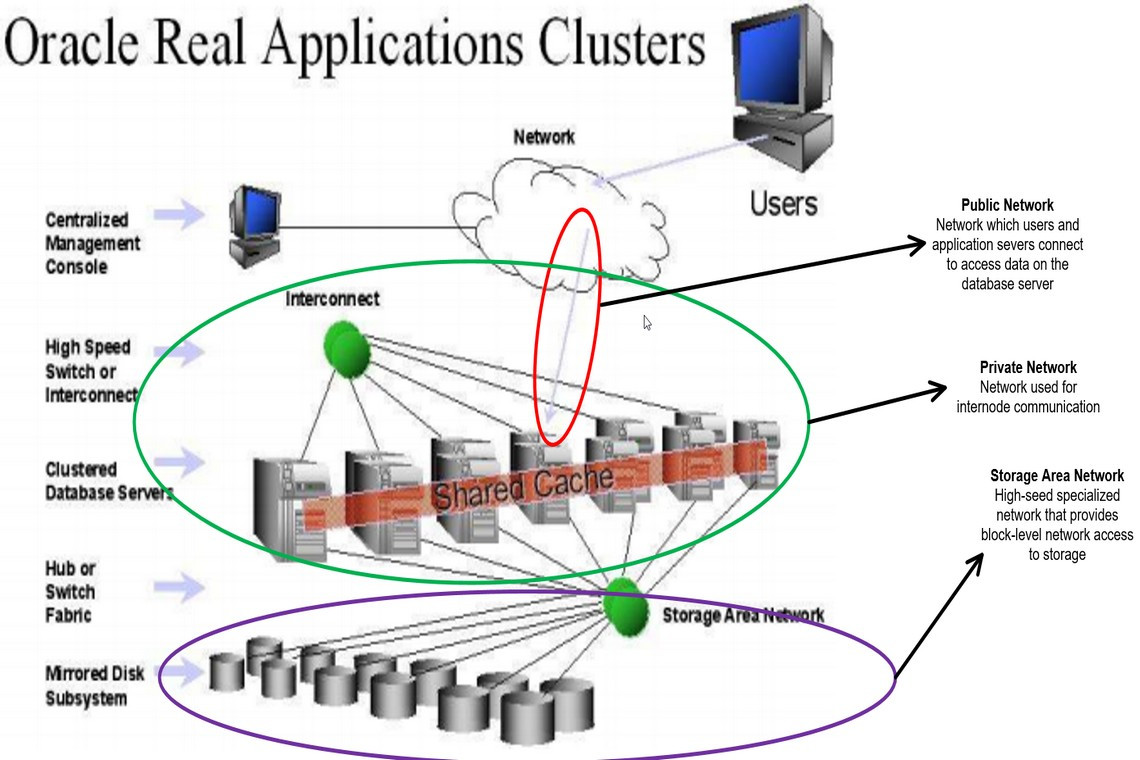

Oracle RAC environments involve concepts such as a virtual IP and SCAN (Single Client Access Name). In addition, you need to understand networking components such as network cards, network IP addresses, network bonding, and cluster interconnects. The following sections describe the key Oracle RAC–related networking concepts and components.
Key Networking Concepts
The most important Oracle RAC networking concepts you need to understand are
- Oracle virtual IPs
- Application virtual IP
- SCAN
The following sections explain each of these concepts.
Oracle Virtual IP
A virtual IP is required to ensure that applications can be designed to be highly available. A system needs to eliminate all single points of failure. In Oracle, clients connected to an Oracle RAC database must be able to survive a node failure. Client applications connect to the Oracle instance and access the database through the instance. Therefore, a node failure will bring down the instance to which the client might have connected.
The first design available from Oracle was Transparent Application Failover (TAF). With TAF, a session can fail over to the surviving instances and continue processing. Various limitations exist with TAF; for instance, only query failover is supported. Also, to achieve less latency in failing over to the surviving node, Oracle tweaked the TCP timeout (platform dependent; defaults to 10 minutes in most UNIX ports). It wouldn’t be a good idea to design a system in which a client takes 10 minutes to detect that there is no response from the node to which it has connected.
To address this, Oracle uses a feature called the cluster VIP—a cluster virtual IP address that would be used by the outside world to connect to the database. This IP address needs to be different from the set of IP addresses within the cluster. Traditionally, listeners would be listening on the public IP of the box and clients would contact the listeners on this IP. If the node dies, the client would take the TCP timeout value to detect the death of the node. Each node of the cluster has a VIP configured in the same subnet of the public IP. A VIP name and address must be registered in the DNS in addition to the standard static IP information. Listeners would be configured to listen on VIPs instead of the public IP.
