
 В этой статье моего блога мы поговорим о способах загрузки информации в базу данных Oracle, а именно рассмотрим утилиту импорта данных в СУБД Оракл под названием SQL*Loader.
В этой статье моего блога мы поговорим о способах загрузки информации в базу данных Oracle, а именно рассмотрим утилиту импорта данных в СУБД Оракл под названием SQL*Loader.
Загрузка и преобразование данных
Одной из наиболее типичных задач администратора баз данных Oracle (как и любой другой) является загрузка данных из внешних источников. Хотя обычно она выполняется при первоначальном заполнении базы данных, нередко загружать данные в различные таблицы требуется на протяжении всего существования производственной базы данных. Раньше администраторы баз данных применяли для выполнения загрузки данных из плоских файлов в таблицы базы данных Oracle только утилиту SQL*Loader.
Сегодня, хотя утилита SQL*Loader по-прежнему остается важным инструментом для загрузки данных в базы данных Oracle, компания Oracle также предлагает и другой способ для загрузки таблиц, а именно — рекомендует применять механизм внешних таблиц. Внешние таблицы используют функциональные возможности SQL*Loader и позволяют перед загрузкой данных в базу данных выполнять над ними сложные преобразования. С их помощью данные можно не только загружать в базу, но и выгружать во внешние файлы и затем из этих файлов загружать их в другие базы данных Oracle.
Во многих случаях, особенно в хранилищах данных, загружаемые данные требуется преобразовывать. Oracle предлагает несколько средств для выполнения преобразования данных внутри базы данных, в число которых входят технологии SQL и PL/SQL. Например, мощная конструкция MODEL позволяет создавать сложные многомерные массивы и производить сложные вычисления между строками и массивами с помощью простого SQL-кода.
А еще Oracle предлагает полезный механизм репликации данных под названием Oracle Streams (Потоки Oracle), который позволяет передавать изменения из одной базы данных в другую. Этот механизм можно использовать для различных целей, в том числе и для обслуживания резервной базы данных.
В настоящей главе рассматриваются все эти имеющие отношение к загрузке и преобразованию данных вопросы. Но сначала, конечно же, приводится краткий обзор того, чтобы собой вообще представляет процесс извлечения, преобразования и загрузки.
Краткий обзор процесса извлечения, преобразования и загрузки данных
Прежде чем запускать в отношении СУБД Oracle Database какое-либо приложение, ее сначала необходимо заполнить данными. Одним из наиболее типичных источников данных для заполнения базы является набор плоских файлов из унаследованных систем или других источников.
Раньше применение стандартного или прямого метода загрузки данных с использованием SQL*Plus было единственно возможным способом выполнения загрузки этих данных из внешних файлов в таблицы базы данных. С технической точки зрения, SQL*Loader по-прежнему остается главной поставляемой Oracle утилитой для выполнения загрузки данных из внешних файлов, но при желании можно также использовать и механизм внешних таблиц, который за счет применения инструмента SQL*Loader помогает получать доступ к данным, находящимся во внешних файлах данных.
Из-за того, что исходные данные могут содержать излишнюю информацию или данные в другом формате, отличном от того, который требуется приложению, зачастую бывает необходимо преобразовывать их каким-нибудь образом прежде, чем база данных сможет их использовать. Преобразование данных является особенно распространенным требованием для хранилищ данных, которые предусматривают извлечение данных из множества источников. Существует возможность производить предварительное или базовое преобразование исходных данных во время запуска самой утилиты SQL*Loader. Однако сложное преобразование данных требует отдельных этапов, и для управления этим процессом на выбор доступно нескольких приемов. В большинстве хранилищ данные проходят три основных этапа, прежде чем их становится можно анализировать: извлечение (extraction), преобразование (transformation) и загрузка (loading), все месте называемые процессом ETL. Ниже описано, что собой представляет каждый из этапов.
- Извлечение — это процесс выявления и извлечения исходных данных, возможно, пребывающих в различных форматах, из нескольких источников, не все из которых могут представлять собой реляционные базы данных.
- Преобразование данных является самым сложным и длительным из этих трех процессов и может подразумевать применение к данным сложных правил, а так-же выполнение операций наподобие агрегирования данных и применения к ним различных функций.
- Загрузка — это процесс размещения данных в таблицах базы данных. Он может также подразумевать выполнение обслуживания индексов и ограничений на уровне таблиц.
Раньше в организациях пользовались двумя разными методами для выполнения процесса ETL: методом выполнения преобразования, а затем загрузки, и методом выполнения загрузки, а затем преобразования. Первый метод подразумевает очистку или преобразование данных перед их загрузкой в таблицы Oracle. Для выполнения этого преобразования обычно применяются разрабатываемые индивидуальным образом процессы ETL. Что касается второго метода, то в большинстве случаев он не предусматривает полного использования предлагаемых Oracle встроенных возможностей для преобразования, вместо этого он подразумевает выполнение сначала загрузки данных в промежуточные таблицы и их перемещение в конечные таблицы только после их преобразования уже внутри самой базы данных. Промежуточные таблицы играют в этом методе ключевую роль. Его недостатком является то, что в таблицах приходится поддерживать несколько типов данных, одни из которых пребывают в исходном, а другие — уже в готовом состоянии.
Сегодня в Oracle Database 11g предлагаются просто потрясающие возможности ETL, которые позволяют производить загрузку данных в базу данных новым образом, а именно — методом выполнения их преобразования во время загрузки. За счет использования базы данных Oracle для выполнения всех этапов ETL все обычно трудоемкие процессы ETL можно выполнять довольно легко. Oracle предоставляет целый набор вспомогательных инструментов и технологий, которые сокращают время, требуемое на выполнение загрузки данных в базу данных, и при этом также упрощают всю связанную с этим работу. В частности, в состав предлагаемого Oracle решения ETL входят следующие компоненты.
- Внешние таблицы (external tables). Внешние таблицы предоставляют способ для объединения процессов загрузки и преобразования. Их применение позволит не прибегать к громоздким и отнимающим много времени промежуточным таблицам во время загрузки данных. О них более подробно будет рассказываться позже в этой главе, в разделе “Использование внешних таблиц для загрузки данных”.
- Многотабличные вставки (multitable inserts). Механизм многотабличных вставок позволяет вставлять данные не в одну, а сразу в несколько таблиц одновременно с использованием разных критериев для разных таблиц. Он устраняет необходимость в выполнении такого дополнительно шага, как разбиение данных на отдельные группы, перед осуществлением их загрузки. О нем более подробно речь пойдет позже в этой главе, в разделе “Применение многотабличных вставок”.
- Вставки-обновления (upserts). Это выдуманное название для обозначения технологии, позволяющей либо вставлять данные в таблицу, либо лишь обновлять в ней строки с помощью одного SQL-оператора MERGE. Оператор MERGE будет либо вставлять новые данные, либо обновлять строки, если такие данные уже существуют в таблице. Он может очень сильно облегчать процесс загрузки, поскольку избавляет от необходимости беспокоиться о том, не содержатся ли в таблице уже такие данные. Более подробно о нем будет рассказываться позже в этой главе, в разделе “Применение оператора MERGE”.
- Табличные функции (table functions). Табличные функции генерируют в качестве вывода набор строк. Они возвращают экземпляр типа коллекции (т.е. вложенной таблицы или одного из типов данных VARRAY). Они похожи на представления, но вместо определения процесса преобразования декларативным образом на языке SQL подразумевают его определение процедурным образом на языке PL/SQL. Табличные функции очень помогают при выполнении крупных и сложных преобразований, поскольку позволяют выполнять их перед загрузкой данных в хранилище данных. Более подробно о них речь пойдет позже в этой главе, в раздел “Применение табличных функций для преобразования данных”.
- Переносимые табличные пространства (transportable tablespaces). Эти табличные пространства обеспечивают эффективный и скоростной способ для перемещения данных из одной базы данных в другую. Например, с их помощью можно легко и быстро осуществлять миграцию данных между базой данных OLTP и хранилищем данных. О них более подробно мы поговорим в новых статьях блога.
