
Handling Online Redo Log Failures
I worked for a company that had just implemented an expensive database server with redundancy built into every component, or so I thought. The server was configured with RAID disks for all database files and the online redo log groups. The team was confident that there was minimal risk of failure with these disks.
Therefore, I decided not to multiplex the online redo log groups. A few days later, an inexpensive battery that maintained the cache for a disk controller failed. This caused corruption in the current online redo log group. As a result, the company lost data, experienced costly downtime, and had to perform an incomplete recovery.
As detailed in THIS Post, online redo logs are crucial database files that store a record of transactions that have occurred in your database. Since RMAN doesn’t back up online redo log files, you can’t use RMAN to restore these critical files. Given their criticality, I thought it was important to include a post on how to deal with failures with online redo log files.
Media failures with the online redo logs are usually noticed either when the database ceases to work (all members of a group have experienced media failure) or you notice an error in the alert.log indicating issues, for example:
ORA-00312: online log 3 thread 1: '/u01/oraredo/O12C/redo02b.rdo'Once you’ve discovered an issue, the first step is to determine how to recover from this failure.
![]() Tip Use the RMAN backup database plus archivelog command to ensure your current online redo log files (of all the threads) are switched and archived before and after the backup of the database.
Tip Use the RMAN backup database plus archivelog command to ensure your current online redo log files (of all the threads) are switched and archived before and after the backup of the database.
Determining a Course of Action
If you’ve experienced a problem with your online redo log files and need to determine what shape they are in and what action to take. Follow these steps when dealing with online redo log file failures:
- Inspect the alert.log file to determine which online redo log files have experienced a media failure.
- Query V$LOG and V$LOGFILE to determine the status of the log group and degree of multiplexing.
- If there is still one functioning member of a multiplexed group, then see the section of this blog on “Restoring After Losing One Member of Multiplexed Group” for details on how to fix a failed member(s).
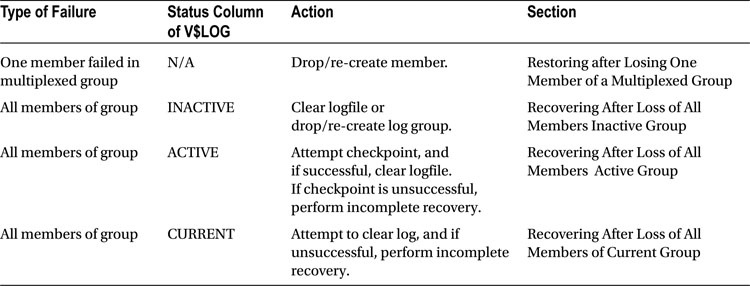
- Depending on the status of the log group, use Table 7-1 to determine what action to take.
Table 7-1. Determining the Action to Take
Inspect your target database alert.log file to determine which online redo log file member is unavailable. Oracle error messages related to online redo log file failures are ORA-00312 and ORA-00313. Here’s an example of errors written to the alert.log file when there are problems with an online redo log file:
ORA-00313: open failed for members of log group 2 of thread 1
ORA-00312: online log 2 thread 1: '/u02/oraredo/O12C/redo02b.rdo'
Query V$LOG and V$LOGFILE views to determine the status of your log group and the member files in each group:
SELECT
a.group#
,a.thread#
,a.status grp_status
,b.member member
,b.status mem_status
,a.bytes/1024/1024 mbytes
FROM v$log a,
v$logfile b
WHERE a.group# = b.group#
ORDER BY a.group#, b.member;
Here is some sample output:
GROUP# THREAD# GRP_STATUS MEMBER MEM_STA MBYTES
------ -------- ---------- ------------------------------ ------- --------
1 1 INACTIVE /u01/oraredo/O12C/redo01a.rdo 50
1 1 INACTIVE /u02/oraredo/O12C/redo01b.rdo 50
2 1 CURRENT /u01/oraredo/O12C/redo02a.rdo 50
2 1 CURRENT /u02/oraredo/O12C/redo02b.rdo 50
3 1 INACTIVE /u01/oraredo/O12C/redo03a.rdo 50
3 1 INACTIVE /u02/oraredo/O12C/redo03b.rdo 50
If only one member of a multiplexed group has experienced a failure, then proceed to the section on “Restoring After Losing One Member of Multiplexed Group”. If all members of a redo log group have experienced a failure and your database is open, it will hang (cease to allow transactions to process) as soon as the archiver background process cannot successfully copy the failed online redo log file members. If your database is closed, Oracle will not allow you to open it if all members of one online redo log group are experiencing a media failure. When you attempt to open your database, you’ll see a message similar to this:
ORA-00313: open failed for members of log group...Depending on the status reported in V$LOG for the failed group, use Table 7-1 to determine what action to take.
