
Oracle Clusterware is a required component for an Oracle RAC database and provides the essential infrastructure to run the database. In an Oracle Database RAC database, the clustering software is integrated into the relational database management system (RDBMS) kernel.
Oracle Clusterware manages not only the database but also other resources necessary for the functioning of the cluster, such as the Virtual Internet Protocol (VIP) addresses, listeners, and database services. Oracle Clusterware together with Oracle’s Automatic Storage Management is known as Oracle Grid Infrastructure.
NOTE
Although Oracle Clusterware is all you need for most operating systems in order to create and manage an Oracle RAC database, if your database applications need third-party vendor clusterware, you can use that clusterware, so long as it’s certified by Oracle for use with Oracle Clusterware.
Here are the major components of Oracle RAC:
- A shared disk system
- Oracle Clusterware
- Cluster interconnects
- Oracle kernel components
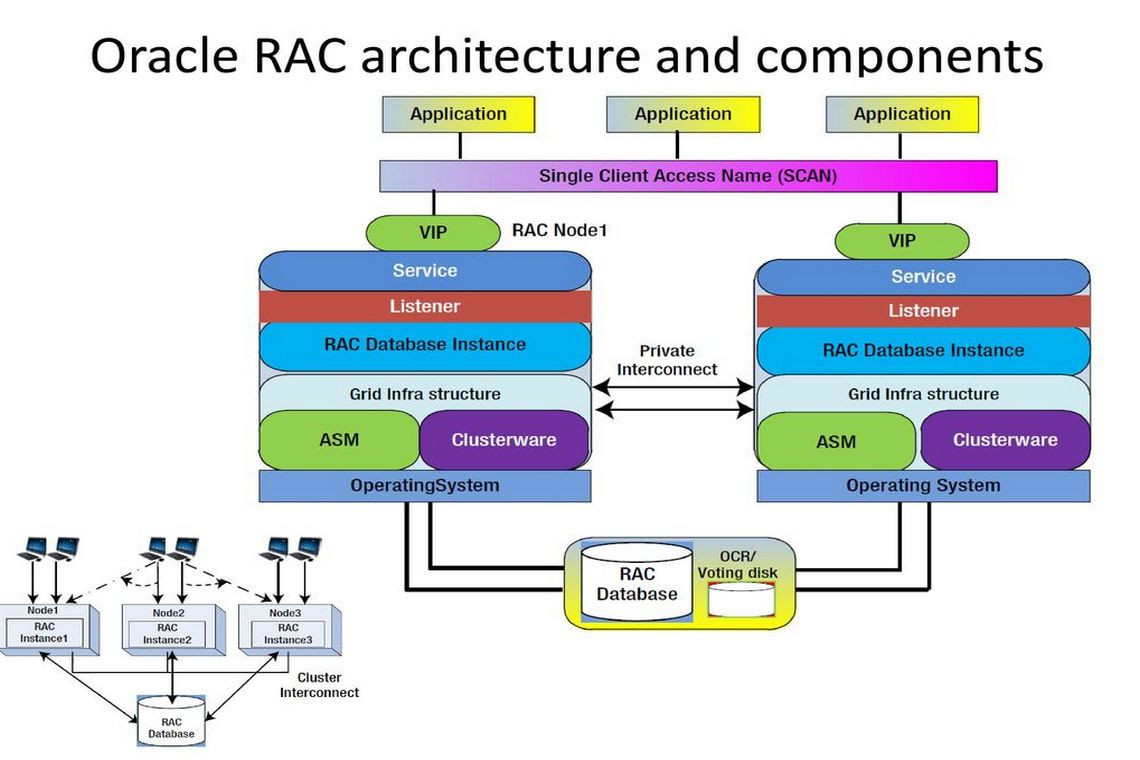
Figure 1 shows the basic architecture.
