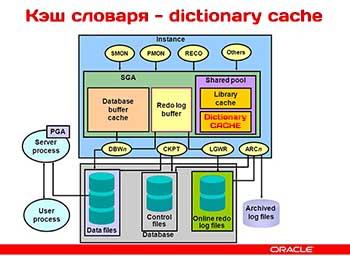
 Кэш словаря (dictionary cache), также известный как кэш строк (row cache), потому что фактически используется для кэширования отдельных строк данных из словаря, – это место, где Oracle хранит фрагменты описаний объектов. Получить сводную информацию о содержимом этого кэша можно с помощью запроса к представлению
Кэш словаря (dictionary cache), также известный как кэш строк (row cache), потому что фактически используется для кэширования отдельных строк данных из словаря, – это место, где Oracle хранит фрагменты описаний объектов. Получить сводную информацию о содержимом этого кэша можно с помощью запроса к представлению v$rowcache. Ниже приводится результат такого запроса, полученный в действующем экземпляре 10g.
Если выполнить предлагаемый запрос к v$rowcache в 11g, можно заметить пару аномалий. Один из кэшей (cache# 11: dc_object_ids) отсутствует в v$rowcache, хотя остается доступным в v$rowcache_parent как cache# 11, но переименованный в dc_objects; и cache# 7 потерял своего родителя, который, похоже, переместился в cache# 10. Являются ли эти аномалии ошибками или были внедрены преднамеренно, я не знаю, но есть явные признаки, что часть кода, отображающего структуры кэша словаря, действует неправильно в версии 11g (структура x$kqrpd являет собой образчик полной путаницы – в любом случае, она выглядит не так, как можно было бы предполагать).
Если выполнить этот же запрос в Oracle 9i, можно заметить, что каждый элемент выводится дважды – в экземпляре 9.2.0.8, например, выводятся все восемь комбинаций для значений parameter, type и subordinate#. Этот эффект обусловлен влиянием (только в 9.2.0.8) параметра _more_rowcache_latches, который по умолчанию имеет значение true.
select
cache#, parameter, type, subordinate#, count, usage,
fixed, gets, getmisses
from
v$rowcache
order by
cache#, type, subordinate#
;
CACHE# PARAMETER TYPE SUB COUNT USAGE FIXED GETS GETMISSES
------ -------------------- ----------- ---- ------ ------ ------ ------- ---------
0 dc_tablespaces PARENT 8 8 0 62439 28
...
7 dc_users PARENT 10 10 0 157958 52
7 dc_users SUBORDINATE 0 0 0 0 0 0
7 dc_users SUBORDINATE 1 5 5 0 2600 31
7 dc_users SUBORDINATE 2 0 0 0 0 0
8 dc_objects PARENT 917 917 55 37716 3200
8 dc_object_grants SUBORDINATE 0 30 30 0 2079 196
9 dc_qmc_cache_entries PARENT 0 0 0 0 0
10 dc_usernames PARENT 11 11 0 4075 42
11 dc_object_ids PARENT 1225 1225 55 171218 2886
12 dc_constraints PARENT 1 1 0 362 131
...
Это – список списков. Например, кэш с именем dc_objects в настоящий момент хранит 917 действительных элементов. Поиск по этому списку выполнялся 37 716 раз (GETS) из них 3200 раз он завершался неудачей (GETMISSES – эти случаи могли приводить к выполнению соответствующих рекурсивных инструкций SQL, чтобы скопировать некоторую информацию из словаря данных в кэш словаря). Кэш dc_objects хранит также 55 фиксированных объектов (FIXED).
Примечание. Как видите, для поиска информации, подсказывающей, как выполнять вашу инструкцию SQL, может потребоваться выполнить некоторые рекурсивные инструкции SQL. Но как первоначально заполняется кэш словаря – вне всяких сомнений, никакой код SQL не сможет быть выполнен, пока не будет выполнен некоторый код SQL. Ответ, как обычно, заключается в том, что Oracle «хитрит». Есть некоторый «начальный» код, «знающий» физическое местоположение первых нескольких объектов в базе данных и обладающий достаточным объемом информации, позволяющей оптимизатору использовать ее для получения дальнейшей информации. Эти «начальные» объекты отображаются в v$rowcache как фиксированные.
Если вам интересно узнать, что это за объекты, просмотрите содержимое файла $ORACLE_HOME/rdbms/admin/sql.bsq до строки с «//». Можно так-же посмотреть код SQL, создающий начальные (bootstrap) объекты в таблице sys.bootstrap$. Во время создания базы данных Oracle записывает эту информацию в базу, сохраняет физический адрес начала sys.bootstrap$ в заголовке блока первого файла и использует этот «черный ход» для чтения таблицы и получения адреса словаря данных в момент запуска. Увидеть этот адрес можно, если вывести дамп заголовка файла (oradebug dump file_hdrs 3) и отыскать в нем элемент root dba.
Обратите внимание, что строки делятся на две группы – PARENT и SUBORDINATE. Эти признаки указывают на способ сопоставления с информацией в кэше. Возьмем для примера cache# 8: он имеет родительский (PARENT) dc_objects и подчиненный (SUBORDINATE) dc_object_grants объекты. Эта информация говорит о том, что Oracle может сохранить (что вполне разумно) информацию о привилегиях для таблицы TableX (например) вместе с информацией о самой таблице TableX.
