 In a highly distributed database management system, it is important to realize that Consistency, Availability, and Partition Tolerance come at a price. The CAP Theorem states that it is impossible to provide all three capabilities simultaneously. Different NoSQL systems provide varying degrees of Consistency, Availability, and Partition Tolerance, and it is important to choose the right implementation based on your application needs.
In a highly distributed database management system, it is important to realize that Consistency, Availability, and Partition Tolerance come at a price. The CAP Theorem states that it is impossible to provide all three capabilities simultaneously. Different NoSQL systems provide varying degrees of Consistency, Availability, and Partition Tolerance, and it is important to choose the right implementation based on your application needs.
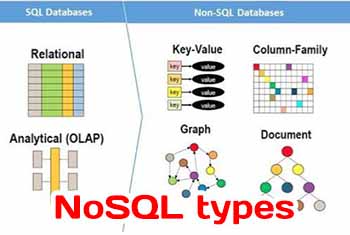
In addition to the distributed system properties that are mentioned in the preceding paragraph, you can also classify NoSQL database implementations based on the mechanisms they use to store and retrieve data. These are important for the application developer to consider before choosing the appropriate implementation. There are four broad implementation types: key-value store, document store, columnar, and graph.
Key-Value Stores
The key-value implementation stores data with unique keys, and the system is opaque to the contents of the data. It is the responsibility of the client to introspect the contents. This architecture allows for a highly optimized key-based lookup. Scalability is achieved through the sharding (a.k.a. partitioning) of data across nodes. To protect against data loss, key-value store implementations replicate data over nodes, and this can potentially lead to consistency issues when you have network failures and inaccessible nodes. Many systems therefore leave it up to the client to handle and resolve any consistency issues.
Key-value stores are very useful for applications such as user profile lookup, storing and retrieving online shopping carts, and catalog lookups. These applications have a unique user ID or an item ID associated with the data, and the key-value store provides a clean and efficient API to retrieve this information.
Document Stores
The document stores at their foundation are very similar to key-value implementation. An important distinction, however, is their capability to introspect the data that is associated with the key. This is possible because the document store understands the format of the data stored. This opens up the possibility to carry out aggregates and searches across elements of the document itself. Also, bulk update of the data is possible. Document stores work with multiple formats including XML and JSON. This allows for storage and retrieval of data without an impedance match.
The scalability, replication, and consistency characteristics of document stores are very similar to those of KV stores. Typical use cases for document stores include the storage and retrieval of catalogs, blog posts, news articles, and data analysis.
Graph Stores
Graph stores are different from the other methods in that they have the capability not only to capture information about objects, but can also record the relationships between these objects. Within each graph store, there are objects and relationships, which have specific properties attached to them. At the application level, these properties can be used to create specific subsets of relationships or objects best suited to a specific enterprise purpose. For example, the developer of a social network gaming application may wish to target a promotion of free in-game currency to those users who are friends of a gamer who ranks amongst the top 10 percentile of the highest scorers. Such data would be difficult to retrieve in other NoSQL database implementations, but the capability to traverse relationships in graph databases makes such queries very intuitive. For social networks, this analytical capability of graph stores allows for quick analysis and monetization of relationships that have been captured in their application. Graph databases can be used to analyze customer interactions, social media, and scientific application where it is crucial to traverse long relationship graphs to better understand data.
Column Stores
Column stores are the final type of NoSQL database that we will review. These store data in a columnar fashion; the result is a table where each row can have one or more columns, and the number of columns in each row can vary from row to row. This provides a very flexible data model to store your data, and a clear demarcation of similar attributes, which also acts as an index to quickly retrieve data. To further demarcate by columns, you can combine similar columns to build column families. This concept of grouping helps with more complex queries as well. At the core, each column and its associated data is essentially a key-value pair. As data is organized into columns, you have better indexing (and therefore visibility) compared to other key-value stores. Also, when it comes to updates, multiple column block updates can be aggregated. Column store databases were born when Google open sourced its implementation of a Column store NoSQL database called Big Table. Apparently, the data for the well-known Google e-mail service, Gmail, is stored in the Google Big Table NoSQL Database.
Based on the discussion of the four different types of NoSQL databases, it is evident that this family of products provides a rich set of functionality for storing and retrieving data in a very cost-effective, fault-tolerant, and scalable manner.