 FIGURE 1. Oracle 12c architecture
FIGURE 1. Oracle 12c architecture
Shared Disk System
Scalable shared storage is a critical component of an Oracle RAC environment. Traditionally, storage was attached to each individual server using SCSI (Small Computer System Interface) or SATA (Serial ATA) interfaces local to the hosts. Today, more flexible storage is popular and is accessible over storage area networks (SANs) or network-attached storage (NAS) using regular Ethernet networks. These new storage options enable multiple servers to access the same set of disks through a network, simplifying provisioning of storage in any distributed environment. SANs represent the evolution of data storage technology to this point.
Traditionally, in single-instance client/server systems, data was stored on devices either inside or directly attached to the server. This kind of storage is known as directly attached storage (DAS). Next in the evolutionary scale came network-attached storage, which removed the storage devices from the server and connected them to the network. Storage area networks take the principle a step further by allowing storage devices to exist on their own separate networks and communicate with each other over very fast media, such as a high-speed Fibre Channel network. Users can gain access to these storage devices through server systems that are connected to the local area network (LAN) and SAN.
In shared storage, database files should be equally accessible to all the nodes concurrently. Generic file systems do not allow disks to be mounted in more than one system. Also, the regular UNIX file systems (UFS) do not allow the files to be shared among the nodes because of the obvious file-locking (inode locks) issues and the unavailability of a coherent file system cache. One option is to use the Network File System (NFS), but it is unsuitable because it relies on a single host (which mounts the file system) and for performance reasons. Because the disks in such an implementation are attached to one node, all the write requests must go through that particular node, thus limiting the scalability and fault tolerance. The total available I/O bandwidth is dependent on the bandwidth provided by that single host through which all I/O can be serviced. Because that node may become a single point of failure (SPOF), it is another threat for the high availability (HA) architecture.
The choice of file system is critical for Oracle RAC deployment. Traditional file systems do not support simultaneous mounting by more than one system. Therefore, you must store files in either raw volumes without any file system or on a file system that supports concurrent access by multiple systems.
Oracle RAC uses a “shared everything” architecture, which means that all datafiles, control files, redo log files, and SPFILEs must be stored on cluster-aware shared disks. Storing these files in shared storage ensures that all the database instances that are part of a cluster are able to access the various files necessary for instance operation.
In prior releases, Oracle allowed you to use raw devices as one way to provide the shared storage for Oracle RAC. However, in Oracle Database 12c, raw devices aren’t certified for use in a RAC environment. Instead, you must use one of the following Oracle-supported cluster storage solutions:
- Automatic Storage Management (ASM) ASM is a portable, dedicated, and optimized cluster file system for Oracle database files. ASM is the only supported storage if you use Oracle Standard Edition with Oracle RAC. Oracle recommends ASM as a storage option for Oracle RAC environments.
- Cluster File System One or more cluster file systems can be used to hold all Oracle RAC datafiles. Oracle recommends the use of the Oracle Cluster File System (OCFS). Alternatively, you can use a certified third-party cluster file system such as IBM GPFS, which works only on IBM AIX systems. Cluster file systems aren’t widely used, so we will not be discussing them in great detail.
Oracle Clusterware
Oracle Clusterware software provides the underlying infrastructure that makes it possible for Oracle RAC to function. It is Oracle Clusterware that manages entities such as databases, listeners, services, and virtual IP addresses, which are referred to as resources in Oracle Clusterware parlance. Oracle Clusterware uses processes or services that run on the individual nodes of the cluster to provide the high availability capabilities for a RAC database. It enables nodes to communicate with each other and forms the cluster that makes the nodes work as a single logical server.
Oracle Clusterware, which is integrated into the Oracle Grid Infrastructure, consists of several background processes that perform different functions to facilitate cluster operations. Oracle Clusterware is a mandatory piece of software required to run the Oracle RAC option. It provides the basic clustering support at the OS level and enables Oracle software to run in the clustering mode.