When a node is down, the VIP is automatically failed over to one of the other nodes. During the failover, the node that gets the VIP will “re-ARP” to the world, indicating the new MAC address of the VIP. Clients who have connected to this VIP will immediately get a reset packet sent. This results in clients getting errors immediately rather than waiting for the TCP timeout value. When one node goes down in a cluster and a client is connecting to the same node, the client connection will be refused by the down node, and the client application will choose the next available node from the descriptor list to get a connection. Applications need to be written so that they catch the reset errors and handle them. Typically for queries, applications should see an ORA-3113 error.
NOTE
In computer networking, the Address Resolution Protocol (ARP) is the method of finding the host’s hardware addresses (MAC address) when only the IP address is known. The hosts use ARP when they want to communicate with each other in the same network. ARP is also used by routers to forward a packet from one host through another router. In cluster VIP failovers, the new node that gets the VIP advertises the new ARP address to the world. This is typically known as gratuitous ARP, and during this operation, the old hardware address is invalidated in the ARP cache, and all the new connections will get the new hardware address.
Application VIP
Oracle uses a virtual IP to allow Oracle database clients to rapidly recognize that a node has died, thus improving the reconnect time. Oracle also extends this capability to user applications. An application VIP is a cluster resource for managing the network IP address. An application VIP is mostly used by an application that is accessed over the network. When an application is built dependent on an application VIP (AVIP), whenever a node goes down, the application VIP fails over to the surviving node and restarts the application process on the surviving node.
The steps for creating an application VIP are the same as creating any other cluster resource. Oracle supplies the standard action program script usrvip, which is located under the <GRID_HOME>/bin directory. Users must use this action script to create an application VIP in an Oracle cluster. DBAs always wonder about the difference between a normal VIP and an application VIP. Upon failover to a surviving node, a normal VIP does not accept connections and forces clients to reconnect using another address, whereas an application VIP remains fully functional after it is relocated to another cluster node and it continuously accepts connections.
Single Client Access Name
SCAN is a single network name that resolves to three different IP addresses registered either in DNS or GNS. During installation of Oracle Grid Infrastructure, Oracle creates three SCAN listeners and SCAN VIPs. If Grid Name Server (GNS) is not used, then SCAN must be registered in DNS before installation of the Oracle Grid Infrastructure. Oracle fails over the SCAN VIP and the listener to another node in case of failure. Each database instance registers itself to the local listener and the SCAN listener using the database initialization parameter REMOTE_LISTENER, because this is the only way the SCAN listener knows about the location of the database instances. The SRVCTL utility can be used to manage and monitor the SCAN resources in the cluster.
SCAN allows users to connect to the database in the cluster using the EZconnect or jdbc thin driver, as shown here:
sqlplus system/password@my-scan:1521/oemdb jdbc:oracle:thin:@my-scan:1521/oemdbSCAN eases client connection management because there is no need to change the client connection strings even if the client’s target database is moved to a different node in the cluster. With more and more customers deploying Oracle RAC and building shared database services, there’s always a demand to simplify the client connection management and failover capabilities between moved database instances. For example, prior to Oracle 11g Release 2, there was no way other than modifying the service to notify the client connection that the database instance it is intending to connect to using the Oracle RAC service has been moved to another cluster node. SCAN allows failover to the moved database instances without modifying the Oracle RAC service. The following steps explain how a client connects to the database in a cluster using SCAN:
- The TNS layer retrieves the IP address of the SCAN from the Domain Name Server or Grid Name Server; it then load-balances and fails over across the IP address.
- The SCAN listener is now aware of databases in the cluster and will redirect the connection to the target database node VIP.
Oracle provides self-management of the network requirements of the cluster by supporting Dynamic Host Configuration Protocol (DHCP) for private interconnect and virtual IP addresses. Oracle needs an optimized way to resolve the IP address to a name; hence, it developed its own Grid Name Service, which is linked to the Domain Name Service and allows users to connect to the cluster and the databases in the cluster. Oracle uses a dedicated subdomain and a virtual IP GNS (aka GNS VIP) that is registered in the DNS. Each cluster will have its own GNS, GNS virtual IP, and a dedicated subdomain, and the subdomain will forward all requests for addresses in the subdomain to the GNS virtual IP. Oracle fails over the GNS and GNS virtual IP to another node in case of node failure.