На заметку! Еще для осуществления загрузки данных эффективным образом можно использовать инструмент Oracle Warehouse Builder (Программа для построения хранилищ данных Oracle) или просто OWB. Этот инструмент представляет собой управляемое мастером средство для загрузки данных в базу данных через SQL*Loader. Он позволяет загружать данные как из баз данных Oracle, так и из плоских файлов. Кроме того, он позволяет извлекать данные и из других баз данных, наподобие Sybase, Informix и Microsoft SQL Server, через механизм Oracle Transparent Gateways (Прозрачные шлюзы Oracle). Он сочетает в себе функции для ETL и проектирования в очень удобном для использования формате.
В следующем разделе вы узнаете о том, как можно использовать утилиту SQL*Loader для загрузки данных из внешних файлов. Это также поможет разобраться и в том, как применять внешние таблицы для выполнения загрузки данных. После описания механизма внешних таблиц будут рассмотрены различные предлагаемые в Oracle Database 11g методы для преобразования данных.
Использование утилиты SQL*Loader
Утилита SQL*Loader, которая поставляется с сервером баз данных Oracle, часто применяется администраторами баз данных для загрузки внешних данных в базы данных Oracle. Она является чрезвычайно мощным инструментом и способна выполнять не только загрузку данных из текстовых файлов. Ниже приведен краткий перечень других ее возможностей.
- Она позволяет производить преобразование данных перед или прямо во время самой их загрузки (правда, ограниченным образом).
- Она позволяет выполнять загрузку данных из нескольких видов источников: с дисков, с лент и из именованных каналов, а также использовать несколько файлов данных в одном и том же сеансе загрузки.
- Она позволяет выполнять загрузку данных по сети.
- Она позволяет осуществлять выборочную загрузку данных из входного файла на основании различных условий.
- Она позволяет производить загрузку как всей таблицы, так и только какой-то конкретной ее части, а также загружать данные одновременно в несколько таблиц.
- Она позволяет проводить одновременные операции по загрузке данных.
- Она позволяет автоматизировать процесс загрузки, так что бы он выполнялся в запланированное время.
- Она позволяет загружать сложные объектно-реляционные данные.
Утилита SQL*Loader может применяться для выполнения загрузки данных в нескольких режимах.
- В обычном режиме (conventional data loading). В этом режиме SQL*Loader считывает за раз по несколько строк и сохраняет их в массиве связывания (bind array), а впоследствии вставляет весь этот массив сразу в базу данных и фиксирует операцию.
- В прямом режиме (direct-path loading). В этом режиме никакой SQL-оператор INSERT для загрузки данных в таблицы Oracle не используется. Вместо этого из подлежащих загрузке данных создаются структуры массивов столбцов, которые затем применяются для форматирования блоков данных Oracle, после чего те напрямую записываются в таблицы базы данных.
- В режиме внешних таблиц (external data loading). Новый предлагаемый Oracle механизм внешних таблиц базируется на использовании функциональных возможностей SQL*Loader и позволяет получать доступ к находящимся во внешних файлах данным так, будто бы они являются частью таблиц базы данных. При применении драйвера доступа ORACLE_LOADER для создания внешней таблицы, по сути, используются функциональные возможности SQL*Loader. В Oracle Database 11g еще предлагается новый драйвер доступа ORACLE_DATAPUMP, который позволяет осуществлять запись во внешние таблицы.
Два первых режима (или метода) загрузки имеют как свои преимущества, так и свои недостатки. Из-за того, что прямой режим загрузки работает в обход предлагаемого Oracle механизма SQL, он является гораздо быстрее обычного режима загрузки. Однако в том, что касается возможностей для преобразования данных, обычный режим значительно превосходит прямой, поскольку позволяет применять к столбцам таблицы во время загрузки данных ряд различных функций. Поэтому в Oracle рекомендуют применять обычный метод загрузки для загрузки небольшого количества данных, а прямой — для загрузки данных большого объема. Прямой режим загрузки будет более детально рассматриваться сразу же после изучения основных функциональных возможностей SQL*Loader и способов применения обычного метода загрузки. Что касается режима внешних таблиц, то о нем более подробно речь пойдет позже в этой главе, в разделе “Использование внешних таблиц для загрузки данных”.
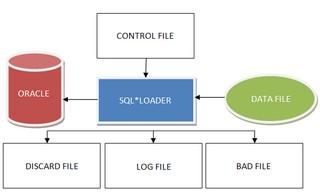
Процесс загрузки данных с помощью утилиты SQL*Loader включает в себя два основных шага.
- Выбор файла данных, в котором содержатся подлежащие загрузке данные. Такой файл обычно имеет расширение .dat и содержит необходимые данные. Эти данные могут быть в нескольких форматах.
- Создание управляющего файла (control file). Управляющий файл указывает SQL*Loader, как следует размещать поля данных в таблице Oracle и не нужно ли преобразовывать данные каким-нибудь образом. Такой файл обычно имеет расширение .ctl.
Управляющий файл будет предоставлять схему отображения столбцов таблицы на поля данных во входном файле. Наличие отдельного файла данных для выполнения загрузки вовсе не является обязательным требованием. При желании данные могут включаться и в сам управляющий файл, после указания информации, касающейся управления процессом загрузки, наподобие списка полей и т.д. Эти данные могут предоставляться как в виде полей фиксированной длины, так и в свободном формате с использованием специального символа-разделителя, вроде запятой (,) или конвейера (|). Раз управляющий файл является столь важным, давайте начнем именно с него.
Изучение управляющего файла SQL*Loader
Управляющий файл SQL*Loader представляет собой простой текстовый файл, в котором указываются важные детали связанного с загрузкой задания, наподобие места размещения исходного фала данных, а также схема отображения данных в этом исходном файле на столбцы в целевой таблице. Еще в нем могут указываться любые подлежащие выполнению во время процесса загрузки операции преобразования, а также имена файлов журналов, которые должны использоваться для загрузки, и имена файлов, которые должны использоваться для перехвата неправильных и отвергаемых данных. В общем, в управляющем файле утилите SQL*Loader предоставляются инструкции касательно следующих аспектов:
- источник данных, подлежащих загрузке в базу;
- спецификация столбцов в целевой таблице;
- особенности используемого во входном файле форматирования;
- отображение полей входного файла на столбцы целевой таблицы;
- правила преобразования данных (применение функций SQL);
- место размещения файлов журналов и файлов ошибок.
В листинге 13.1 приведен пример типичного управляющего файла SQL*Loader. Утилита SQL*Loader считает содержащиеся в исходных файлах строки данных записями (records), и потому в управляющем файле еще может указываться формат записей. Обратите внимание на то, что также допускается использовать и отдельный файл для данных. В данном примере, однако, подлежащие загрузке данные идут прямо следом за управляющей информацией, благодаря использованию в управляющем файле спецификации INFILE *. Эта спецификация указывает, что данные для загрузки будут идти после управляющей информации. При выполнении разовой операции по загрузке данных, пожалуй, лучше поступать как можно проще и размещать данные в самом управляющем файле. Ключевое слово BEGINDATA показывает SQL*Loader, где начинается содержащая данные часть управляющего файла.
LOAD DATA INFILE * BADFILE test.bad DISCARDFILE test.dsc INSERT INTO TABLE tablename FIELDS TERMINATED BY ',' OPTIONALLY ENCLOSED BY"" (column1 POSITION (1:2) CHAR, column2 POSITION (3:9) INTEGER EXTERNAL, column3 POSITION (10:15) INTEGER EXTERNAL, column4 POSITION (16:16) CHAR ) BEGINDATA AY3456789111111Y /* Остальные данные . . .*/
Та часть управляющего файла, в которой описываются поля данных, называется списком полей (field list). В управляющем файле, показанном в листинге 13.1, этот список полей выглядит так:
(column1 POSITION (1:2) char, column2 POSITION (3:9) integer external, column3 POSITION (10:15) integer external, column4 POSITION (16:16) char )
Здесь видно, что в списке полей перечисляются имена полей, их позиция, тип данных, разделители и любые допустимые условия.
