетевой базе данных был очень похож на доступ к иерархической базе данных. Прикладная программа могла сделать следующее:
- найти определенную запись предка по ключу (такому, как номер клиента);
- перейти к первому потомку в определенном множестве (первый заказ, размещенный клиентом);
 база данных для работы с заказами")
Рис. 4. Сетевая (CODASYL) база данных для работы с заказами
- перейти от одного потомка к другому в определенном множестве по горизонтали (следующий заказ, сделанный этим же клиентом);
- перейти вверх от потомка к его предку в другом множестве (служащий, принявший заказ).
И опять программисту приходилось искать информацию в базе данных, последовательно перебирая записи, но указывая при этом не только направление, но и требуемое отношение.
Сетевые базы данных обладали рядом преимуществ.
- Гибкость. Множественные отношения "предок-потомок" позволяли сетевой базе данных хранить информацию, структура которой не укладывалась в простую иерархию.
- Стандартизация. Появление стандарта
CODASYLувеличило популярность сетевой модели, упрощая программистам переход от одной СУБД к другой. - Производительность. Отношения "предок-потомок" были представлены указателями на физические записи, что обеспечивало высокую скорость перемещения по базе данных.
Конечно, у сетевых баз данных имелись недостатки. Подобно своим иерархическим предкам, сетевые базы данных были очень "жесткими". Наборы отношений и структура записей должны были быть заданы наперед. Изменение структуры базы данных обычно означало полную перестройку последней.
И иерархическая, и сетевая база данных были инструментами программистов. Чтобы получить ответ на вопрос какой товар наиболее часто заказывает компания X? или сколько всего заказано единиц товара Y?, программисту приходилось писать программу для навигации по базе данных, выборки нужных записей и подсчета результата. Реализация пользовательских запросов часто затягивалась на недели и месяцы, и к моменту появления программы возвращаемая ею информация часто оказывалась бесполезной.
Недостатки иерархической и сетевой моделей привели к повышенному интересу к новой реляционной модели данных, впервые описанной доктором Коддом в 1970 году. Поначалу она представляла лишь академический интерес. Сетевые базы данных продолжали оставаться важной технологией на протяжении 1970-х и в начале 1980-х годов, особенно в мини-компьютерных системах, переживавших пик популярности. Однако в середине 1980-х годов начался взлет реляционной модели. В начале 1990-х годов сетевые базы данных утратили популярность и сегодня не играют значительной роли на рынке баз данных.
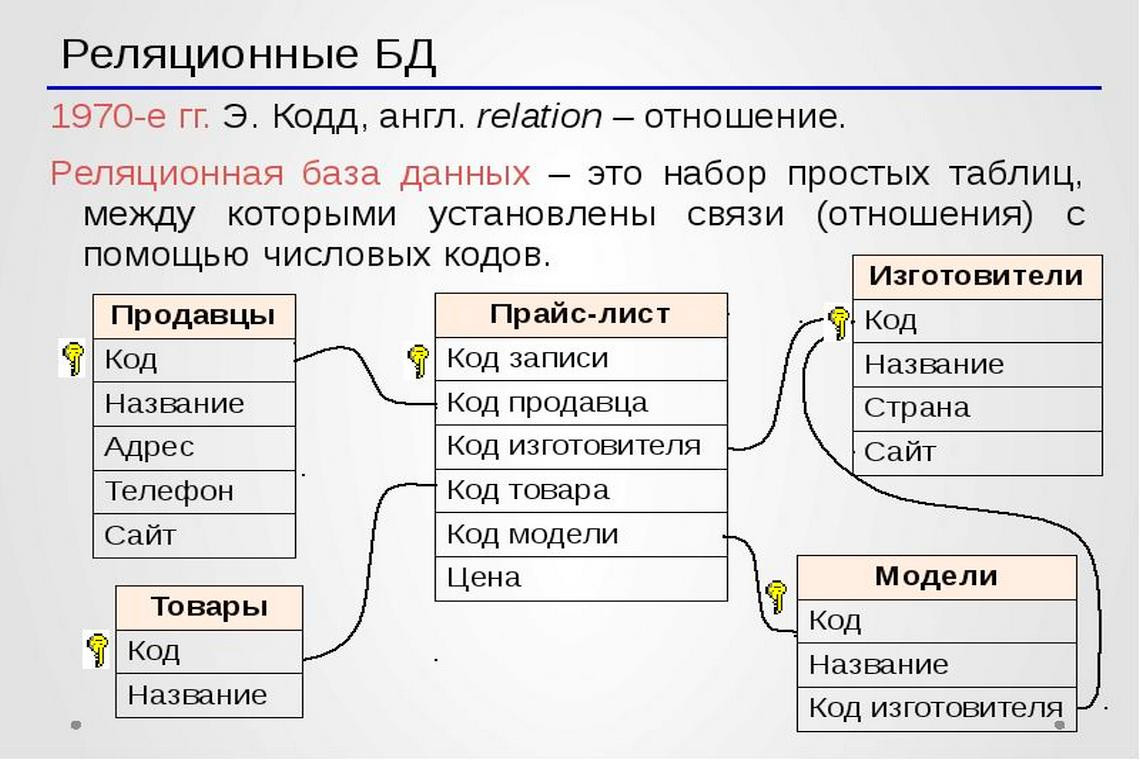
Реляционная модель данных
Реляционная модель данных, предложенная Коддом, была попыткой упростить структуру базы данных. В ней отсутствовала явная структура "предок-потомок", а все данные были представлены в виде простых таблиц, разбитых на строки и столбцы. На рис. 5 показана реляционная версия рассмотренной выше сетевой базы данных, содержащей информацию о заказах (рис. 4).

