 Clustering enables multiple servers to be treated as a part of single cluster of servers and provides high availability solutions to the application environment. Clustering can help in increased performance and ensures greater scalability and reduced costs through optimized utilization of participant servers. The backbone of cluster lies on the server, network, and storage capacities along with the operating system-level clustering software environment. A cluster framework ensures applications and/or database environments start with defined dependencies and ensures successful failover or failback initiated by monitoring triggers or through manual intervention. Cluster framework also ensures an easy scalability through addition or removal of servers, known as cluster nodes, to the cluster.
Clustering enables multiple servers to be treated as a part of single cluster of servers and provides high availability solutions to the application environment. Clustering can help in increased performance and ensures greater scalability and reduced costs through optimized utilization of participant servers. The backbone of cluster lies on the server, network, and storage capacities along with the operating system-level clustering software environment. A cluster framework ensures applications and/or database environments start with defined dependencies and ensures successful failover or failback initiated by monitoring triggers or through manual intervention. Cluster framework also ensures an easy scalability through addition or removal of servers, known as cluster nodes, to the cluster.
OS Clustering Architecture
A cluster architecture is a group of two or more computers/server/hosts/nodes built with fault tolerant components and connected using network, storage, and software components to make a single virtual or logical server, available anytime in either of the physical computer/server/hosts or nodes. On the other view, cluster framework is an architecture that allows systems to combine together as an aggregated host, a way of harnessing of multiple processors to work in parallel, sharing memory across multiple hosts So cluster is not just a solution to availability in the form of failover and fault tolerant services but also stretches to scalability and performance.
A high-level two-node cluster architecture is explained in Figure 1.
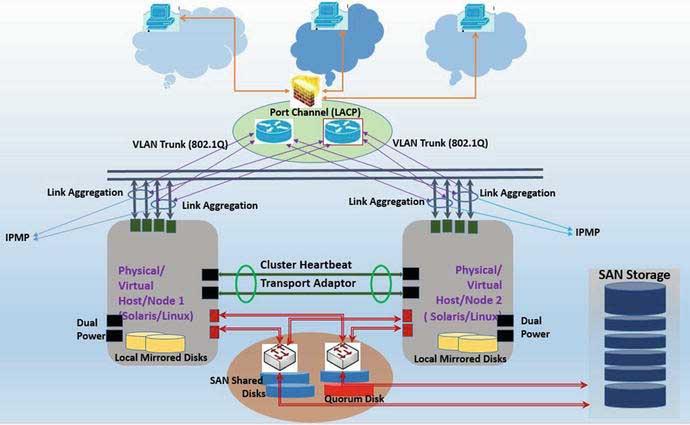
As shown in the above diagram, the basic design of a cluster framework consists of two or more cluster hosts/nodes – physical or virtual, Operating System, supported cluster software, network, and shared storage (SAN or NAS shared storage). The figure also shows some other aspects: redundancy design to support the cluster framework (like dual power supplies, Link Aggregation, and IPMP configuration).
Cluster Network
Network configurations should be set up with both server-level network card redundancy as well as having a redundant switch for failover. Network ports be configured to provide maximum redundancy allowing network survival due to the failure of the card at the server end or a failure of the switch.
A core component of cluster configuration is cluster heartbeat (transport interconnect). Cluster heartbeat plays a critical role for keeping a cluster alive. Heartbeat interconnects are used for pinging each cluster node, ensuring they are part of the cluster.
The other network component of cluster configuration is the core network (or company’s internal network) that is used for communication between cluster resources (e.g., across applications or communications from application to database).
And the last component of the cluster network configuration is the communication to or from end users connecting from a public network to the back-end application under cluster configuration.
Redundant cluster network configuration is done differently for different kinds of configuration requirements. One of the configurations is to aggregate multiple network ports at the host level. The technology used for aggregating ports is either link aggregation (UNIX) or interface bonding (Linux) or NIC teaming. Link aggregation or interface bonding provides network redundancy/load balancing as well as providing combined bandwidth to the virtual network pipe created out of bonding. At the network configuration level, Port Channel – LACP will need to be configured to support the link aggregation configuration at the server end.
Additionally, IP Multipathing can be set up either on top of link aggregation or configured independently to further support the network redundancy via failover policies adopted (active/active or active/standby).
These will specifically be explained on the specific clustering framework (for Oracle Solaris Cluster or Veritas Cluster).
Cluster Storage
For the storage configuration, the cluster environment is set up by having both SAN fabric and host storage port-level redundancy. Cluster storage is a shared storage carved from SAN- or NAS-based redundant storage environments. Cluster storage LUNs (Logical Units), also known as multihome disks, are presented to all participant cluster nodes and made active/standby, based on which node is the active cluster node. Software MPXIO is used to create single virtual paths out of multiple redundant paths created out of SAN fabric and host storage ports. Ideally, disks pulled out of SAN storage are raid controlled and provide sufficient disk redundancy, although to have better resilient configuration, it’s better to obtain storage from two separate storage appliances.
Quorum Device
Cluster uses quorum voting to prevent split brain and amnesia. Quorum determines the number of failures of node a cluster can sustain and for any further failure cluster must panic. Quorum disk is used for supporting the Cluster quorum.
Cluster Split Brain
Split brain occurs when cluster interconnects between cluster nodes break. In that case, each broken cluster node partitions to form a separate cluster and tries to bring up cluster services simultaneously and access the respective shared storage leading to data corruption. Additionally, it might duplicate network addresses, as each new partitioned clusters might own the logical hosts created as a part of the cluster.

Figure 2. Split Brain
Quorum disk resolves this by ensuring a partition cluster with the majority of votes will be allowed to survive (like the above cluster made of Node1 and Node2) and other cluster partition (Node3) will be forced to panic and fence the node from disks to avoid data corruption.
Cluster Amnesia
As stated in Oracle Solaris documentation, “Amnesia is a failure mode in which a node starts with the stale cluster configuration information. This is a synchronization error due to the cluster configuration information not having been propagated to all of the nodes.”
Cluster amnesia occurs when cluster nodes leave the cluster due to technical issues. Cluster uses the cluster configuration database to keep this updated across all cluster nodes. Although for the nodes going down due to technical reasons, it will not have an updated cluster repository. When all cluster nodes are restarted, the cluster with the latest configuration should be started first, meaning the cluster node brought down last should be brought up first. But if this is not done, the cluster itself will not know which cluster node contains the right cluster repository and may lead to a stale cluster configuration database.
Figure 3 below explains further the process of cluster amnesia.

Figure 3. Amnesia
To avoid this, cluster quorum guarantees at the time of cluster reboot that it has at least one node (either quorum server or quorum disk) with the latest cluster configuration.