В управляющем файле можно задавать множество переменных, которые, грубо говоря, делятся на следующие группы:
- конструкции, касающиеся загрузки;
- конструкции, касающиеся файлов данных;
- конструкции, касающиеся отображения таблиц и полей;
- задаваемые в управляющем файле параметры командной строки.
В следующих подразделах более подробно описываются все эти различные виды параметров, которые можно задавать в управляющем файле для настройки процессов загрузки данных.
Совет. При отсутствии уверенности в том, какие параметры использовать для сеанса SQL*Loader, можно просто ввести в командной строке операционной системы sqlldr для просмотра всех доступных вариантов. Выполнение этой команды будет приводить к отображению списка всех возможных параметров и значений по умолчанию, которые приняты для них в конкретной операционной системе (если таковые существуют).
Конструкции, касающиеся загрузки
Ключевые слова LOAD DATA находятся в самом начале управляющего файла и просто означают, что требуется выполнить загрузку данных из входного файла в таблицы Oracle с помощью SQL*Loader.
Конструкция INTO TABLE указывает, в какую таблицу требуется загрузить данные. При необходимости выполнить загрузку данных сразу в несколько таблиц, нужно использовать по одной конструкции INTO TABLE для каждой таблицы. Ключевые слова INSERT, REPLACE, и APPEND указывают базе данных, каким образом должна выполняться загрузка. В случае применения конструкции INSERT таблица должна обязательно быть пустой, иначе процесс загрузки будет приводить к генерации ошибки или останавливаться. Конструкция REPLACE указывает Oracle усекать таблицу и начинать загружать новые данные. При выполнении операции загрузки с использованием параметра REPLACE зачастую будет казаться, будто бы она сначала зависает. На самом же деле в это время Oracle занимается усечением таблицы перед началом процесса загрузки. Что касается конструкции APPEND, то она указывает Oracle добавлять новые строки к существующим данным таблицы.
Конструкции, касающиеся файлов данных
Существует несколько конструкций, которые можно использовать для указания места размещения и прочих характеристик файла или файлов данных, из которых планируется загружать данные через SQL*Loader. В следующих подразделах описываются некоторые наиболее важные из этих конструкций.
Спецификация файла данных
Имя и место размещения входного файла указывается с помощью параметра INFILE:
INFILE='/a01/app/oracle/oradata/load/consumer.dat'
При нежелании использовать спецификацию INFILE можно включать данные в сам управляющий файл. При включении данных в управляющий файл вместо применения отдельного входного файла, место размещения файла опускается и на его месте указывается просто символ *:
INFILE *
В случае выбора варианта с включением данных в сам управляющий файл, перед началом данных нужно обязательно использовать конструкцию BEGINDATA:
BEGINDATA Nicholas Alapati,243 New Highway,Irving,TX,75078 . . .
Физические и логические записи
Каждая физическая запись в исходном файле по умолчанию эквивалентна логической, но при желании в управляющем файле можно также указывать, что в состав одной логической записи должно входить и сразу несколько физических записей. Например, в следующем входном файле все три физических записи по умолчанию будут также считаться тремя логическими записями:
Nicholas Alapati,243 New Highway,Irving,TX,75078 Shannon Wilson,1234 Elm Street,Fort Worth,TX,98765 Nina Alapati,2629 Skinner Drive,Flower Mound,TX,75028
Для преобразования этих трех физических записей можно использовать в управляющем файле либо конструкцию CONCATENATE, либо конструкцию CONTINUEIF.
Если входные данные имеют фиксированный формат, указывать количество строк, которые должны считываться для образования каждой логической записи, можно следующим образом:
CONCATENATE 4
Конкретно эта конструкция CONCATENATE определяет, что одна логическая запись должна получаться путем объединения четырех строк данных. Если каждая строка данных состоит из 80 символов, тогда получается, что в создаваемой новой логической записи будет содержаться 320 символов. Из-за этого при использовании конструкции CONCATENATE следует также задавать вместе с ней и конструкцию длины записи (RECLEN). В данном случае эта конструкция должна выглядеть так:
RECLEN 320
Что касается конструкции CONTINUEIF, то она позволяет объединять физические записи в логические за счет указания одного или более символов в конкретном месте. Например:
CONTINUEIF THIS (1:4) = 'next'
В этом примере конструкция CONTINUEIF указывает, что в случае обнаружения в начале строки четырех символов next, утилита SQL*Loader должна воспринимать все последующие данные как продолжение предыдущей строки (четыре символа и слово next были выбраны произвольно: в роли указателей продолжения могут выступать любые символы).
В случае использования данных фиксированного формата символ CONTINUEIF может размещаться в самом последнем столбце, как показано в следующем примере:
CONTINUEIF LAST = '&'
Здесь конструкция CONTINUEIF определяет, что в случае обнаружения в конце строки символа амперсанда (&), утилита SQL*Loader должна воспринимать следующую строку как продолжение предыдущей.
На заметку! Применение как конструкции CONTINUEIF, так и конструкции CONCATENATE будет замедлять работу SQL*Loader, поэтому все-таки лучше отображать физические и логические записи по схеме “один к одному”. Так следует поступать потому, что при объединении нескольких физических записей для образования одной логической SQL*Loader требуется выполнять дополнительное сканирование входных данных, что отнимает больше времени.
Формат записей
Для записей можно применять один из трех следующих форматов.
- Потоковый формат (stream format). Этот формат является самым распространенным и подразумевает использование специального символа завершения для обозначения конца записи. При сканировании входного файла утилита SQL*Loader знает, что достигла конца записи, когда наталкивается на такой символ завершения. Если символ завершения не задан, по умолчанию таковым считается символ новой строки или символ перехода на новую строку (которому в Windows должен также обязательно предшествовать символ возврата каретки). В наборе из трех записей, который приводился в предыдущем примере, применялся именно такой формат.
- Переменный формат (variable format). Этот формат подразумевает явное указание в начале каждой записи ее длины, как показано в следующем примере:
INFILE 'example1.dat' "var 2"
06sammyy12johnson,1234
В этой строке содержится две записи: первая длиной в шесть символов (sammy) и вторая длиной в двенадцать символов (johnson,1234). Конструкция var 2 указывает SQL*Loader, что все записи данных имеют переменный размер, и что перед каждой новой записью идет показатель ее размера в виде поля длиной в 2 символа.
- Фиксированный формат (fixed format). Этот формат подразумевает задание конкретного фиксированного размера для всех записей. Ниже приведен пример, в котором указывается, что каждая запись занимает 12 байтов в длину:
INFILE 'example1.dat' "fix 12"
sammyy,1234, johnso,1234
В этом примере, на первый взгляд, кажется, что запись включает в себя всю строку (sammyy,1234, johnso,1234), но конструкция fix 12 указывает, что на самом деле в этой строке содержится целых две записи по 12 символов. Следовательно, получается, что в случае применения фиксированного формата в исходном файле данных допускается иметь и по несколько записей в каждой строке.
Конструкции, касающиеся сопоставления таблиц и полей
Во время сеанса загрузки SQL*Loader берет поля данных из записей данных и преобразует их в столбцы таблицы. Именно в этом процессе и помогают конструкции, касающиеся сопоставления таблиц и полей. С их помощью в управляющем файле предоставляются детали о полях, в том числе имена столбцов, позиция, типы содержащихся во входных записях данных, разделители и параметры преобразования.
Имя столбца в таблице
Каждый столбец в таблице задается четким образом с указанием позиции и типа данных, которые ассоциируются со значением соответствующего поля во входном файле. Загружать значениями все столбцы в таблице не обязательно. В случае пропуска каких-нибудь столбцов в управляющем файле, для них автоматически устанавливается значение NULL.
Позиция
Утилите SQL*Loader требуется как-то узнавать, где во входном файле находятся различные поля. Полями (fields) называются отдельные элементы в файле данных, и никакого прямого соответствия между этими полями и столбцами в таблице, в которую загружаются данные, не существует. Процесс отображения полей во входном файле данных на столбцы таблицы в базе данных называется установкой полей (field setting), и отнимает больше всего времени у ЦП во время загрузки. Точную позицию различных полей в записи данных позволяет задавать конструкция POSITION. Указываемая в этой конструкции позиция может быть относительной или абсолютной.