Рис. 5. Реляционная база данных для работы с заказами
Работа Кодда дает точное, математическое определение реляционной базы данных, а также теоретический фундамент для операций, которые могут быть выполнены над ней. Однако более полезно следующее неформальное определение реляционной базы данных.
Определение. Реляционной называется база данных, в которой все данные, доступные пользователю, организованы в виде таблиц, а все операции базы данных выполняются над этими таблицами
Приведенное определение не оставляет места пользовательским структурам, таким как встроенные указатели иерархических и сетевых СУБД. Реляционная СУБД способна реализовать отношения "предок-потомок", однако эти отношения представлены исключительно значениями, содержащимися в таблицах базы данных.
Учебная база данных
На рис. 6 показана маленькая реляционная база данных для приложения, выполняющего обработку заказов. Большинство примеров в данном блоге построено на ее основе. Полное описание структуры и содержимого учебной базы данных, изображенной на рис. 6, приведено в приложении А, "Учебная база данных". Здесь представлено только по нескольку строк каждой таблицы.
")
Рис. 6. Учебная база данных (представлена частично)
В учебной базе данных содержится пять таблиц. В каждой таблице хранится информация об одном конкретном типе данных:
- в таблице
SALESREPS - в таблице
productsхранятся данные о каждом товаре, предлагаемом на продажу, такие как его производитель, идентификатор, описание и цена; - в таблице
ORDERSхранятся все заказы клиентов с указанием идентификатора служащего, принявшего заказ, идентификатора заказанного товара, его количества, стоимости заказа и т.д.; для простоты в одном заказе может упоминаться только один товар; - в таблице
OFFICESхранятся данные о каждом офисе, включая город, в котором расположен офис, область, к которой он принадлежит, и т.д.; - в таблице
CUSTOMERSхранятся данные о каждом клиенте, такие как название компании, лимит кредита и идентификатор служащего, работающего с этим клиентом.
Таблицы
В реляционной базе данных информация организована в виде прямоугольных таблиц, разделенных на строки и столбцы, на пересечении которых содержатся значения данных. Каждая таблица имеет уникальное имя, описывающее ее содержимое. (На практике каждый пользователь может присваивать собственным таблицам имена, не беспокоясь о том, какие имена выберут для своих таблиц другие пользователи.)
Более наглядно структуру таблицы иллюстрирует рис. 7, на котором изображена таблица OFFICES. Каждая горизонтальная строка этой таблицы представляет отдельную физическую сущность — один офис. Пять строк таблицы вместе представляют все пять офисов компании. Все данные, содержащиеся в конкретной строке таблицы, относятся к офису, который описывается этой строкой.