In the current release, Oracle has formally divided the Oracle Clusterware technology stack into two separate stacks. The Cluster Ready Services (CRS) stack is the upper technology stack and the Oracle High Availability Services (OHAS) stack constitutes the foundational or lower layer. Let’s review the processes in each of the two technology stacks.
The Cluster Ready Services Stack
The CRS stack is the upper-level stack in Oracle Clusterware, and depends on the services provided by the lower-level High Availability Cluster Service stack. The CRS stack is comprised of the following key services:
- CRS This is the key service responsible for managing Oracle RAC high availability operations. The CRS daemon, named CRSd, manages the cluster’s start, stop, and failover operations. CRS stores its configuration data in the Oracle Cluster Registry (OCR).
- CSS The CSS service manages the cluster’s node membership and runs as the ocssd.bin process in a Linux-based system.
- EVM The Event Manager service (EVMd) manages FAN (Fast Application Notification) server callouts. FAN provides information to applications and clients about cluster state changes and Load Balancing Advisory events for instances services and nodes.
- Oracle Notification Service The ONSd daemon represents the Oracle Notification Service, which, among other things, helps publish the Load Balancing Advisory events.
The key background processes and services that comprise Oracle Clusterware are CRSd, OCSSd, EVMd, and ONSd. The operating system’s init daemon starts these processes by using the Oracle Clusterware wrapper scripts, which are installed by Oracle Universal Installer during the installation of Oracle Clusterware. Oracle installs three wrapper scripts: init.crsd, init.evmd, and init.cssd. These are configured with the respawn action so that they will be restarted whenever they fail—except that the init.cssd wrapper script is configured with the fatal parameter, causing the cluster node to reboot to avoid any possible data corruption.
Table 1 summarizes the details of the key Oracle Clusterware processes and their functionality.

TABLE 1. CRS Processes and Functionalities
Cluster Ready Services (CRSd) Cluster Ready Services, which is represented by the CRSd process (or the CRSd daemon), manages all operations for all cluster resources (databases, listeners, and so on), such as starting and stopping the resources. The CRSd process also monitors all resources while they’re running and can automatically restart any failed services.
Failure or death of the CRSd can cause node failure, and it automatically reboots the nodes to avoid data corruption because of possible communication failure among the nodes. The CRSd runs as the superuser root in the UNIX platforms and runs as a background service in Microsoft Windows platforms.
The Cluster Ready Services daemon process is spawned by the init.crsd wrapper script, provides the high availability framework for Oracle Clusterware, and manages the states of cluster resources by starting, stopping, monitoring, and relocating the failed cluster resources to the available cluster nodes within the cluster. A cluster resource can be a network resource such as a virtual IP, database instance, listener, database, or any third-party application, such as a web server. The CRSd process retrieves the cluster resource’s configuration information stored in the Oracle Cluster Registry (OCR) before taking any action on the cluster resource. CRSd also uses OCR to maintain the cluster resource profiles and statuses. Every cluster resource has a resource profile, which is stored in the Oracle Cluster Registry.
CRS is installed and run from a different Oracle home, known as GRID_HOME, that is independent from ORACLE_HOME. Here’s a list of the key functions performed by CRS:
- CRSd manages resources such as starting and stopping the services and failovers of the application resources. It spawns separate processes to manage application resources.
- CRSd has two modes of running during startup and after a shutdown. During a planned clusterware startup, it is started in reboot mode. It is started in restart mode after an unplanned shutdown. In reboot mode, CRSd starts all the resources under its management. In restart mode, it retains the previous state and returns the resources to their previous states before shutdown.
- CRS manages the Oracle Cluster Registry (OCR) and stores the current known state in the OCR.
- CRS runs as root on UNIX and LocalSystem on Windows and automatically restarts in case of failure.
- CRS requires a public interface, private interface, and the virtual IP (VIP) for operation. Public and private interfaces should be up and running and should be pingable from each other before the CRS installation is started. Without this network infrastructure, CRS cannot be installed.