Под указанием относительной позиции подразумевается указание позиции поля относительно позиции предыдущего поля, как показано в следующем примере:
employee_id POSITION(*) NUMBER EXTERNAL 6 employee_name POSITION(*) CHAR 30
В этом примере конструкция POSITION инструктирует SQL*Loader сначала загружать первое поле employee_id, а затем переходить к загрузке поля employee_name, которое начинается в позиции 7 и занимает 30 символов в длину.
Под указанием абсолютной позиции подразумевается указание просто позиции, в которой начинается и заканчивается каждое поле:
employee_id POSITION(1:6) INTEGER EXTERNAL employee_name POSITION(7:36) CHAR
Типы данных
Типы данных, используемые в управляющем файле, касаются только входных записей, и с теми, которые ассоциируются со столбцами в таблицах базы данных, они не совпадают. Ниже перечислены четыре основных типа данных, которые могут применяться в управляющем файле SQL*Loader:
- INTEGER(n) — двоичное целое число, где n может быть 1, 2, 4 или 8
- SMALLINT
- CHAR
- INTEGER EXTERNAL
- FLOAT EXTERNAL
- DECIMAL EXTERNAL
Разделители
После указания типов данных можно задавать разделитель (delimiter), который должен использоваться для разделения полей. Определять его можно с помощью либо конструкции TERMINATED BY, либо конструкции ENCLOSED BY.
Конструкция TERMINATED BY ограничивает поле указанным символом и обозначает конец поля. Ниже приведены примеры:
TERMINATED BY WHITESPACE TERMINATED BY ","
В первом примере конструкция TERMINATED BY указывает, что концом поля должен служить первый встречаемый символ пробела, а во втором — что для разделения полей должен использоваться символ запятой.
Конструкция ENCLOSED BY " " указывает, что в роли символа разделения полей должна выступать пара двойных кавычек. Ниже приведен пример использования этой конструкции:
FIELDS TERMINATED BY ',' OPTIONALLY ENCLOSED BY '"'
Совет. В Oracle рекомендуют избегать использования разделителей и лучше указывать везде, где можно, позиции полей (посредством параметра POSITION). Указание позиций полей избавляет базу данных от необходимости сканировать файл данных и отыскивать там выбранные разделители, что, следовательно, сокращает затрачиваемое на его обработку время.
Параметры преобразования данных
При желании можно делать так, чтобы перед загрузкой данных полей в столбцы таблицы к ним применялись SQL-функции. Вообще для преобразования значений полей разрешается использовать только такие SQL-функции, которые возвращают одиночные значения. На поле внутри строки SQL требуется ссылаться с помощью синтаксиса имя_поля. Саму SQL-функцию или функции нужно указывать после указания ассоциируемого с полем типа данных и заключать в двойные кавычки, как показано в следующих примерах:
field_name CHAR TERMINATED BY "," "SUBSTR(:field_name, 1, 10)" employee_name POSITION 32-62 CHAR "UPPER(:ename)" salary position 75 CHAR "TO_NUMBER(:sal,'$99,999.99')" commission INTEGER EXTERNAL "":commission * 100"
Как не трудно заметить, применение SQL-операций и функций к значениям полей перед их загрузкой в таблицы помогает осуществлять преобразование данных прямо во время их загрузки.
Задаваемые в управляющем файле параметры командной строки
Утилита SQL*Loader позволяет задавать в командной строке ряд параметров времени выполнения при вызове ее исполняемого файла. Параметры, значения которых должны оставаться одинаковыми для всех заданий, обычно задаются в отдельном файле параметров, позволяющем далее использовать командную строку просто для запуска заданий SQL*Loader, как в интерактивном режиме, так и в виде запланированных пакетных заданий. В командной строке указываются лишь те параметры, которые касаются конкретно времени выполнения, вместе с именем и местом размещения управляющего файла.
В качестве альтернативного варианта, параметры времени выполнения еще можно также указывать и внутри самого управляющего файла с применением конструкции OPTIONS. Да, параметры времени выполнения всегда можно задавать при вызове SQL*Loader, но если они будут часто повторяться, тогда все-таки лучше указывать их в управляющем файле с помощью конструкции OPTIONS. Использовать конструкцию OPTIONS особенно удобно в случае, когда длина информации, подлежащей указанию в командной строке SQL*Loader, настолько велика, что превышает принятый в операционной системе максимальный размер командной строки.
На заметку! Задание параметра в командной строке будет приводить к переопределению тех значений, которые были указаны для него в управляющем файле.
В следующих подразделах описываются некоторые наиболее важные параметры, которые можно задавать в управляющем файле конструкцией OPTIONS.
Параметр USERID
Параметр USERID позволяет указывать имя и пароль того пользователя в базе данных, который обладает необходимыми для осуществления загрузки данных привилегиями:
USERID = samalapati/sammyy1
Параметр CONTROL
Параметр CONTROL позволяет указывать имя управляющего файла, который должен использоваться для сеанса SQL*Loader. Этот управляющий файл может включать в себя спецификации всех параметров загрузки. Конечно, выполнять загрузку данных можно и при помощи вводимых вручную команд, но применение управляющего файла обеспечивает большую гибкость и позволяет автоматизировать процесс загрузки.
CONTROL = '/test01/app/oracle/oradata/load/finance.ctl'
Параметр DATA
Параметр DATA позволяет указывать имя входного файла данных, который должен использоваться для загрузки данных. По умолчанию имя такого файла всегда оканчивается расширением .dat. Обратите внимание на то, что подлежащие загрузке данные вовсе не обязательно должны находиться внутри отдельного файла данных. При желании они могут также включаться в управляющий файл, сразу после деталей, касающихся самого процесса загрузки.
DATA = '/test02/app/oracle/oradata/load/finance.dat'
Параметры BINDSIZE и ROWS
Параметры BINDSIZE и ROWS позволяют задавать размер, который должен иметь массив связывания в обычном режиме загрузки. При выполнении загрузки в обычном режиме утилита SQL*Loader не вставляет данные в таблицу строка за строкой. Вместо этого она вставляет в таблицу сразу целый набор строк; этот набор строк и называется массивом связывания (bind array), и за его размер отвечает либо параметр BINDSIZE, либо параметр ROWS.
Параметр BINDSIZE задает размер массива связывания в байтах. В системе автора этот размер по умолчанию составлял 256 000 байт.
BINDSIZE = 512000
Что касается параметра ROWS, то он не накладывает никаких ограничений на количество байтов в массиве связывания. Вместо этого он накладывает ограничение на количество строк, которое может содержаться в каждом массиве связывания; SQL*Loader перемножает это значение в параметре ROWS на подсчитанное значение размера каждой строки в таблице. В системе автора количество строк в параметр ROWS по умолчанию составляло 64.
ROWS = 64000
На заметку! В случае задания значений и для параметра BINDSIZE, и для параметра ROWS, утилита SQL*Loader использует для массива связывания меньшее из этих двух значений.
Параметр DIRECT
В случае указания для параметра DIRECT значения true (DIRECT=true) утилита SQL*Loader использует прямой режим загрузки, а не обычный. По умолчанию для этого параметра устанавливается значение false (DIRECT=false), означающее, что по умолчанию должен использоваться обычный режим загрузки.
Параметр ERRORS
Параметр ERRORS позволяет указывать, сколько максимум ошибок может происходить, прежде чем выполнение задания SQL*Loader должно завершаться. В большинстве систем для этого параметра по умолчанию устанавливается значение 50. При нежелании терпеть никакие ошибки, можно устанавливать для этого параметра значение 0:
ERRORS = 0
Параметр LOAD
С помощью параметра LOAD можно указывать, сколько максимум логических записей разрешено загружать в таблицу. По умолчанию можно загружать все записи, которые содержатся во входном файле данных.
LOAD = 10000
Параметр LOG
Параметр LOG позволяет указывать имя файла журнала (log file), который утилита SQL*Loader должна использовать в процессе загрузки. Файл журнала, который будет показан чуть позже, предоставляет массу полезной информации о сеансе SQL*Loader.