Рис. 7. Структура реляционной таблицы
Каждый вертикальный столбец таблицы OFFICES представляет один элемент данных для каждого из офисов. Например, в столбце CITY содержатся названия городов, в которых расположены офисы. В столбце SALES содержатся объемы продаж, обеспечиваемые офисами. В столбце MGR содержатся идентификаторы управляющих офисами.
На пересечении строки и столбца таблицы содержится только одно значение данных. Например, в строке, представляющей нью-йоркский офис, в столбце CITY содержится значение "New York". В столбце SALES этой же строки находится значение $692 637.00, которое является объемом продаж нью-йоркского офиса с начала года.
Все значения, содержащиеся в одном и том же столбце, являются данными одного типа. Например, в столбце CITY содержатся только слова, в столбце SALES — денежные суммы, а в столбце MGR — целые числа, представляющие идентификаторы служащих. Множество значений, которые могут содержаться в столбце, называется доменом этого столбца. Доменом столбца CITY является множество всех названий городов. Домен столбца SALES — это любая денежная сумма. Домен столбца region состоит всего из двух значений, "Eastern" и "Western", поскольку у компании всего два торговых региона.
У каждого столбца в таблице есть свое имя, которое обычно служит заголовком столбца. Все столбцы в одной таблице должны иметь уникальные имена, однако разрешается присваивать одинаковые имена столбцам, расположенным в различных таблицах. На практике такие имена столбцов, как NAME (имя), ADDRESS (адрес), PRICE (цена) и тому подобные, часто встречаются в различных таблицах одной базы данных.
Столбцы таблицы упорядочены слева направо, и их порядок определяется при создании таблицы. В любой таблице всегда есть как минимум один столбец. В стандарте ANSI/ISO максимально допустимое число столбцов в таблице не указывается; однако почти во всех коммерческих СУБД такой предел существует, но он редко бывает меньше 255 столбцов.
В отличие от столбцов, строки таблицы не имеют определенного порядка. Это значит, что если последовательно выполнить два одинаковых запроса для отображения содержимого таблицы, нет гарантии, что оба раза строки будут перечислены в одном и том же порядке. Конечно, можно попросить SQL-запрос отсортировать строки перед выводом, однако порядок сортировки не имеет совершенно ничего общего с фактическим расположением строк в таблице.
В таблице может содержаться любое количество строк. По очевидным причинам допускается существование таблицы с нулевым количеством строк. Такая таблица называется пустой. Пустая таблица сохраняет структуру, определенную ее столбцами, просто в ней не содержатся данные. Стандарт ANSI/ISO не накладывает ограничений на количество строк в таблице, и во многих СУБД размер таблиц ограничен лишь свободным дисковым пространством компьютера. В других СУБД имеется максимальный предел, однако обычно он весьма высок, — два миллиарда строк, а то и больше.
Первичные ключи
Поскольку строки в реляционной таблице не упорядочены, нельзя выбрать строку по ее номеру в таблице. В таблице нет "первой", "последней" или "тринадцатой" строки. Тогда каким же образом можно выбрать в таблице конкретную строку, например строку для офиса, расположенного в Денвере?
В правильно построенной реляционной базе данных в каждой таблице есть столбец (или комбинация столбцов), для которого значения во всех строках различны. Этот столбец (столбцы) называется первичным ключом (primary key) таблицы. Давайте вновь посмотрим на базу данных, изображенную на рис. 7. На первый взгляд, первичным ключом таблицы OFFICES могут служить и столбец office, и столбец CITY. Однако в случае, если компания будет расширяться и откроет в каком-либо городе второй офис, столбец CITY больше не сможет исполнять роль первичного ключа. На практике в качестве первичных ключей таблиц обычно следует выбирать идентификаторы, такие как идентификатор офиса (office в таблице OFFICES), служащего (empl_num в таблице SALESREPScust_num в таблице CUSTOMERS). В случае с таблицей ORDERS у нас нет выбора — единственным столбцом, содержащим уникальные значения, является номер заказа (ORDER_NUM).