Your target database’s alert.log file contains the best information for determining what type of failure has occurred. If only one member of a multiplexed group fails, then you will be able to detect this only by inspecting the alert.log file. You can also try to stop and start your database. If all members of a group have experienced media failure, then Oracle will not let you open the database and will display an ORA-00313 error message.
The alert.log file will also tell you where additional error messages have been written to trace files:
Additional information: 3
Checker run found 1 new persistent data failures
Errors in file /u01/app/oracle/diag/rdbms/o12C/O12C/trace/O12C_lgwr_10531.trc:
When diagnosing online redo log issues, the V$LOG, V$LOGFILE, and V$LOG_HISTORY views are particularly helpful. You can query these views while the database is mounted or open. Table 7-2 briefly describes each view.
Table 7-2. Useful Views Related to Online Redo Logs
View | Description |
|---|---|
V$LOG | Displays the online redo log group information stored in the control file. |
V$LOGFILE | Displays online redo log file member information. |
V$LOG_HISTORY | History of online redo log information in control file. |
The STATUS column of the V$LOG view is particularly useful when working with online redo logs groups. Table 7-3 describes each status and meaning for the V$LOG view.
Table 7-3. Status for Online Redo Log Groups in the V$LOG View
Status | Meaning |
|---|---|
CURRENT | The log group that is currently being written to by the log writer. |
ACTIVE | The log group is required for crash recovery and may or may not have been archived. |
CLEARING | The log group is being cleared out by an alter database clear logfile command. |
CLEARING_CURRENT | The current log group is being cleared of a closed thread. |
INACTIVE | The log group isn’t needed for crash recovery and may or may not have been archived. |
UNUSED | The log group has never been written to; it was recently created. |
The STATUS column of the V$LOGFILE view also contains useful information. This view contains information about each physical online redo log file member of a log group. Table 7-4 provides descriptions of the status of each log file member.
Table 7-4. Status for Online Redo Log File Members in the V$LOGFILE View
Status | Meaning |
|---|---|
INVALID | The log file member is inaccessible, or it has been recently created. |
DELETED | The log file member is no longer in use. |
STALE | The log file member’s contents are not complete. |
NULL | The log file member is being used by the database. |
It’s important to differentiate between the STATUS column in V$LOG and the STATUS column in V$LOGFILE. The STATUS column in V$LOG reflects the status of the log group. The STATUS column in V$LOGFILE reports the status of the physical online redo log file member.
Restoring After Losing One Member of Multiplexed Group
Suppose you notice this message in your alert.log file:
ORA-00312: online log 2 thread 1: '/u02/oraredo/O12C/redo02b.rdo'You know that this group is multiplexed but only see an error with one of the members of the group. If your online redo log file members are multiplexed, the log writer will continue to function as long as it can successfully write to one member of the current log group. If the problem is temporary, then as soon as the online redo log file becomes available, the log writer will start to write to the online redo log file as if there were never an issue.
If the media failure is permanent (such as a bad disk), then you’ll need to replace the disk and drop and re-create the bad member to its original location. If you don’t have the option of replacing the bad disk, then you’ll need to drop the bad member and re-create it in an alternate location.
For permanent media failures, follow these instructions for dropping and re-creating one member of an online redo log group:
- Identify the online redo log file experiencing media failure (inspect the alert.log).
- Ensure that the online redo log file is not part of the current online log group.