LOG = '/u01/app/oracle/admin/finance/logs/financeload.log'
Параметр BAD
Параметр BAD позволяет указывать имя и место размещения файла некорректных записей (bad file). В случае отклонения каких-то записей из-за наличия в них ошибок, связанных с форматированием данных, утилита SQL*Loader будет заносить все эти записи в упомянутый файл. Например, размер поля может превышать заданную для него длину и, как следствие, отвергаться утилитой SQL*Loader. Обратите внимание на то, что записи могут отклоняться не только утилитой SQL*Loader, но и самой базой данных. Например, при попытке вставить строки с дублированными значениями первичных ключей, база данных будет отклонять их вставку. Такие записи тоже будут помещаться в файл некорректных записей. В случае не указания имени файла некорректных записей явным образом, Oracle будет создавать такой файл автоматически и использовать для него принятое по умолчанию имя с именем управляющего файла в качестве префикса.
BAD = '/u01/app/oracle/load/financeload.bad'
Параметр SILENT
По умолчанию SQL*Loader отображает на экране ответные сообщения и тем самым информирует о ходе процесса загрузки. При желании отображение этих сообщений можно отключать с помощью параметра SILENT. Для этого параметра можно устанавливать несколько значений. Например, отключать отображение всех видов сообщений можно путем установки для него значения ALL:
SILENT = ALL
Параметры DISCARD и DISCARDMAX
Все записи, которые отвергаются во время загрузки из-за несоответствия указанным в управляющем файле критериями выбора записей, помещаются в файл отвергнутых записей (discard file). По умолчанию этот файл не создается. Oracle будет создавать его только при наличии отвергнутых записей, да и то лишь в том случае, если он был явно задан в управляющем файле. Для указания в управляющем файле имени и места размещения файла отвергнутых записей как раз и применяется параметр DISCARD, например:
DISCARD = 'test01/app/oracle/oradata/load/finance.dsc'
По умолчанию SQL*Loader не накладывает никаких ограничений на количество записей; следовательно, отвергаться могут и все логические записи. Посредством параметра DISCARDMAX, однако, можно брать и ограничивать количество отвергаемых записей.
Совет. Как в файл некорректных, так и в файл отвергнутых записей, все записи помещаются в своем исходном формате. Это позволяет легко, особенно во время загрузки больших объемов данных, редактировать эти файлы надлежащим образом и использовать их для повторной загрузки данных, которые не удалось загрузить во время первоначального сеанса загрузки.
Параметр PARALLEL
Параметр PARALLEL позволяет указывать, разрешено ли SQL*Loader запускать по несколько параллельных сеансов при выполнении загрузки в прямом режиме:
sqlldr USERID=salapati/sammyy1 CONTROL=load1.ctl DIRECT=true PARALLEL=true
Параметр RESUMABLE
С помощью параметра RESUMABLE можно включать предлагаемую Oracle функцию Resumable Space Allocation (возобновление функционирования после устранения проблемы выделения пространства). Если эта функция включена, то при возникновении во время загрузки данных проблем с пространством, выполнение задания будет просто приостанавливаться, и тогда администратор сможет получать соответствующее уведомление и выделять больше пространства, чтобы выполнение задания могло продолжиться без проблем. О функции Resumable Space Allocation более подробно рассказывалось в главе 8. По умолчанию для параметра RESUMABLE устанавливается значение false, означающее, что функция Resumable Space Allocation отключена. Для ее включения достаточно просто установить для этого параметра значение true (RESUMABLE=true).
Параметр RESUMABLE_NAME
Параметр RESUMABLE_NAME позволяет указывать конкретное задание по загрузке, которое должно поддаваться возобновлению при использовании функции Resumable Space Allocation. По умолчанию устанавливаемое для него значение образуется путем объединения имени пользователя, идентификатора сеанса и идентификатора экземпляра.
RESUMABLE_NAME = finance1_load
Параметр RESUMABLE_TIMEOUT
Параметр RESUMABLE_TIMEOUT может задаваться только в случае установки для параметра RESUMABLE значения true. Он позволяет определять таймаут, т.е. максимальное время, на которое выполнение операции может откладываться в случае столкновения со связанной с выделением пространства проблемой. При невозможности устранить проблему в пределах этого времени, выполнение операции будет прерываться. По умолчанию этот таймаут составляет 7 200 секунд.
RESUMABLE_TIMEOUT = 3600
Параметр SKIP
Параметр SKIP очень удобно использовать в ситуациях, когда SQL*Loader прерывает выполнение задания из-за каких-то ошибок, но уже успевает зафиксировать некоторые строки. Он позволяет пропускать определенное количество строк во входном файле при выполнении задания SQL*Loader во второй раз. Альтернативным вариантом является усечение таблицы и перезапуск задания SQL*Loader с самого начала, который не очень удобен, если в таблицы базы данных уже было загружено приличное количество строк.
SKIP = 235550
В этом примере предполагается, что в первый раз задание было прервано после успешной загрузки 235 549 строк. Получить подобную информацию можно, либо заглянув в использованный во время данного сеанса загрузки файл журнала, либо выполнив запрос непосредственно к самой таблице.
Генерирование данных во время загрузки
Утилита SQL*Loader позволяет генерировать данные для загрузки столбцов. Это означает, что выполнять загрузку можно и без всякого использования файла данных. Чаще всего, однако, данные генерируются лишь для одного или нескольких столбцов при выполнении общей загрузки из файла данных. Ниже приведен перечень тех типов данных, которые позволяет генерировать SQL*Loader.
- Постоянное значение (constant value). С использованием конструкции CONSTANT можно устанавливать для столбца постоянное значение. Например, в следующем примере эта конструкция указывает, что все строки, заполняемые во время данного сеанса, должны иметь в столбце loaded_by значение sysadm:
loaded_by CONSTANT "sysadm"
- Значение выражения (expression value). С помощью конструкции EXPRESSION можно устанавливать для столбца значение SQL-операции или функции PL/SQL, как показано ниже:
column_name EXPRESSION "SQL string"
- Номер записи в файле данных (datafile record number). С применением конструкции RECNUM можно устанавливать для столбца в качестве значения номер записи, приведшей к загрузке данной строки:
record_num RECNUM
- Системная дата (system date). Посредством переменной sysdate можно устанавливать для столбца в качестве значения дату выполнения загрузки данных:
loaded_date sysdate
- Последовательность (sequence). С помощью функции SEQUENCE можно генерировать уникальные значения для загрузки столбца. В следующем примере эта функция указывает, что должно использоваться текущее максимальное значение последовательности loadseq и что это значение при каждой вставке строки должно увеличиваться на единицу:
loadseq SEQUENCE(max,1)
Вызов SQL*Loader
Вызывать утилиту SQL*Plus можно несколькими способами. Стандартный синтаксис для вызова SQL*Loader выглядит следующим образом:
SQLLDR ключевое_слово=значение [,ключевое_слово=значение,...]
Ниже приведен пример вызова SQL*Loader:
$ sqlldr USERID=nicholas/nicholas1 CONTROL=/u01/app/oracle/finance/finance.ctl \ DATA=/u01/app/oracle/oradata/load/finance.dat \ LOG=/u01/aapp/oracle/finance/log/finance.log \ ERRORS=0 DIRECT=true SKIP=235550 RESUMABLE=true RESUMABLE_TIMEOUT=7200
На заметку! При вызове утилиты SQL*Loader из командной строки символ обратной косой черты (\) в конце каждой строки означает, что команда продолжается на следующей строке. Задавать параметры командной строки можно, как указывая их имена, так и указывая их позиции. Например, параметр, отвечающий за имя пользователя и пароль, всегда следует за ключевым словом sqlldr. В случае пропуска параметра Oracle будет использовать принятое по умолчанию значение для этого параметра. При желании после указания каждого параметра можно добавлять символ запятой.