Таблица products, фрагмент которой показан на рис. 8, является примером таблицы, в которой первичный ключ представляет собой комбинацию столбцов. Такой первичный ключ называется составным. Столбец MFR_ID содержит идентификаторы производителей всех товаров, перечисленных в таблице, а столбец PRODUCT_ID содержит номера, присвоенные товарам производителями. Может показаться, что столбец PRODUCT_ID мог бы и один исполнять роль первичного ключа, однако ничто не мешает двум различным производителям присвоить своим изделиям одинаковые номера. Таким образом, в качестве первичного ключа таблицы products необходимо использовать комбинацию столбцов MFR_ID И PRODUCT_ID. Для каждого из товаров, содержащихся в таблице, комбинация значений в этих столбцах будет уникальной.

Рис. 8. Таблица с составным первичным ключом
Первичный ключ у каждой строки таблицы является уникальным в пределах таблицы, поэтому в таблице с первичным ключом нет двух совершенно одинаковых строк. Таблица, в которой все строки отличаются друг от друга, в математических терминах называется отношением (relation). Именно этому термину реляционные базы данных и обязаны своим названием, поскольку в их основе лежат отношения, т.е. таблицы с отличающимися друг от друга строками.
Хотя первичные ключи являются важной частью реляционной модели данных, в первых реляционных СУБД (System/R, DB2, Oracle и других) явная их поддержка обеспечена не была. Как правило, проектировщики базы данных сами следили за тем, чтобы у всех таблиц были первичные ключи; в самих СУБД не было возможности задать для таблицы первичный ключ. И только СУБД DB2 Version 2, появившаяся в апреле 1988 года, была первым коммерческим SQL-продуктом с поддержкой первичных ключей. После этого подобная поддержка была добавлена в стандарт ANSI/ISO, и сегодня практически все СУРБД предоставляют такую возможность.
Взаимоотношения
Одним из отличий реляционной модели от ранних моделей представления данных было то, что в ней отсутствовали явные указатели, такие как использовавшиеся для реализации отношений "предок-потомок" в иерархической модели данных. Однако вполне очевидно, что такие отношения существуют и в реляционных базах данных. Например, в нашей учебной базе данных каждый из служащих закреплен за конкретным офисом, поэтому ясно, что между строками таблицы OFFICES и таблицы SALESREPS
Как следует из рис. 9, ответ на этот вопрос должен быть отрицательным. На рисунке изображено несколько строк из таблиц OFFICES и SALESREPSREP_OFFICE таблицы SALESREPSOFFICE таблицы OFFICES. Узнать, в каком офисе работает Мери Джонс, можно, определив значение столбца REP_OFFICE в строке таблицы SALESREPSOFFICES строку с таким же значением в столбце OFFICE (это строка для офиса в Нью-Йорке). Таким же образом, чтобы найти всех служащих нью-йоркского офиса, следует запомнить значение столбца OFFICE для Нью-Йорка (число 11), а потом просмотреть таблицу SALESREPSREP_OFFICE которых содержится число 11 (это строки для Мери Джонс и Сэма Кларка).
Отношение "предок-потомок", существующее между офисами и работающими в них людьми, в реляционной модели не утеряно; просто оно реализовано в виде одинаковых значений данных, хранящихся в двух таблицах, а не в виде явного указателя. Таким способом реализуются все отношения, существующие между таблицами реляционной базы данных. Одним из главных преимуществ языка SQL является возможность извлекать связанные между собой данные, используя эти отношения.

Рис. 9. Отношение “предок-потомок” в реляционной базе данных
Внешние ключи
Столбец одной таблицы, значения в котором совпадают со значениями столбца, являющегося первичным ключом другой таблицы, называется внешним ключом (foreign key). На рис. 9 столбец REP_ OFFICE представляет собой внешний ключ для таблицы OFFICES. Хотя столбец REP_ OFFICE и находится в таблице SALESREPSOFFICE, который является первичным ключом таблицы OFFICES. Первичный и внешний ключи создают между таблицами, в которых они содержатся, такое же отношение "предок- потомок", как и в иерархической базе данных.
Внешний ключ, как и первичный, тоже может представлять собой комбинацию столбцов. Фактически внешний ключ всегда будет составным (состоящим из нескольких столбцов), если он ссылается на составной первичный ключ в другой таблице. Очевидно, что количество столбцов и их типы данных в первичном и внешнем ключах совпадают.