- Drop the damaged member.
- Add a new member to the group.
To begin, open your alert.log file and look for an ORA-00312 message that identifies which member of the log group is experiencing media failure. You should see lines similar to these in your alert.log file:
ORA-00312: online log 2 thread 1: '/u02/oraredo/O12C/redo02b.rdo'
Errors in file
/u01/app/oracle/diag/rdbms/o12C/O12C/trace/O12C_lgwr_10531.trc:
This message tells you which log member has failed. The alert.log file output also specifies that a trace file has been generated. You’ll find additional information about the bad member in the specified trace file:
ORA-00313: open failed for members of log group 2 of thread 1
ORA-00312: online log 2 thread 1: '/u02/oraredo/O12C/redo02b.rdo'
ORA-27037: unable to obtain file status
Linux-x86_64 Error: 2: No such file or directory
ORA-00321: log 2 of thread 1, cannot update log file header
ORA-00312: online log 2 thread 1: '/u02/oraredo/O12C/redo02b.rdo'
From the prior output, a member of the online redo log group 2 is having issues. Once you’ve identified the bad online redo log file, execute the following query to check whether that online redo log file’s group has a CURRENT status (in this example, we’re interested in group 2):
SELECT group#, status, archived, thread#, sequence#
FROM v$log;
Here is some sample output indicating that group 2 is not the current log:
GROUP# STATUS ARC THREAD# SEQUENCE#
---------- ---------------- --- ---------- ----------
1 CURRENT NO 1 25
3 INACTIVE NO 1 24
2 INACTIVE NO 1 23
![]() Note If you attempt to drop a member of a current log group, Oracle will throw an ORA-01609 error specifying that the log is current and you cannot drop one of its members.
Note If you attempt to drop a member of a current log group, Oracle will throw an ORA-01609 error specifying that the log is current and you cannot drop one of its members.
If the failed member is in the current log group, then use the alter system switch logfile command to make the next group the current group. Then drop the failed member as follows:
SQL> alter database drop logfile member '/u02/oraredo/O12C/redo02b.rdo';Then re-create the online redo log file member:
SQL> alter database add logfile member '/u02/oraredo/O12C/redo02b.rdo'
to group 2;
Keep in mind that the prior commands are examples, and that you’ll have to specify the directory and logfile member file and group number for your environment.
If an unused log file already happens to exist in the target location, you can use the reuse parameter to overwrite and reuse that log file. The log file must be the same size as the other log files in the group:
SQL> alter database add logfile member '</directory/file_name>' reuse
to group <group#>;
As mentioned previously, Oracle will continue to operate as long as it can write to at least one member of a multiplexed redo log group. An error message will be written to the alert.log file when the log writer is unable to write to a current online redo log file.
You should periodically inspect your alert.log file for Oracle errors. This may be the only way that you’ll discover a member of a group has experienced a media failure. I recommend that you run a periodic batch job that searches the alert.log file for any errors and automatically notifies you when it finds potential problems.
Once you’ve identified the bad member of an online redo log group, then you can drop and re-create the online redo log file. The newly created online redo log file may display an INVALID status in V$LOGFILE until it becomes part of the CURRENT log group. Once the newly created member becomes part of the CURRENT log group, its status should change to NULL. A NULL member status (as described in Table 7-4) indicates that the database is using the online redo log file.
You can drop and add online redo log file members while your database is in either a mounted state or an open state. I recommend that while dropping and re-creating log members, you have your database in a mounted state. This will ensure that the status of the log group doesn’t change while dropping and re-creating members. You cannot drop an online redo log file member that is part of the CURRENT group.
![]() Note When using the alter database drop logfile member command, you will not be allowed to drop the last remaining online redo log file member from a redo log group. If you attempt to do this, Oracle will throw an ORA-00361 error stating that you cannot remove the last standing log member. If you need to drop all members of a log group, use the alter database drop logfile group command.
Note When using the alter database drop logfile member command, you will not be allowed to drop the last remaining online redo log file member from a redo log group. If you attempt to do this, Oracle will throw an ORA-00361 error stating that you cannot remove the last standing log member. If you need to drop all members of a log group, use the alter database drop logfile group command.