Как не трудно заметить, чем больше параметров требуется использовать, тем больше информации приходится предоставлять в командной строке. Такой подход имеет два недостатка. Во-первых, в случае допущения опечаток или других ошибок получается путаница. Во-вторых, в некоторых операционных системах может существовать ограничение на количество символов, которое может вводиться в командной строке. К счастью, то же самое задание может быть запущено и с помощью следующей команды, которая является куда менее сложной:
$ sqlldr PARFILE=/u01/app/oracle/admin/finance/load/finance.par
Параметр PARFILE представляет файл параметров (parameter file), т.е. файл, который может содержать значения для всех командных параметров. Например, для демонстрируемых в этой главе спецификаций загрузки этот файл выглядит так:
USERID=nicholas/nicholas1 CONTROL='/u01/app/oracle/admin/finance/finance.ctl' DATA='/app/oracle/oradata/load/finance.dat' LOG='/u01/aapp/oracle/admin/finance/log/finance.log' ERRORS=0 DIRECT=true SKIP=235550 RESUMABLE=true RESUMABLE_TIMEOUT=7200
Использование файла параметров является более элегантным подходом, нежели ввод всех параметров в командной строке, а также более логичным, когда необходимо регулярно выполнять задания с одинаковыми параметрами. Любая опция, указываемая в командной строке, будет переопределять значение, которое было установлено для данного параметра внутри файла параметров.
При желании применять командную строку, но исключить вероятность подглядывания кем-нибудь вводимого пароля, SQL*Loader можно вызывать следующим образом:
$ sqlldr CONTROL=control.ctl
В таком случае SQL*Loader будет отображать приглашение на ввод имени пользователя и пароля.
Журнальный файл SQL*Loader
В журнальном файле утилиты SQL*Loader содержится масса информации касательно ее сеанса работы. В нем сообщается о том, сколько записей должно было быть загружено и сколько было загружено на самом деле, а также какие записи не удалось загрузить и почему. Кроме того, в нем описываются столбцы, которые были указаны для полей в управляющем файле SQL*Loader. В листинге 13.2 приведен пример типичного журнального файла SQL*Loader.
SQL*Loader: Release 11.1.0.0.0 - Production on Sun Aug 24 14:04:26 2008 Control File: /u01/app/oracle/admin/fnfactsp/load/test.ctl Data File: /u01/app/oracle/admin/fnfactsp/load/test.ctl Bad File: /u01/app/oracle/admin/fnfactsp/load/test.badl Discard File: none specified (Allow all discards) Number to load: ALL Number to skip: 0 Errors allowed: 0 Bind array: 64 rows, maximum of 65536 bytes Continuation: none specified Path used: Conventional Table TBLSTAGE1, loaded when ACTIVITY_TYPE != 0X48(character 'H') and ACTIVITY_TYPE != 0X54(character 'T') Insert option in effect for this table: APPEND TRAILING NULLCOLS option in effect Column Name Position Len Term Encl Datatype ----------------------- -------- ----- ---- ---- --------- COUNCIL_NUMBER FIRST * , CHARACTER COMPANY NEXT * , CHARACTER ACTIVITY_TYPE NEXT * , CHARACTER RECORD_NUMBER NEXT * , CHARACTER FUND_NUMBER NEXT * , CHARACTER BASE_ACCOUNT_NMBER NEXT * , CHARACTER FUNCTIONAL_CODE NEXT * , CHARACTER DEFERRED_STATUS NEXT * , CHARACTER CLASS NEXT * , CHARACTER UPDATE_DATE SYSDATE UPDATED_BY CONSTANT Value is 'sysadm' BATCH_LOADED_BY CONSTANT Value is 'sysadm' /* Discarded Records Section: Gives the complete list of discarded records, including reasons why they were discarded.*/ /* Раздел отвергнутых записей: содержит полный перечень отвергнутых записей вместе с описанием причин, по которым они были отвергнуты.*/ Record 1: Discarded - failed all WHEN clauses. Record 1527: Discarded - failed all WHEN clauses. Table TBLSTAGE1: /* Number of Rows: Gives the number of rows successfully loaded and the number of rows not loaded due to errors or because they failed the WHEN conditions, if any. Here, two records failed the WHEN condition*/ /* Раздел количества строк: показывает, сколько строк было успешно загружено и сколько не было загружено из-за ошибок или не удовлетворения условий WHEN, если таковые задавались.*/ 1525 Rows successfully loaded. 0 Rows not loaded due to data errors. 2 Rows not loaded because all WHEN clauses were failed. 0 Rows not loaded because all fields were null. /* Memory Section: Gives the bind array size chosen for the data load*/ /* Раздел памяти: показывает, массив какого размера был выбран для загрузки данных*/ Space allocated for bind array: 99072 bytes(64 rows) Read buffer bytes: 1048576 /* Logical Records Section: Gives the total records, number of rejected and discarded records.*/ /* Раздел логических записей: показывает, сколько всего логических записей было пропущено, считано, отклонено и отвергнуто.*/ Total logical records skipped: 0 Total logical records read: 1527 Total logical records rejected: 0 Total logical records discarded: 2 /*Date Section: Gives the day and date of the data load.*/ /*Раздел даты: показывает дату и время выполнения загрузки данных.*/ Run began on Sun Mar 06 14:04:26 2009 Run ended on Sun Mar 06 14:04:27 2009 /*Time section: Gives the time taken for completing the data load.*/ /*Раздел времени: показывает, сколько времени заняло выполнение загрузки данных.*/ Elapsed time was: 00:00:01.01 CPU time was: 00:00:00.27
При изучении журнального файла основное внимание следует обращать на то, сколько всего логических записей было считано и какие записи были пропущены, отклонены или отвергнуты. В случае столкновения с какими-то трудностями при выполнении задания журнальный файл является первым местом, куда следует заглядывать для выяснения того, загружаются записи данных или нет.
Использование кодов завершения
В журнальном файле фиксируется масса информации касательно процесса загрузки, но Oracle также позволяет перехватывать после каждого выполнения загрузки код завершения (exit code). Такой подход предоставляет возможность проверять результаты загрузки, когда та выполняется посредством задания cron или сценария оболочки. В случае использования сервера Windows для планирования выполнения заданий по загрузке можно применять команду at. Ниже перечислены ключевые коды завершения, которые могут встречаться в операционных системах UNIX и Linux:
- EX_SUCC 0 обозначает, что все строки были загружены успешно;
- EX_FAIL 1 обозначает, что были обнаружены какие-то ошибки в командной строке или синтаксисе;
- EX_WARN 2 обозначает, что были отвергнуты некоторые или все строки;
- EX_FTL 3 обозначает, что произошли какие-то ошибки в операционной системе.
Использование метода загрузки в прямом режиме
Пока что утилита SQL*Loader рассматривалась с точки зрения обычного режима загрузки. Как мы помним, метод выполнения загрузки в обычном режиме предусматривает использование SQL-операторов INSERT для вставки данных в таблицы в объеме одного массива связывания за раз. Метод выполнения загрузки в прямом режиме не предусматривает применение SQL-операторов для размещения данных в таблицах, вместо этого он подразумевает форматирование блоков данных Oracle и их запись непосредственно в файлы базы данных. Такой процесс прямой записи устраняет большинство из накладных расходов, которые имеют место при выполнении SQL-операторов для загрузки таблиц. Поскольку метод загрузки в прямом режиме не предусматривает борьбы за ресурсы базы данных, он будет работать гораздо быстрее метода загрузки в обычном режиме. Для загрузки больших объемов данных прямой режим загрузки подходит больше всего и может оказываться единственно эффективным методом по той простой причине, что выполнение загрузки в обычном режиме потребует больше времени, чем доступно.
Помимо очевидного преимущества, заключающегося в сокращении времени загрузки, прямой режим еще позволяет перестраивать индексы и выполнять предварительную сортировку данных. В частности, он обладает такими достоинствами по сравнению с обычным режимом загрузки.
- Загрузка происходит гораздо быстрее, чем при применении метода загрузки в обычном режиме, поскольку SQL-операторы не используются.
- Для выполнения записи данных в базу данных применяются многоблочные асинхронные операции ввода-вывода, поэтому запись происходит быстро.
- Доступна возможность выполнения предварительной сортировки данных с помощью эффективных сортировочных подпрограмм.
- За счет установки для параметра UNRECOVERABLE значения Y (UNRECOVERABLE=Y) может предотвращаться осуществление во время загрузки записи каких-либо данных повторного выполнения.