Если таблица связана с несколькими другими таблицами, она может иметь несколько внешних ключей. На рис. 10 показаны три внешних ключа таблицы ORDERS из учебной базы данных:
- столбец OUST является внешним ключом для таблицы
CUSTOMERSи связывает каждый заказ с клиентом, разместившим его; - столбец
REPявляется внешним ключом для таблицыSALESREPS - столбцы
MFRиPRODUCTпредставляют собой составной внешний ключ для таблицыproducts, который связывает каждый заказ с заказанным товаром.

Рис. 10. Множественные отношения “предок-потомок” в реляционной базе данных
Отношения "предок-потомок", созданные с помощью трех внешних ключей в таблице ORDERS, могут показаться вам знакомыми. И действительно, это те же самые отношения, что и в сетевой базе данных, представленной на рис. 4. Как показывает данный пример, реляционная модель данных обладает всеми возможностями сетевой модели по части выражения сложных отношений.
Внешние ключи являются фундаментальной частью реляционной модели, поскольку реализуют отношения между таблицами базы данных. К сожалению, как и в случае с первичными ключами, поддержка внешних ключей отсутствовала в первых реляционных СУБД. Она была реализована в DB2 Version 2, а затем добавлена в стандарт ANSI/ISO и теперь имеется во всех основных коммерческих СУБД.
Двенадцать правил Кодда для реляционных баз данных
Когда в средине 1980-х годов реляционная модель стала очень популярной, почти все производители СУБД стали добавлять слово "реляционный" в описание своих продуктов. Но ряд из них был не более чем тонким слоем SQL-подобного языка на поверхности сетевой или иерархической базы данных. Некоторые реализовывали только рудиментарную табличную структуру, даже не пытаясь реализовать язык запросов. Вскоре вопрос так что же такое настоящая реляционная база данных? стал подниматься все чаще и чаще, а производители СУБД стали утверждать, что их продукты "реляционнее", чем продукты их конкурентов.
В 1985 году Тед Кодл (чья статья 15-летней давности определила реляционную модель данных) задался этим вопросом и ответил на него в журнале Computerworld (Is Your DBMS Really Relational? (Действительно ли ваша СУБД реляционная?, 14.10.1985) и Does Your DBMS Run By the Rules? (Работает ли ваша СУБД по правилам?, 21.10.1985)). Здесь он изложил двенадцать правил, которым должна соответствовать настоящая реляционная база данных.
- Правило представления информации. Вся информация в реляционной базе данных должна быть представлена исключительно на логическом уровне и только одним способом — в виде значений, содержащихся в таблицах.
- Правило гарантированного доступа. Логический доступ ко всем и каждому элементу данных (атомарному значению) в реляционной базе данных должен обеспечиваться путем использования комбинации имени таблицы, значения первичного ключа и имени столбца.
- Систематическая трактовка значения NULL. В настоящей реляционной базе данных должна быть реализована полная поддержка значений NULL (которые отличаются от строки символов нулевой длины, строки пробельных символов, а также от нуля или любого другого числа), которые используются для представления отсутствующей и неприменимой информации систематическим образом независимо от типа этих данных.
- Правило динамического каталога, основанного на реляционной модели. Описание базы данных на логическом уровне должно быть представлено в том же виде, что и обычные данные, чтобы пользователи, обладающие соответствующими правами, могли работать с ним с помощью того же реляционного языка, который они применяют для работы с основными данными.
- Правило исчерпывающего подъязыка данных. Реляционная система может поддерживать несколько языков и режимов взаимодействия с пользователем. Однако должен существовать по крайней мере один язык, инструкции которого можно представить в виде строк символов в соответствии с некоторым точно определенным синтаксисом и который в полной мере поддерживает все следующие элементы:
- определение данных;
- определение представлений;
- обработку данных (интерактивную и программную);
- ограничения целостности данных;
- авторизацию;
- границы транзакций (начало, фиксацию и откат).
- Правило обновления представлений. Все представления, которые теоретически можно обновить, должны быть доступны для обновления системой.
- Правило высокоуровневого добавления, обновления и удаления. Операции вставки, обновления и удаления должны применяться к отношению в целом.
- Правило физической независимости данных. Прикладные программы и утилиты для работы с данными на логическом уровне должны оставаться неизменными при любых изменениях способов хранения данных или методов доступа к ним.