How Cluster Ready Services (CRS) Works The Oracle Grid Infrastructure uses CRS for interaction between the OS and the database. CRS is the background engine for the Oracle 12c RAC high availability framework, which provides the standard cluster interface for all platforms. In this discussion, we use the Oracle Grid Infrastructure and Oracle Clusterware interchangeably.
The Oracle Grid Infrastructure must be installed in a separate Oracle home before the standard RAC installation. This separate Oracle home is known as GRID_HOME. The Oracle Grid Infrastructure is a mandatory component for Oracle 12c RAC.
When Oracle Clusterware is installed on the cluster where third-party clusterware is integrated, CRS relies on the vendor clusterware for the node membership functionality and just manages Oracle services and resources. CRS manages the node membership functionality along with managing regular RAC-related resources and services.
Cluster Membership Decisions Oracle Clusterware contains logic for determining the health of other nodes of the cluster and whether they are alive. After a certain period of inactivity of a node, Oracle Clusterware declares the node dead and evicts it. If a new node needs to be added, it is allowed to join immediately.
Resource Management Frameworks Resources represent applications or system components (both local and remote to the cluster) whose behavior is wrapped and monitored by a cluster framework. Thus, the application or system component becomes highly available. Correct modeling of resources stipulates that they must be managed by only one cluster framework. Having multiple frameworks managing the same resource can produce undesirable side effects, including race conditions in start/stop semantics.
Consider an example in which two cluster frameworks manage the same shared storage, such as a raw disk volume or cluster file system. In the event that the storage component goes down, both frameworks may compete in trying to bring it back up and may decide to apply totally different recovery methods (for example, restarting vs. using a notification for human intervention, or waiting before restarting vs. retrying in a tight loop).
In the case of single application resources, both frameworks may even decide to fail over the component to a totally different node. In general, clusterware software systems are not prepared to handle resources that are managed by multiple HA frameworks.
Starting and Stopping Oracle Clusterware When a node fails, Oracle Clusterware is brought up at boot time via the init daemon (on UNIX) or Windows Service Management (on Windows). Therefore, if the init process fails to run on the node, the OS is broken and Oracle Clusterware does not start.
You can start, stop, enable, and disable Oracle Clusterware with the following commands (which must be run as the superuser):
crsctl stop crs # stops Oracle Clusterware
crsctl start crs # starts Oracle Clusterware
crsctl enable crs # enables Oracle Clusterware
crsctl disable crs # disables Oracle Clusterware
The commands to start and stop Oracle Clusterware are asynchronous, but while it is stopped, a small wait time may occur before control is returned. Only one set of CRSs can be run on one cluster. Adding the -cluster option to these commands makes them global across the RAC environment.
Oracle Clusterware APIs are documented, and customers are free to use these programmatic interfaces in their custom and non-Oracle software to operate and maintain a coherent cluster environment. You must use SRVCTL to start and stop Oracle resources named with “ora.” Oracle does not support third-party applications that check Oracle resources and take corrective actions on those resources. Best practice is to leave Oracle resources controlled by Oracle Clusterware. For any other resource, either Oracle or the vendor clusterware (not both) can manage it directly.
The Clusterware Startup Process The Oracle High Availability Service daemon (OHASd) starts all other Oracle Clusterware daemons. During installation of Oracle Grid Infrastructure, Oracle adds the following entry into the /etc/inittab file:
hl:35:respawn:/etc/init.d/init.ohasd run >/dev/null 2>&1 </dev/null
The /etc/inittab file executes the /etc/init.d/init.ohasd control script with the run argument, which spawns the ohasd.bin executable. The cluster control files are stored at the location /etc/oracle/scls_scr/<hostname>/root. The /etc/init.d/init.ohasd control script starts the OHASd based on the value of the ohasdrun cluster control file. The value restart causes Oracle to restart the crashed OHASd using $GRID_HOME/bin/ohasd restart. The value stop indicates a scheduled shutdown of the OHASd, and the value reboot causes Oracle to update the ohasdrun file with a value of restart so that Oracle will restart the crashed OHASd.