- За счет применения механизма временного хранения построение индексов может производиться более эффективно, чем при использовании обычного режима загрузки.
На заметку! При обычном режиме загрузки будут всегда генерироваться записи повторного выполнения, в то время как при прямом режиме загрузки такие записи будут генерироваться только в определенных условиях. Кроме того, при прямом режиме не будут срабатывать триггеры вставки, которые в обычном режиме всегда срабатывают во время процесса загрузки. И, наконец, в отличие от обычного режима, прямой режим будет исключать возможность внесения пользователями каких-либо изменений в загружаемую данными таблицу.
Несмотря на все сказанное выше, у метода выполнения загрузки в прямом режиме также имеются и некоторые серьезные ограничения. В частности, его нельзя применять при следующих условиях:
- при использовании кластеризованных таблиц;
- при выполнении загрузки данных одновременно в родительские и дочерние таблицы;
- при выполнении загрузки данных в столбцы VARRAY или BFILE;
- при выполнении загрузки среди гетерогенных платформ с использованием Oracle Net;
- при желании использовать во время загрузки SQL-функции.
На заметку! В прямом режиме загрузки нельзя использовать какие-либо SQL-функции. Если необходимо выполнить загрузку данных большого объема и также преобразовать их во время процесса загрузки, это может привести к проблемам. Обычный режим загрузки будет позволять использовать SQL-функции для преобразования данных, но он является очень медленным по сравнению с прямым режимом. Поэтому для выполнения загрузки больших объемов данных может быть предпочтительнее применять более новые технологии для загрузки и преобразования данных, наподобие внешних таблиц или табличных функций.
Параметры, которые можно применять в случае использования метода загрузки в прямом режиме
Несколько параметров в SQL*Loader предназначены специально для использования вместе с методом загрузки в прямом режиме или больше подходят для этого метода, чем для метода загрузки в обычном режиме. Эти параметры описаны ниже.
- DIRECT. При желании использовать метод загрузки в прямом режиме для конструкции DIRECT должно обязательно устанавливаться значение true (DIRECT=true).
- DATA_CACHE. Параметр DATA_CACHE удобно использовать в случае неоднократной загрузки одних и тех же данных или значений даты и времени (TIMESTAMP) во время выполнения загрузки в прямом режиме. Утилите SQL*Loader приходится преобразовывать данные о дате и времени всякий раз, когда они ей встречаются. Поэтому при наличии дублированных значений даты и времени в загружаемых данных установка параметра DATA_CACHE позволит сократить количество излишних операций по преобразованию этих значений и, следовательно, уменьшить время обработки. По умолчанию параметр DATA_CACHE предусматривает сохранение в кэше 1000 значений. Если в данных нет никаких дублированных значений даты и времени или есть, но очень мало, этот параметр можно вообще отключить, установив для него значение 0 (DATA_CACHE=0).
- ROWS. Параметр ROWS играет важную роль, поскольку позволяет указывать, сколько строк утилита SQL*Loader должна считывать из входного файла данных, прежде чем сохранять вставки в таблицах. Он применяется для определения верхнего предела объема данных, теряемых в случае возникновения сбоя в работе экземпляра во время выполнения длинного задания SQL*Loader. После считывания указанного в этом параметре количества строк SQL*Loader будет останавливать загрузку данных до тех пор, пока содержимое всех буферов данных не будет успешно записано в файлы данных. Это процесс называется сохранением данных (data save). Например, в случае наличия у SQL*Loader возможности загружать около 10 000 строк в минуту установка для параметра ROWS значения 150 000 (ROWS=150000) приведет к тому, что сохранение данных будет происходить каждые 15 минут.
- UNRECOVERABLE. Параметр UNRECOVERABLE позволяет сводить к минимуму использование журнала повторного выполнения во время загрузки данных в прямом режиме (он задается в управляющем файле).
- SKIP_INDEX_MAINTENANCE. Параметр SKIP_INDEX_MAINTENANCE, когда включен (SKIP_INDEX_MAINTENANCE=true), указывает SQL*Loader не беспокоиться об обслуживании индексов во время загрузки. По умолчанию для него устанавливается значение false.
- SKIP_UNUSABLE_INDEXES. Установка значения true для параметра SKIP_UNUSABLE_INDEXES будет гарантировать выполнение утилитой SQL*Loader загрузки даже таблиц, индексы которых находятся в непригодном для использования состоянии. Обслуживаться SQL*Loader, однако, эти индексы не будут. Значение, устанавливаемое для этого параметра по умолчанию, зависит от того, какое значение выбрано для параметра инициализации SKIP_UNUSABLE_INDEXES, для которого по умолчанию устанавливается true.
- SORTED_INDEXES. Параметр SORTED_INDEXES уведомляет SQL*Loader о выполнении сортировки данных на уровне определенных индексов, что помогает ускорять процесс загрузки.
- COLUMNARRAYROWS. Этот параметр позволяет указывать, сколько строк должно загружаться перед построением буфера потоков. Например, в случае установки для него значения 100 000 (COLUMNARRAYROWS=100000), сначала будет выполняться загрузка 100 000 строк. Следовательно, получается, что размер массива столбцов во время выполнения загрузки в прямом режиме будет зависеть от значения этого параметра. У автора на сервере UNIX значение этого параметра по умолчанию составляло 5000 строк.
- STREAMSIZE. Параметр STREAMSIZE позволяет задавать размер буфера потока. У автора на сервере UNIX, например, этот размер по умолчанию составлял 256 000 строк; при желании увеличить его, можно было бы установить параметр STREAMSIZE, например, так: STREAMSIZE=51200.
- MULTITHREADING. При включении параметра MULTITHREADING операции преобразования массивов столбцов в буферы потоков и затем загрузки этих буферов потоков выполняются параллельно. На машинах с несколькими ЦП этот параметр по умолчанию включен (имеет значение true). При желании его можно отключить, установив в false (MULTITHREADING =false).
Управление ограничениями и триггерами при использовании метода загрузки в прямом режиме
Метод загрузки в прямом режиме подразумевает осуществление вставки данных прямо в файлы данных за счет форматирования блоков данных. Поскольку операторы INSERT не используются, никакого системного применения ограничений и триггеров таблиц при прямом режиме загрузки не происходит. Вместо этого все триггеры, равно как и некоторые ограничения целостности, отключаются. Утилита SQL*Loader автоматически отключает все внешние ключи и проверочные ограничения целостности, но ненулевые, уникальные и связанные с первичными ключами все равно поддерживает. По завершении выполнения задания SQL*Loader снова автоматически включает все отключенные ограничения, если была указана конструкция REENABLE. В противном случае их потребуется включить вручную. Что касается триггеров, то они всегда автоматически включаются снова после окончания процесса загрузки.
Советы по оптимальному использованию SQL*Loader
Чтобы использовать SQL*Loader оптимальным образом, особенно при выполнении загрузки данных большого объема и/или наличии множества индексов и ограничений, ассоциируемых с таблицами в базе данных, рекомендуется поступать следующим образом.
- Стараться как можно чаще применять метод загрузки в прямом режиме. Он работает гораздо быстрее метода загрузки в обычном режиме.
- Использовать везде, где возможно (при прямом режиме загрузке), опцию UNRECOVERABLE= true. Это позволит экономить приличное количество времени, потому что новые загружаемые данные не нужно будет фиксировать в файле журнала повторного выполнения. Возможность выполнения восстановления носителя при этом все равно остается в силе для всех остальных пользователей базы данных, плюс в случае возникновения проблемы всегда можно запустить новый сеанс SQL*Loader.
- Сводить использование параметров NULLIF и DEFAULTIF к минимуму. Эти конструкции должны обязательно подвергаться тестированию в случае каждой строки, для которой они применяются.
- Ограничивать количество операций по преобразованию типов данных и наборов символов, потому что они замедляют процесс обработки.
- Везде, где возможно, использовать для полей позиции, а не разделители. У утилиты SQL*Loader получается гораздо быстрее переходить от поля к полю, когда ей предоставляются их позиции.
- Отображать физические и логические записи по схеме “один к одному”.