When using GNS and DHCP, Oracle obtains the virtual IP address from the DHCP server and configures the SCAN name during cluster configuration. Oracle dynamically obtains new IP addresses from the DHCP server and configures the cluster resource whenever a node joins the cluster. Oracle does not use DHCP for the GNS VIP for obvious reasons—it must be known to the cluster prior to the Oracle Grid Infrastructure being installed.
The Networking Stack Components
The Oracle Grid Infrastructure requires fast communication over the public and private networks between the cluster nodes; hence, all the network components enabling this communication between the cluster nodes are very important, and it is not possible to build the Oracle Real Application Cluster database without these network components.
Network Interface Cards
Oracle requires each cluster node to have at least two network interface cards—one for the public network and one for the private network. Four are preferred when bonded and for HA. Otherwise, single interfaces are a point of failure unless one creates a VLAN on the two interfaces bonded and exposes it as a separate interface name associated with each network. The interface cards must be the same on all cluster nodes in an Oracle cluster. The network interface card for the public network must support TCP/IP and must have a valid IP address and an associated hostname registered in the domain name server.
You can complete the Oracle Grid Infrastructure installation by just registering the hostname in the /etc/hosts file; however, it is strongly recommended for an associated hostname to be registered in the domain name server. The network interface card for the private network must support UDP (User Datagram Protocol). Performance of the Oracle Real Application Cluster depends on the speed of the private network; hence, a high-speed network interface card such as 10 Gigabit Ethernet Network Card is recommended.
Network IP Addresses
The public network interface on each cluster node must have a valid public IP address to identify the cluster node on the public network, and the public IP address must be associated with a hostname registered in the Domain Name Service (DNS). Sometimes more public IP addresses are required, depending on the redundancy technology used to team or bond network interface cards. For example, IPMP (IP network multipathing) on the Solaris operating system would require three public IP addresses.
Each cluster node must have assigned an unused virtual IP address associated with a virtual hostname registered in DNS. Oracle will configure this virtual IP address during installation of the Oracle Grid Infrastructure. This virtual IP address must have the same subnet as the public IP address configured for the public network interface card.
Each cluster node must have a private IP address for the private interface card. It is recommended that the private IP address be from a nonroutable private network. This is because we want to avoid reaching outside for “any” routing that may result in some inadvertent routing. Oracle does not require a private hostname and IP address to be registered in DNS because this private IP address must be known to cluster nodes only, so a private hostname can be registered in the /etc/hosts file of each cluster node. An Oracle cluster requires three IP addresses for SCAN that have the same subnet as the public IP address.
Cluster Interconnects
The cluster interconnect is another important component in Oracle RAC. It is a communication path used by the cluster for the synchronization of resources and is also used in some cases for the transfer of data from one instance to another. Typically, the interconnect is a network connection that is dedicated to the server nodes of a cluster (and thus is sometimes referred to as a private interconnect) and has a high bandwidth and low latency. Different hardware platforms and different clustering software have different protocol implementations for the high-speed interconnect.
Oracle RAC is all about scalability and high availability, so every effort must be made to configure redundant hardware components to avoid any single point of failure. Therefore, it is highly recommended that you configure redundant network interface cards for private and public networks. Different technologies are available to bond network interface cards together, such as teaming on Linux and IPMP on the Solaris operating system. Active/Passive teaming of the network interface cards works fine, but users can configure the redundant network interface cards in Active/Active configuration, where each network interface card transmits and receives network packets.
Table 1 lists the various interconnects used by the implementations based on the clusterware used and the network hardware. Using vendor-specific interconnects is often discouraged by Oracle because they make troubleshooting more complex compared with the standard open-system protocols.

TABLE 1. Interconnects Based on Clusterware and Hardware
In addition to the interconnects described in this table, newer interconnects such as Reliable Datagram Sockets (RDG) over InfiniBand can provide a horizontally scalable, high-speed, low-latency alternative to traditional vertical scaling.
Network Bonding
At the network level, a failure in a NIC can cause an outage in the cluster, especially if the failure occurs at the interface on which the interconnect is configured. To achieve high availability at this layer, network bonding is recommended. Bonding allows a node to see multiple physical NICs as a single logical unit.