The OHASd daemon uses cluster resources to start other Clusterware daemons. The OHASd daemon will have one cluster resource for each Clusterware daemon, and these resources are stored in the Oracle Local Registry.
Agents help manage the Clusterware daemons, by performing actions such as starting, stopping, and monitoring the Clusterware daemons. The four main agents are oraagent, orarootagent, cssdagent, and cssdmonitor. These agents perform start, stop, check, and clean actions on their respective Clusterware daemons.
So, to put everything into context, the OHASd daemon will start all other Clusterware daemons. Once these are started, OHASd will start the daemon resources, and then the daemon resources using their respective agents will start the underlying Clusterware agents.
Oracle Cluster Registry Oracle Clusterware uses the Oracle Cluster Registry to store the metadata, configuration, and state information of all the cluster resources defined in Oracle Clusterware. Oracle Cluster Registry (OCR) must be accessible to all nodes in the cluster, and Oracle Universal Installer will fail to install all nodes in the installer that do not have proper permissions to access the Oracle Cluster Registry files, which are binary files and cannot be edited by any other Oracle tools. The OCR is used to bootstrap CSS for port information, nodes in the cluster, and similar information.
The Cluster Synchronization Services daemon (CSSd) updates the OCR during cluster setup, and once the cluster is set up, OCR is used for read-only operations. Exceptions are any change in a resource status that triggers an OCR update, services going up or down, network failovers, ONS and a change in application states, and policy changes.
OCR is the central repository for CRS and it stores details about the services and status of the resources. OCR is the registry equivalent of Microsoft Windows, which stores name/value pairs of information, such as resources that are used to manage the resource equivalents by the CRS stack. Resources with the CRS stack are components that are managed by the CRS and need to store some basic demographic information about the resources—the good state, the bad state, and the callout scripts. All such information makes it into the OCR. The OCR is also used to bootstrap CSS for the port information, nodes in the cluster, and similar information. This is a binary file and cannot be edited by any other Oracle tools.
Oracle Universal Installer provides the option to mirror the OCR file during installation of Oracle Clusterware. Although this is important, it is not mandatory. The OCR file should be mirrored if the underlying storage does not guarantee continuous access to the OCR file. The mirror OCR file has the same content as the primary OCR file and must be housed on shared storage, such as a cluster file system or raw device.
Oracle stores the location of the OCR file in a text file called ocr.loc, which is located in different places depending on the operating system. For example, on Linux-based systems the ocr.loc file is placed under the /etc/oracle directory, and for UNIX-based systems the ocr.loc is placed in /var/opt/oracle. Windows systems use the registry key Hkey_Local_Machine\software\Oracle\ocr to store the location of the ocr.loc file.
Oracle Universal Installer (OUI) also uses OCR during installation time. All the CSS daemons have read-only access during startup. Oracle uses an in-memory copy of OCR on each cluster node to optimize the queries against the OCR by various clients, such as CRS, CSS, SRVCTL, NETCA, Enterprise Manager, and DBCA. Each cluster node has its own private copy of the OCR, but to ensure the atomic updates against the OCR, no more than one CRSd process in a cluster is allowed to write into the shared OCR file.
This master CRSd process refreshes the OCR cache on all cluster nodes. Clients communicate with the local CRSd process to access the local copy of the OCR and to contact the master CRSd process for any updates on the physical OCR binary file. OCR also maintains the dependency hierarchy and status information of the cluster resources defined within the cluster. For example, there is a service resource that cannot be started until the dependent database resource is up and running, and OCR maintains this information.