- Правило логической независимости данных. Прикладные программы и утилиты для работы с данными должны на логическом уровне оставаться нетронутыми при внесении в базовые таблицы любых изменений, которые теоретически позволяют сохранить нетронутыми содержащиеся в этих таблицах данные.
- Правило независимости контроля целостности. Должна существовать возможность определять условия целостности, специфичные для конкретной реляционной базы данных, на подъязыке этой базы данных и хранить их в каталоге, а не в прикладной программе.
- Правило независимости распространения. Реляционная база данных должна быть переносима не только в пределах системы, но и по сети.
- Правило согласования языковых уровней. Если в реляционной системе есть низкоуровневый язык (обрабатывающий одну запись за один раз), то он не должен иметь возможность обходить правила и условия целостности данных, выраженные на реляционном языке высокого уровня (обрабатывающем несколько записей за один раз).
Хотя дискуссии по этому вопросу давно завершились, эти 12 правил интересны, как минимум, с исторической точки зрения, поскольку они раз и навсегда разрешили все вопросы и представляют собой хорошее неформальное определение реляционной базы данных. Правило 1 напоминает неформальное определение реляционной базы данных, приведенное ранее; остальные правила уточняют и дополняют его.
Правило 2 указывает на роль первичных ключей при поиске информации в базе данных. Имя таблицы позволяет найти требуемую таблицу, имя столбца — требуемый столбец, а первичный ключ — строку, содержащую искомый элемент данных. Правило 3 требует, чтобы отсутствующие данные можно было представить с помощью значения NULL.
Правило 4 гласит, что реляционная база данных должна описывать сама себя. Другими словами, база данных должна содержать набор системных таблиц, описывающих структуру самой базы данных.
Правило 5 требует, чтобы СУБД использовала язык реляционной базы данных, например SQL, хотя явно SQL в правиле не упомянут. Такой язык должен поддерживать все основные функции СУБД, а не только выборку данных.
Правило 6 касается представлений, которые являются виртуальными таблицами, позволяющими показывать различным пользователям различные фрагменты структуры базы данных.
Правило 7 акцентирует внимание на том, что реляционные базы данных по своей природе ориентированы на работу с множествами. Оно требует, чтобы операции добавления, удаления и обновления можно было выполнять над множествами строк. Это правило предназначено для того, чтобы запретить реализации таких СУБД, в которых поддерживаются только операции над одной строкой.
Правила 8 и 9 изолируют пользователей и прикладные программы от низкоуровневой реализации базы данных и даже от изменений в структуре таблиц.
Правило 10 гласит, что язык базы данных должен поддерживать возможность определения ограничений на вводимые данные и изменения базы данных, которые могут быть выполнены.
Правило 11 говорит о том, что язык базы данных должен обеспечивать возможность работы с распределенными данными, расположенными в различных компьютерных системах.
И наконец, правило 12 предотвращает использование других средств работы с базой данных, помимо ее подъязыка, поскольку это может нарушить ее целостность.
Заключение
SQL основан на реляционной модели данных, в которой данные организованы в виде коллекции таблиц.
- Каждая таблица имеет уникальное имя.
- В каждой таблице есть один или несколько именованных столбцов, расположенных в определенном порядке слева направо.
- В каждой таблице есть нуль или более строк, каждая из которых содержит одно значение данных в каждом столбце; строки в таблице не упорядочены.
- Все значения данных в одном столбце имеют одинаковый тип данных и входят в набор допустимых значений, который называется доменом столбца.
Отношения между таблицами реализуются с помощью содержащихся в них данных. В реляционной модели данных для представления этих отношений используются первичные и внешние ключи.
- Первичным ключом может быть столбец или комбинация столбцов таблицы, значения которых уникальным образом идентифицируют каждую строку таблицы. У таблицы есть только один первичный ключ.
- Внешним ключом является столбец или группа столбцов таблицы, значения которых совпадают со значениями первичного ключа другой таблицы. Таблица может содержать несколько внешних ключей, связывающих ее с одной или несколькими другими таблицами.
- Пара "первичный ключ-внешний ключ" создает отношение "предок- потомок" между таблицами, содержащими их.