The Linux kernel includes a bonding module that can be used to achieve software-level NIC teaming. The kernel-bonding module can be used to team multiple physical interfaces to a single logical interface, which is used to achieve fault tolerance and load balancing. The bonding driver is available as part of Linux kernel version 2.4 or later. Because the bonding module is delivered as part of the Linux kernel, it can be configured independently from the interface driver vendor (different interfaces can constitute a single logical interface).
Various hardware vendors provide different types of NIC bonding solutions for the network interconnect resiliency. Typically, bonding offers the following benefits:
- Bandwidth scalability Adding a network card doubles the network bandwidth. It can be used to improve aggregate throughput.
- High availability Provides redundancy or link aggregation of computer ports. Failure of a NIC does not induce a cluster outage because the traffic is routed through the other network.
- Load balancing Port aggregation supports true load-balancing and failure recovery capabilities as well as distributes traffic evenly across the aggregated links.
- Single MAC address Because port-aggregated networks share a single, logical MAC address, there is no need to assign individual addresses to aggregated ports.
- Flexibility Ports can be aggregated to achieve higher performance whenever network congestion occurs.
Interconnect Switch
A private network between cluster nodes must be configured using a high-bandwidth network switch (gigabit or higher) that supports TCP/IP. The Oracle requirement is to have a high-bandwidth, nonroutable, private network between the cluster nodes. Generally, big organizations share the network switches and are mostly reluctant to have a dedicated network switch for the Oracle Real Application Cluster databases. Users can use the shared network switches for the private interconnect and can follow the given guidelines to choose the right private interconnect:
- Oracle prefers using a dedicated high-bandwidth network switch.
- If you’re using the shared network switch, then use a dedicated, untagged, private, nonroutable VLAN. VLANs should not span the switch blades. Using a VLAN may have lots of advantages, but it is not superior to a dedicated switch. An overloaded backplane or processor on the physical switch will adversely impact the performance of the Cache Fusion traffic over the private network; this is why Oracle prefers using the dedicated physical switch for private interconnects.
- Always configure the network interface card on the fastest PCI bus available on the cluster nodes.
- Make sure that network interface cards are switched to “autonegotiate” and are configured for the maximum supported bandwidth.
- Jumbo frames can be configured for private network interface cards provided the private interconnect switch supports the jumbo frames.
- Consider configuring redundant network switches for the interconnect because failure in a network switch can bring the whole Oracle RAC database down.
The basic requirement of an interconnect is to provide reliable communication between nodes, but this cannot be achieved by a crossover cable between the nodes. However, using a crossover cable as the interconnect may be appropriate for development or demonstration purposes. Substituting a normal crossover cable is not officially supported in production Oracle RAC implementations for the following reasons:
- Crossover cables do not provide complete electrical insulation between nodes. Failure of one node because of a short circuit or because of electrical interference will bring down the surviving node.
- Using crossover cables instead of a high-speed switch greatly limits the scalability of the clusters because only two nodes can be clustered using a crossover cable.
- Failure of one node brings down the entire cluster because the cluster manager cannot exactly detect the failed/surviving node. Had there been a switch during split-brain resolution, the surviving node could easily deduct the heartbeat and take ownership of the quorum device, and node failures could be easily detected.
- Crossover cables do not detect split-brain situations as effectively as a communication interface through switches. Split-brain resolution is the effective part in cluster management during communication failures.
- Node Time Synchronization
Time on each cluster node must be synchronized because different time stamps on the cluster nodes can lead to false node eviction in the cluster. All operating systems provide a Network Time Protocol feature that must be configured and used before the Oracle Grid Infrastructure is installed.
Split-Brain Resolution
In the Oracle RAC environment, server nodes communicate with each other using high-speed private interconnects. A high-speed interconnect is a redundant network that is exclusively used for inter-instance communication and some data block traffic. A split-brain situation occurs when all the links of the private interconnect fail to respond to each other, but the instances are still up and running. Therefore, each instance thinks that the other instances are dead, and that it should take over the ownership.
In a split-brain situation, instances independently access the data and modify the same blocks, and the database will end up with changed data blocks overwritten, which could lead to data corruption. To avoid this, various algorithms have been implemented.
In the Oracle RAC environment, the Instance Membership Recovery (IMR) service is one of the efficient algorithms used to detect and resolve the split-brain syndrome. When one instance fails to communicate with the other instance, or when one instance becomes inactive for some reason and is unable to issue the control file heartbeat, the split-brain situation is detected and the detecting instance will evict the failed instance from the database. This process is called node eviction. Detailed information is written in alert log and trace files.
Oracle RAC - Networking : Public & Private video Tutorial