The Cluster Synchronization Services daemon (CSSd) updates OCR during the cluster setup. Once the cluster is set up, OCR will be used by read-only operations. During node additions and deletions, CSS updates the OCR with the new information. The CRS daemon will update the OCR about the status of the nodes during failures and reconfigurations. Other management tools such as NetCA, DBCA, and SRVCTL update the services information in the OCR as they are executed. OCR information is also cached in all nodes, and the OCR cache will benefit more of the read-only operations.
The OCR file is automatically backed up in the OCR location every four hours. These backups are stored for a week and circularly overwritten. The last three successful backups of OCR (a day old and a week old) are always available in the directory $ORA_CRS_HOME/cdata/<cluster name>. The OCR backup location can also be changed using the ocrconfig command-line utility.
You can also take a manual backup of the OCR binary file by executing the ocrconfig -manualbackup command, provided that Oracle Clusterware is up and running on the cluster node. The user running the ocrconfig command must have administrative privileges. The ocrconfig command can also be used to list the existing backups of the OCR and the backup location, as well as to change the backup location.
Oracle Local Registry The Oracle Local Registry (OLR) is similar to the Oracle Cluster Registry, but it only stores information about the local node. The OLR is not shared by other nodes in the cluster and is used by the OHASd while starting or joining the cluster.
The OLR stores information that is typically required by the OHASd, such as the version of Oracle Clusterware, the configuration, and so on. Oracle stores the location of the OLR in a text file named /etc/oracle/olr.loc. This file will have the location of the OLR configuration file $GRID_HOME/cdata/<hostname.olr>. Oracle Local Registry is similar to OCR in terms of internal structure because it stores information in keys, and the same tools can be used to either check or dump the data of OLR.
Voting Disk A voting disk is a shared disk that will be accessed by all the member nodes in the cluster during an operation. The voting disk is used as a central reference for all the nodes and keeps the heartbeat information between the nodes. If any of the nodes is unable to ping the voting disk, the cluster immediately recognizes the communication failure and evicts the node from the cluster group to prevent data corruptions. The voting disk is sometimes called a “quorum device” because the split-brain resolution is decided based on the ownership of the quorum device.
The voting disk manages the cluster membership and arbitrates the cluster ownership during communication failures between the nodes. Oracle RAC uses the voting disk to determine the active instances of the cluster, and inactive instances are evicted from the cluster. Because the voting disk plays a vital role, you should mirror it. If Oracle mirroring is not used for the voting disk, external mirroring should be used.
Voting is perhaps the most universally accepted method of arbitration. It has been used for centuries in many forms for contests, for selecting members of government, and so forth. One problem with voting is plurality—the leading candidate gains more votes than the other candidates, but not more than half of the total votes cast. Other problems with voting involve ties. Ties are rare, and the node contained in the master sub cluster will survive. Starting with the 11.2.0.2 release, we can evict the specific sub cluster that has the smaller number of nodes all the time rather than making a guess based on the voting map.
Occasionally, voting is confused with a quorum. They are similar but distinct. A vote is usually a formal expression of opinion or will in response to a proposed decision. A quorum is defined as the number, usually a majority of officers or members of a body, that, when duly assembled, is legally competent to transact business. Both concepts are important; the only vote that should ratify a decision is the vote of a quorum of members. For clusters, the quorum defines a viable cluster. If a node or group of nodes cannot achieve a quorum, they should not start services because they risk conflicting with an established quorum.
Cluster Synchronization Services (CSS) Cluster Synchronization Services, represented by the Oracle Cluster Synchronization Services daemon (OCSSd), manages the cluster configuration by specifying which nodes are members of the RAC cluster. OCSSd provides synchronization services among the nodes. It provides the access to the node membership and enables basic cluster services, including cluster group services and cluster locking. It can also run without integrating with vendor clusterware.
Failure of OCSSd causes the machine to reboot to avoid a “split-brain” situation (when all the links of the private interconnect fail to respond to each other, but the instances are still up and running; each instance thinks that the other instance is dead and tries to take over ownership). This is also required in a single instance if Automatic Storage Management (ASM) is used. OCSSd runs as the oracle user.
