
Database clustering often solves the problems posed by cloud computing on structured data processing. However, conventional data processing methods using clusters are often unable to meet the demands of huge amounts of data generated by social media and machine data. Structured data processing requires proper schema definitions and a prebuilt data model. Enormous amounts of data with high velocity (often referred to as web scale) require totally different types of clusters, with high storage and computing capacity on demand.
Another challenge posed by web scale processing is the variety of data (such as text, images, audio, video, and geographic data) with very limited time to process. Often, the data is processed when it is in motion. Some of this data is never stored on disk; it lives and dies in the wire. Database clusters often process data at rest (meaning the data is stored on disk before/after processing) and are not properly equipped to process the web scale data and data in motion.
Internet and social media corporations were the first to bite the bullet and required a new data processing technique. Apache Hadoop is one of the frameworks on which massive volumes of unstructured data (also known as big data) is processed.
Architecture of Hadoop
The section provides a simple overview of the architecture of Apache Hadoop. The discussion here does not get into the nitty-gritty details. The storage is local to the nodes; however, the software layer, which integrates the storage from member nodes, pools the storage from all the nodes and exposes it as one logical storage unit that can be accessed from any of the nodes.
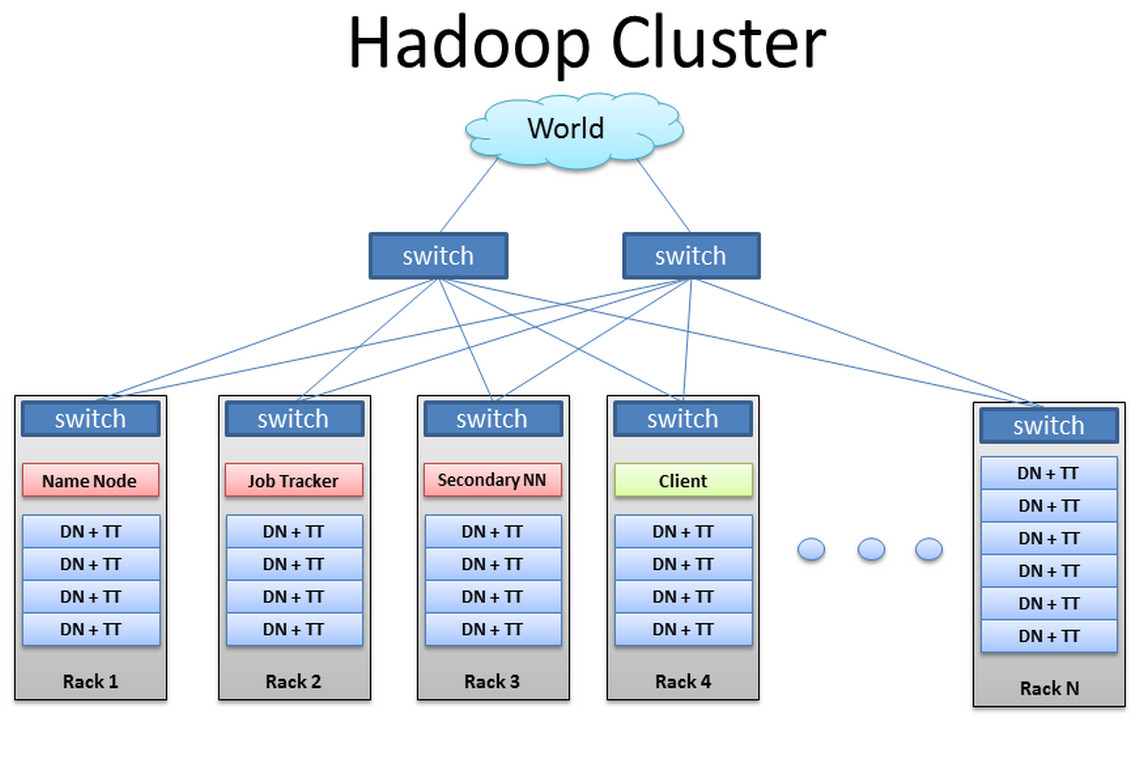
Hadoop clusters are architecturally similar to the typical shared nothing architecture, with the nodes having their own local disks. The file system, which runs on top of the Hadoop, is known as Hadoop Distributed File System (HDFS), which is a distributed, scalable, and portable file system. A Hadoop cluster basically has a single name node (which serves as the master) and a cluster of data nodes, although redundancy options are available for the name node due to its criticality.
The HDFS layer pools all the local storage and builds one large logical file system to store the data. Figure 1 shows the architecture of a Hadoop cluster. The following are the fundamental principles of Hadoop clustering:

FIGURE 1. Architecture of Hadoop clusters
- Hadoop infrastructures use commodity-class hardware, and the hardware is fully expected to fail. Hardware component failures are tolerated well, since the software masks the hardware failures.
- Moving computation is cheaper than moving data compute nodes and only the result is transferred to compute nodes. Hadoop does this by sending the code to the nodes with the data (Datanodes in Hadoop parlance) and running tasks on those nodes. Hadoop always attempts to schedule computation as close to the data as possible.
Because the hardware infrastructure is built using commodity-class hardware, the disks are expected to fail. To overcome the challenge of lost data, files that are coming to Hadoop clusters are replicated to three different nodes (and they are configurable). The replication algorithm is implemented in such a way that no two copies of the replicas are stored in the same node. This is called node awareness. Also, when rack awareness is configured, the three copies are not all stored in the same rack. This protects against node failure and rack failure.