SEARCHING THE ALERT LOG FOR ERRORS
Here’s a simple Bash shell script that determines the location of the alert.log and then searches the alert.log for an error string. You can use something similar to automatically detect errors in the alert.log.
#!/bin/bash
export DBS="ENGDEV STAGE OTEST"
export MAILLIST="This email address is being protected from spambots. You need JavaScript enabled to view it."
export BOX=`uname -a | awk '{print$2}'`
#-----------------------------------------------------------
for instance in $DBS
do
# call script to source oracle OS variables
export ORACLE_SID=O12C
export ORACLE_HOME=/orahome/app/oracle/product/12.1.0.1/db_1
export PATH=$PATH:$ORACLE_HOME/bin
crit_var=$(
sqlplus -s <<EOF
/ as sysdba
SET HEAD OFF TERM OFF FEED OFF VERIFY OFF
COL value FORM A80
select value from v\$diag_info where name='Diag Trace';
EOF)
if [ -r $crit_var/alert_$instance.log ]
then
grep -ic error $crit_var/alert_$instance.log
if [ $? = 0 ]
then
mailx -s "Error in $instance log file" $MAILLIST <<EOF
Error in $crit_var/alert_$instance.log file on $BOX...
EOF
fi # $?
fi # -r
done # for instance
exit 0
You can easily modify the above to fit the requirements of your environment. For example, you might need to change the way the Oracle operating system variables are sourced, the databases searched for, the error string, and the e-mail address. This is just a simple example showing the power of using a shell script to automate the search for errors in a file.
Recovering After Loss of All Members of Inactive Redo Log Group
If you’ve lost all members of an inactive redo log group, then perform the following steps:
- Verify that all members of a group have been damaged (by inspecting the alert.log file).
- Verify that the log group status is INACTIVE.
- Re-create the log group with the clear logfile command.
- If the re-created log group has not been archived, then immediately back up your database.
If all members of an online redo log group are damaged, you won’t be able to open your database. In this situation, Oracle will allow you to only mount your database.
First inspect your alert.log file, and verify that all members of a redo log group are damaged. You should see a message indicating that all members of an online redo log group are damaged and the database cannot open:
ORA-00312: online log 2 thread 1: '/u01/oraredo/O12C/redo02a.rdo'
ORA-00313: open failed for members of log group 2 of thread 1
Next, ensure that your database is in mount mode:
$ sqlplus / as sysdba
SQL> startup mount;
Next, run the following query to verify that the damaged log group is INACTIVE and determine whether it has been archived:
SELECT group#, status, archived, thread#, sequence#
FROM v$log;
Here is some sample output:
GROUP# STATUS ARC THREAD# SEQUENCE#
---------- ---------------- --- ---------- ----------
1 CURRENT NO 1 25
3 INACTIVE NO 1 24
2 INACTIVE NO 1 23
If the status is INACTIVE, then this log group is no longer needed for crash recovery (as described in Table 7-3). Therefore, you can use the clear logfile command to re-create all members of a log group. The following example re-creates all log members of group 2:
SQL> alter database clear logfile group 2;If the log group has not been archived, then you will need to use the clear unarchived logfile command as follows:
SQL> alter database clear unarchived logfile group 2;If the cleared log group had not been previously archived, it’s critical that you immediately create a backup of your database. See This article for details on taking a complete backup of your database.
Keep in mind that in these prior examples the logfile group is number 2. You’ll have to modify the group number to match the group number for your scenario.
If the online redo log group is inactive and archived, then its contents aren’t required for crash or media recovery. Therefore it’s possible to use the clear logfile command to re-create all online redo log file members of a group.
![]() Note The clear logfile command will drop and re-create all members of a log group for you. You can issue this command even if you have only two log groups in your database.
Note The clear logfile command will drop and re-create all members of a log group for you. You can issue this command even if you have only two log groups in your database.