The OCSSd process is spawned by the init.cssd wrapper script, runs as a non-root operating system user with real-time priority, and manages the configuration of Oracle Clusterware by providing node cluster and group membership services. OCSSd provides these services via two types of heartbeat mechanisms: network heartbeat and disk heartbeat. The main objective of the network heartbeat is to check the viability of the Oracle cluster, whereas the disk heartbeat helps to identify the split-brain situation. Due to this fact, it is very important that OCSSd is always running; hence, the init.cssd wrapper script is configured with the fatal parameter. Failure of OCSSd causes the machine reboot to avoid a split-brain situation. This is also required in the single instance if Automatic Storage Management (ASM) is used.
The following list summarizes the functionalities of OCSSd:
- CSS provides basic Group Services support. Group Services is a distributed group membership system that allows applications to coordinate activities to achieve a common result.
- Lock Services provides the basic cluster-wide serialization locking functions. It uses the First In, First Out (FIFO) mechanism to manage locking.
- Node Services uses OCR to store data and updates the information during reconfiguration. It also manages the OCR data, which is otherwise static.
The cssdagent process is part of Oracle Synchronization Services, and its job is to continuously monitor the cluster to provide the I/O fencing solution for Oracle Clusterware. The prime objective of the cssdagent process is to identify potential cluster node hangs and to reboot any hanged node so that processes on that node cannot write to the storage. The cssdagent process is locked in memory and runs as a real-time process. It sleeps for a fixed time and runs as the root user. Failure of the cssdagent process causes the node to automatically restart.
The Event Manager Process The third key component in OCS is called the Event Management Logger, which runs the Oracle Event Manager daemon process EVMd. This daemon process spawns a permanent child process called evmlogger and generates the events when things happen. The evmlogger spawns new children processes on demand and scans the callout directory to invoke callouts.
The EVMd process receives the FAN events posted by clients and distributes the FAN events to the clients that have subscribed to them. The EVMd process will restart automatically on failure, and the death of the EVMd process does not halt the instance. The EVMd process runs as the oracle user.
Imagine an Oracle cluster composed of two cluster nodes: Node A and Node B. When Node B leaves the cluster, the OCSSd process on Node A posts a leave FAN event, which the EVMd process on Node A publishes to the CRSd process on Node A because the CRS process is the subscriber for the leave FAN event. Oracle provides the evmwatch and evmget utilities to view the FAN events in the standard output. These utilities are also useful to test the functionality of the EVMd process.
I/O Fencing
Fencing is an important operation that protects processes from other nodes modifying the resources during node failures. When a node fails, it needs to be isolated from the other active nodes. Fencing is required because it is impossible to distinguish between a real failure and a temporary hang. Therefore, we assume the worst and always fence (if the node is really down, it cannot do any damage; in theory, nothing is required. We could just bring it back into the cluster with the usual join process). Fencing, in general, ensures that I/O can no longer occur from the failed node.
Other techniques can be used to perform fencing. The most popular are reserve/release (R/R) and persistent reservation (SCSI3). SAN Fabric fencing is also widely used both by Red Hat Global File System (GFS) and Polyserv. Reserve/release by its nature works only with two nodes. (That is, one of the two nodes in the cluster upon detecting that the other node has failed will issue the reserve and grab all the disks for itself. The other node will commit suicide if it tries to do I/O in case it was temporarily hung. The I/O failure triggers some code to kill the node.)
In general, in the case of two nodes, R/R is sufficient to address the split-brain issue. For more than two nodes, the SAN Fabric fencing technique does not work well because it would cause all the nodes but one to commit suicide. In those cases, persistent reservation, essentially a match on a key, is used. In persistent reservation, if you have the right key, you can do I/O; otherwise, your I/O fails. Therefore, it is sufficient to change the key on a failure to ensure the right behavior during failure.