- Отключать ограничения перед началом процесса загрузки, потому что они будут замедлять его. Конечно, при включении ограничений снова иногда могут появляться ошибки, но гораздо более быстрое выполнение загрузки данных того стоит, особенно в случае крупных таблиц.
- Указывать в случае использования метода загрузки в прямом режиме конструкцию SORTED_INDEXES для оптимизации скорости выполнения загрузки.
- Удалять ассоциируемые с таблицами индексы перед началом процесса загрузки в случае выполнения загрузки больших объемов данных. При невозможности удалить индексы можно делать их непригодными для использования и применять во время загрузки конструкцию SKIP_UNUSABLE_INDEXES, а в случае выполнения загрузки в прямом режиме — еще и конструкцию SKIP_INDEX_MAINTENANCE.
Некоторые полезные приемы для загрузки данных с помощью SQL*Loader
Применение SQL*Loader является эффективным подходом, но не без своей доли хитростей. В этом разделе рассказывается о том, как выполнять во время загрузки данных некоторые особые виды операций.
Использование конструкции WHEN во время операций загрузки данных
Конструкцию WHEN можно использовать во время операций загрузки данных для ограничения загружаемых данных только теми строками, которые отвечают определенным условиям. Например, с ее помощью можно делать так, чтобы из файла данных выбирались только те записи, в которых присутствует поле, удовлетворяющее конкретным критериям. Ниже приведен пример, демонстрирующий применение конструкции WHEN в управляющем файле SQL*Loader:
LOAD DATA INFILE * INTO TABLE stagetbl APPEND WHEN (activity_type <>'H') and (activity_type <>'T') FIELDS TERMINATED BY ',' TRAILING NULLCOLS /* Здесь идут столбцы таблицы...*/ BEGINDATA /* Здесь идут данные...*/
Здесь условие в конструкции WHEN указывает, что все записи, в которых поле, соответствующее столбцу activity_type в таблице stagetbl, не содержит ни H, ни T, должны отклоняться.
Загрузка имени пользователя в таблицу
Для вставки имени пользователя в таблицу во время процесса загрузки можно использовать псевдопеременную user. Ниже приведен пример, иллюстрирующий применение этой переменной. Обратите внимание, что в целевой таблице stagetb1 должен обязательно присутствовать столбец по имени loaded_by для того, чтобы утилита SQL*Loader могла вставить в него имя пользователя.
LOAD DATA INFILE * INTO TABLE stagetbl INSERT (loaded_by "USER") /* Здесь идут столбцы таблицы, а следом за ними и сами данные...*/
Загрузка больших полей данных в таблицу
При попытке загрузить в таблицу любое поле размером более 255 байт, даже в случае присвоения столбцу типа VARCHAR(2000) или CLOB, утилите SQL*Loader не удастся произвести загрузку данных, и потому она будет выдавать сообщение об ошибке Field in datafile exceeds maximum length (Поле в файле данных превышает максимально допустимую длину). Для загрузки большого поля необходимо обязательно указывать в управляющем файле размер соответствующего ему столбца в таблице при отображении столбцов таблицы на поля данных, как показано в следующем примере (где соответствующий столбец имеет имя text):
LOAD DATA INFILE '/u01/app/oracle/oradata/load/testload.txt' INSERT INTO TABLE test123 FIELDS TERMINATED BY ',' (text CHAR(2000))
Загрузка номера последовательности в таблицу
Предположим, что есть последовательность по имени test_seq и требуется, чтобы ее номер увеличивался при загрузке в таблицу каждой новой записи данных. Обеспечить такое поведение можно следующим образом:
LOAD DATA INFILE '/u01/app/oracle/oradata/load/testload.txt' INSERT INTO TABLE test123 (test_seq.nextval,. . .)
Загрузка данных из таблицы в файл ASCII
Иногда бывает необходимо извлекать данные из таблицы базы данных в плоские файлы, например, с целью последующего их использования для загрузки данных в таблицы Oracle, находящиеся в другом месте. При наличии множества таких таблиц можно написать сложные сценарии, но если речь идет о всего лишь нескольких таблицах, то вполне подойдет и следующий простой метод извлечения данных с помощью команд SQL*Plus:
SET TERMOUT OFF SET PAGESIZE 0 SET ECHO OFF SET FEED OFF SET HEAD OFF SET LINESIZE 100 COLUMN customer_id FORMAT 999,999 COLUMN first_name FORMAT a15 COLUMN last_name FORMAT a25 SPOOL test.txt SELECT customer_id,first_name,last_name FROM customer; SPOOL OFF
Также для загрузки данных в текстовые файлы можно применять пакет UTL_FILE.
Удаление индексов перед загрузкой больших массивов данных
Есть две основных причины, по которым следует всерьез задумываться об удалении индексов, ассоциируемых с большой таблицей, перед выполнением загрузки данных в прямом режиме с использованием опции NOLOGGING. Во-первых, загрузка вместе с поставляемыми с табличными данными индексами может занимать больше времени. Во-вторых, в случае оставления индексов активными, внесение изменений в их структуру во время загрузки будет приводить к генерации записей повторного выполнения (redo records).
Совет. При выборе варианта выполнения загрузки данных с использованием опции NOLOGGING будет генерироваться приличное количество данных повторного выполнения для обозначения вносимых в индексы изменений. Помимо этого еще кое-какие данные повторного выполнения будут генерироваться и для поддержки словаря данных, даже во время выполнения самой операции загрузки данных с опцией NOLOGGING. Поэтому наилучшей стратегией в таком случае является удаление индексов и их повторное построение после создания таблиц.
При выполнении загрузки в прямом режиме где-то на полпути может происходить сбой в работе экземпляра, заканчиваться пространство, необходимое утилите SQL*Loader для осуществления обновления индекса, или встречаться дублированные значения ключей индексов. Все подобные ситуации называются условием приведения индексов в непригодное состояние, потому что после восстановления экземпляра индексы становятся непригодными для использования. Во избежание этих ситуаций тоже может быть лучше создавать индексы после завершения процесса загрузки.
Выполнение загрузки данных в несколько таблиц
Для выполнения загрузки данных в несколько таблиц можно применять все ту же утилиту SQL*Loader. Ниже приведен пример выполнения загрузки данных сразу в две таблицы:
LOAD DATA INFILE * INSERT INTO TABLE dept WHEN recid = 1 (recid FILLER POSITION(1:1) INTEGER EXTERNAL, deptno POSITION(3:4) INTEGER EXTERNAL, dname POSITION(8:21) CHAR) INTO TABLE emp WHEN recid <> 1 (recid FILLER POSITION(1:1) INTEGER EXTERNAL, empno POSITION(3:6) INTEGER EXTERNAL, ename POSITION(8:17) CHAR, deptno POSITION(19:20) INTEGER EXTERNAL)
В этом примере данные из одного и того же файла данных загружаются одновременно в две таблицы — dept и emp — на основании того, содержится в поле recid значение 1 или нет.
Перехват кодов ошибок в SQL*Loader
Ниже представлен простой пример того, как можно перехватывать выдаваемые SQL*Loader коды ошибок:
$ sqlldr PARFILE=test.par
retcode=$?
if [[retcode !=2 ]]
then
mv ${ImpDir}/${Fil} ${InvalidLoadDir}/.${Dstamp}.${Fil}
writeLog $func "Load Error" "load error:${retcode} on file ${Fil}"
else
sqlplus / ___EOF
/* Здесь можно размещать любые SQL-операторы для обработки данных,
которые были загружены успешно */
___EOF
Загрузка XML-данных в XML-базу данных Oracle
Утилита SQL*Loader поддерживает использование для столбцов типа данных XML. При наличии такого столбца, она, соответственно, может применяться для загрузки в таблицу XML-данных. Утилита SQL*Loader воспринимает XML-столбцы как столбцы типа CLOB (Character Large Object — большой символьный объект). Вдобавок Oracle позволяет загружать XML-данные как из первичного файла данных, так и из внешнего файла формата LOB (Large Object — большой объект), и использовать как поля фиксированной длины, так и поля с разделителями, а также считывать все содержимое файла в одно единственного поле типа LOB.