If the online redo log group has not been archived, then it may be required for media recovery. In this case, use the clear unarchived logfile command to re-create the logfile group members. Back up your database as soon as possible in this situation.
The unarchived log group may be needed for media recovery if the last database backups were taken before the redo information in the log was created. This means if you attempt to perform media recovery, you won’t be able to recover any information in the damaged log file or any transactions that were created after that log.
If the clear logfile command does not succeed because of an I/O error and it’s a permanent problem, then you will need to consider dropping the log group and re-creating it in a different location. See the next two subsections for directions on how to drop and re-create a log file group.
Dropping a Log File Group
The alternative to clearing a logfile group (which tells Oracle to re-create the logfile) is to drop and re-create the logfile group. You might need to do this if you need to re-create the logfile group in a different location because the original location is damaged or not available.
A log group has to have an inactive status before you can drop it. You can check the status of the log group, as shown here:
SQL> select group#, status, archived, thread#, sequence# from v$log;You can drop a log group with the drop logfile group command:
SQL> alter database drop logfile group <group #>;If you attempt to drop the current online log group, Oracle will return an ORA-01623 error stating that you cannot drop the current group. Use the alert system switch logfile command to switch the logs and make the next group the current group.
After a log switch, the log group that was previously the current group will retain an active status as long as it contains redo that Oracle requires to perform crash recovery. If you attempt to drop a log group with an active status, Oracle will throw an ORA-01624 error stating that the log group is required for crash recovery. Issue an alter system checkpoint command to make the log group inactive.
Additionally, you cannot issue a drop logfile group command if it leaves you with only one log group left in your database. If you attempt to do this, Oracle will throw an ORA-01567 error and inform you that dropping the log group is not permitted because it would leave you with less than two logs groups for your database (Oracle minimally requires two log groups to function).
Adding a Log File Group
You can add a new log group with the add logfile group command:
SQL> alter database add logfile group <group_#>
('/directory/file') SIZE <bytes> K|M|G;
You can specify the size of the log file in bytes, kilobytes, megabytes, or gigabytes. The following example adds a log group with two members sized at 50MB:
SQL> alter database add logfile group 2
('/u01/oraredo/O12C/redo02a.rdo',
'/u02/oraredo/O12C/redo02b.rdo') SIZE 50M;
If for some reason the log file members already exist on disk, you can use the reuse clause to overwrite them:
alter database add logfile group 2
('/u01/oraredo/O12C/redo02a.rdo',
'/u02/oraredo/O12C/redo02b.rdo') SIZE 50M reuse;
![]() Tip See THIS Blog for an example of moving an online redo log group.
Tip See THIS Blog for an example of moving an online redo log group.
Recovering After Loss of All Members of Active Redo Log Group
If all the members of an active online redo log group in your database have experienced media failure, then perform the following steps when restoring an active online redo log group:
- Verify the damage to the members.
- Verify that the status is ACTIVE.
- Attempt to issue a checkpoint.
- If the checkpoint is successful, the status should now be INACTIVE, and you can clear the log group.
- If the log group that was cleared was unarchived, back up your database immediately.
- If the checkpoint is unsuccessful, then you will have to perform incomplete recovery.
Inspect your target database alert.log file, and verify the damage. You should see a message in the alert.log file identifying the bad members:
ORA-00312: online log 2 thread 1: '/u01/oraredo/O12C/redo02a.rdo'
ORA-00312: online log 2 thread 1: '/u02/oraredo/O12C/redo02b.rdo'
Next, verify that the damaged log group has an ACTIVE status as follows:
$ sqlplus / as sysdba
SQL> startup mount;
Run the following query:
SQL> select group#, status, archived, thread#, sequence# from v$log;Here is some sample output:
GROUP# STATUS ARC THREAD# SEQUENCE#
------ ---------------- --- -------- ----------
1 CURRENT NO 1 92
2 ACTIVE YES 1 91
3 INACTIVE YES 1 90
If the status is ACTIVE, then attempt to issue an alter system checkpoint command, as shown here:
SQL> alter system checkpoint;
System altered.