All of the Oracle clients that are I/O capable can be terminated by the CSS before it takes a node out, which avoids the I/Os from going through because they will be intercepted and not completed. Hence, the database will not treat those transactions as committed and errors will be returned to the app; for those that did get committed and did not make it to the datafiles, the database will recover them on startup of the same instance or another instance that is running.
Oracle Notification Services The Oracle Notification Services (ONS) process is configured during the installation of Oracle Clusterware and is started on each cluster node when CRS starts. Whenever the state of a cluster resource changes, the ONS process on each cluster node communicates with one another and exchanges the HA event information. CRS triggers these HA events and routes them to the ONS process, and then the ONS process publishes the HA event information to the middle tier. To use ONS on the middle tier, you need to install ONS on each host where you have client applications that need to be integrated with FAN. Applications use these HA events for various reasons, especially to quickly detect failures. The whole process of triggering and publishing the HA events is called Fast Application Notification (commonly known as FAN in the Oracle community). Alternatively, the HA events are called FAN events.
These FAN events alone are of no use until applications do not have the logic to respond to the FAN events published by the ONS process. The best way to receive and respond to these FAN events is by using a client that is tightly integrated with FAN, such as Java Database Connectivity (JDBC) Implicit Connection Cache, Universal Connection Pool for Java, or database resources. Using a user-defined callout script is another way to publish these FAN events to the AQ (Advance Queue) tables. FAN events contain important information such as the event type, reason, and status, and users can write their own callout scripts to act upon certain types of events instead of taking action on each FAN event.
In addition to the CRS, CSS, EVM and ONS services, the Oracle Clusterware Technology Stack also utilizes the following processes:
- Cluster Time Synchronization Services (CTSS) Performs time management tasks for the cluster.
- Grid Naming Service (GNS) If you choose to use GNS, the GNS services process is in charge of name resolution and it handles requests sent from DNS servers to the cluster nodes.
- Oracle Agent (oraagent) The oraagent process replaces the RACG process in Oracle 11.1 and supports Oracle-specific requirements.
- Oracle Root Agent (orarootagent) Lets the CRSd manage root-owned resources, such as the network.
The Oracle High Availability Services Technology Stack
The Oracle High Availability Services (OHAS) stack is the foundational layer of Oracle Clusterware and is responsible for supporting high availability in an Oracle RAC environment. The OHAS stack consists of the following key processes:
Cluster Logging Services (ologgerd) This process stores information it receives from the various nodes in a cluster in an Oracle Grid Infrastructure Management Repository, which is a default new Oracle 12c database named MGMTDB that’s automatically created for you when you create an Oracle 12c RAC database. In Oracle Grid Infrastructure 12.1.0.1, you had to choose if you wanted the installer to create the MGMTDB database. Starting with the Oracle Grid Infrastructure 12.1.0.2 release, this database is mandatory and is automatically installed. The database is created as a CDB, with a single PDB. This new database, which is a small Oracle 12c database, runs on only one of the nodes in an Oracle RAC cluster. Note that the ologgerd service will run on only one of the nodes in a cluster.
- Grid Plug and Play (GPNPd) This process manages the Grid Plug and Play profile and ensures that all nodes in a cluster have a consistent profile.
- Grid Interprocess Communication (GIPCd) This is a support daemon that underlies Redundant Interconnect Usage, which facilitates IP failover natively, without the need for tools such as bonding. This is also the underlying protocol used by the clusterware to communicate.
- Oracle Agent (oraagent) Not to be mistaken with the oraagent process on the CRS technology stack, this process also supports Oracle-specific requirements.
- Oracle Root Agent (orarootagent) This process is the counterpart to the similarly named agent process in the CRS technology stack and is meant to help manage root-owned services that run in the Oracle High Availability Services Technology stack layer. This process is required for running resources that need root-elevated privileges.