If the checkpoint completes successfully, then the active log group should be marked as INACTIVE. A successful checkpoint ensures that all modified database buffers have been written to disk, and at that point, only transactions contained in the CURRENT online redo log will be required for crash recovery.
![]() Note If the checkpoint is unsuccessful, you will have to perform incomplete recovery. See the section in this article “Recovering After Loss of All Members of Current Redo Log Group” for a full list of options in this scenario.
Note If the checkpoint is unsuccessful, you will have to perform incomplete recovery. See the section in this article “Recovering After Loss of All Members of Current Redo Log Group” for a full list of options in this scenario.
If the status is INACTIVE and the log has been archived, you can use the clear logfile command to re-create the log group, as shown here:
SQL> alter database clear logfile group <group#>;If the status is inactive and the log group has not been archived, then re-create it with the clear unarchived logfile command, as shown here:
SQL> alter database clear unarchived logfile group <group#>;If the cleared log group had not been previously archived, it’s critical that you immediately create a backup of your database. See THIS Post for details on creating a complete backup of your database.
An online redo log group with an ACTIVE status is still required for crash recovery. If all members of an active online redo log group experience media failure, then you must attempt to issue a checkpoint. If the checkpoint is successful, then you can clear the log group. If the checkpoint is unsuccessful, then you will have to perform an incomplete recovery.
If the checkpoint is successful and if the log group has not been archived, then the log may be required for media recovery. Back up your database as soon as possible in this situation. The unarchived log group may be needed for media recovery if the last database backups were taken before the redo information in the log was created. This means if you attempt to perform media recovery, you won’t be able to recover any information in the damaged log file or any transactions that were created after that log.
Recovering After Loss of All Members of Current Redo Log Group
If all of the members of a current Online redo logs:recovery online redo log group in your database have experienced media failure then (unfortunately) your alternatives are limited when you lose all members of a current online redo log group. Here are some possible options:
- Perform an incomplete recovery up to the last good SCN.
- If flashback is enabled, flash your database back to the last good SCN.
- If you’re using Oracle Data Guard, fail over to your physical or logical standby database.
- Contact Oracle Support for suggestions.
In preparation for an incomplete recovery, first determine the last good SCN by querying the FIRST_CHANGE# column from V$LOG. In this scenario, you’re missing only the current online redo logs. Therefore, you can perform an incomplete recovery up to, but not including, the FIRST_CHANGE# SCN of the current online redo log.
SQL> shutdown immediate;
SQL> startup mount;
Now issue this query:
SELECT group#, status, archived,
thread#, sequence#, first_change#
FROM v$log;
Here is some sample output:
GROUP# STATUS ARC THREAD# SEQUENCE# FIRST_CHANGE#
------ ---------------- --- -------- ---------- -------------
1 INACTIVE YES 1 86 533781
2 INACTIVE YES 1 85 533778
3 CURRENT NO 1 87 533784
In this case, you can restore Online redo logs:recovery and recover up to, but not including, SCN 533784. Here’s how you would do that:
RMAN> restore database until scn 533784;
RMAN> recover database until scn 533784;
RMAN> alter database open resetlogs;
![]() Note For complete details on incomplete recovery, and/or flashing back your database see This Article.
Note For complete details on incomplete recovery, and/or flashing back your database see This Article.
Losing all members of your current online redo log group is arguably the worst thing that can happen to your database. If you experience media failure with all members of the current online redo group, then you most likely will lose any transactions contained in those logs. In this situation, you will have to perform incomplete recovery before you can open your database.
![]() Tip If you are desperate to restore transactions lost in damaged current online redo log files, then contact Oracle Support to explore all options.
Tip If you are desperate to restore transactions lost in damaged current online redo log files, then contact Oracle Support to explore all options.
Summary
It’s critical that you understand how to handle online redo log failures. Oracle doesn’t provide an automated method for fixing problems when there’s a media failure with the online redo logs. Therefore it’s important that you know how to diagnose and troubleshoot any issues that arise. Failures with the online redo logs are rare, but when they do happen, you’ll now be much better prepared to resolve any complications in an efficient and effective manner.