Как можно заключить из имени, данный конкретный кэш cache# хранит список всех объектов, известных экземпляру в настоящий момент. Грубо говоря, он хранит копии всех строк из dba_objects (точнее из таблицы obj$), которые были прочитаны в процессе интерпретации инструкций SQL и/или PL/SQL. В действительности список намного длиннее, чем показано здесь, потому что в него включены также несуществующие объекты. Я могу продемонстрировать это, выполнив следующую инструкцию SQL в моей личной схеме:
select count(*) from all_objects;
После выполнения запроса в кэше dc_objects появилось не менее трех элементов с именем all_objects. Один из них – определение представления, принадлежащий sys. Другой – синоним (synonym) , принадлежащий public. И третий – несуществующий, принадлежащий моей схеме. Этот последний элемент является элементом кэша словаря, отсутствующим в словаре данных, но он позволяет Oracle заметить, что когда я выполняю инструкцию, ссылающуюся на (неквалифицированное) имя all_objects, эта ссылка не указывает на объект в моей схеме. Если бы в кэше словаря этот элемент отсутствовал, Oracle пришлось бы постоянно проверять словарь данных, выполняя запрос к obj$, при обнаружении упоминания (неквалифицированного) имени all_objects. Присутствие в кэше таких несуществующих объектов – это еще один маленький аргумент в пользу применения полностью квалифицированных имен объектов. Имеются также аргументы против, но, прежде чем заботиться о таких мелочах, необходимо подумать о вещах более важных.
Стратегия, подобная той, что используется в словаре данных, применяется также в представлении dba_dependencies, когда создаются объекты, зависящие от общедоступных синонимов. Например:
SQL> create or replace view my_objects as select * from user_objects; View created SQL> select 2 referenced_owner, referenced_name, referenced_type 3 from 4 user_dependencies 5 where 6 name = ‘MY_OBJECTS’ 7 ; REFERENCED_OWNER REFERENCED_NAME REFERENCED_TYPE ------------------ ----------------- ----------------- PUBLIC USER_OBJECTS SYNONYM TEST_USER USER_OBJECTS NON-EXISTENT
Правильная интерпретация представления my_objects зависит от наличия в моей схеме действительного объекта user_objects, поэтому Oracle добавит в словарь данных элемент, отражающий этот факт. Если теперь я создам настоящий объект с именем user_objects, Oracle удалит зависимость от несуществующего объекта, определив, что он должен привести аннулированию определения представления my_objects.
Так как Oracle хранит список объектов (и ряд других списков) в памяти, возникает два вопроса: как Oracle осуществляет управление списком, и как обеспечивается высокая эффективность поиска в нем. В данном случае точно так же имеется коллекция защелок хэш-цепочек, хэш-цепочки и связанные списки.
Обнаружить присутствие хэш-блоков можно, переключив внимание с представления со сводной информацией (v$rowcache) на два подчиненных представления кэша строк – v$rowcache_parent и v$rowcache_subordinate. Оба они имеют столбец hash, содержащий значения в диапазоне от нуля до 65 535. Чтобы увидеть защелки хэш-цепочек, нужно лишь выполнить запрос к v$latch_children, как показано ниже (в данном случае запрос был выполнен в экземпляре 11.2.0.2):
SQL> select 2 name, count(*) 3 from 4 V$latch_children 5 where 6 name like ‘%row%cache%’ 7 group by 8 name 9 ; NAME COUNT(*) ------------------------------ ---------- row cache objects 51
Теперь, убедившись, что с кэшем словаря связано множество защелок, можно сделать еще шаг вперед. Итак, у нас имеется 51 защелка, но count(*) из v$rowcache (так же в 11.2.0.2) сообщает о 61 строке. Если проверить x$qrst (структуру, лежащую в основе v$rowcache), можно увидеть, что она содержит интересный столбец:
SQL> desc x$kqrst Name Null? Type ----------------------------------------- -------- ------------ ... KQRSTCLN NUMBER ...
Как оказывается, это число дочерних защелок (Child Latch Number, CLN) для части кэша строк, то есть, можно написать простой запрос, связывающий каждую часть кэша строк с защелкой и, например, сравнивающий число обращений к словарю с числом приобретений защелок:
select
dc.kqrstcid cache#,
dc.kqrsttxt parameter,
decode(dc.kqrsttyp,1,’PARENT’,’SUBORDINATE’) type,
decode(dc.kqrsttyp,2,kqrstsno,null) subordinate#,
dc.kqrstgrq gets,
dc.kqrstgmi misses,
dc.kqrstmrq modifications,
dc.kqrstmfl flushes,
dc.kqrstcln child_no,
la.gets,
la.misses,
la.immediate_gets
from
x$kqrst dc,
v$latch_children la
where
dc.inst_id = userenv(‘instance’)
and la.child# = dc.kqrstcln
and la.name = ‘row cache objects’
order by
1,2,3,4
;
К моему удивлению (я пока не могу объяснить причину) я обнаружил, что для каждого обращения к кэшу словаря операция приобретения защелки выполняется трижды. Я предполагал, что их будет две, и мне нужно какое-то время, чтобы понять, откуда взялась третья.
Структура
Установив, что своей структурой кэш словаря очень похож на библиотечный кэш и кэш буферов, я думаю имеет смысл нарисовать схему строения одной строки из v$rowcache и соответствующие элементы из v$rowcache_parent и v$rowcache_subordinate (рис. 1).

Рис. 1. Фрагмент кэша словаря
Эта схема опирается на следующие предположения.
- Каждая защелка охватывает один родительский тип и все его подчиненные типы. С другой стороны, структуры
x$kqrpdиx$kqrsdмогут быть хэш-блоками кэша строк для родительского и подчиненного типов, соответственно. Наличие этих структур предполагает, что родительские и подчиненные типы хранятся отдельно, даже при том, что каждая совокупность родительских и подчиненных кэшей охватывается единственной защелкой. - Каждая защелка (хотя это не отражено на схеме) охватывает 65 536 хэш-блоков, соответственно каждый хэш-блок наверняка связан с очень небольшим числом элементов. Возможно, между хэш-значением и хэш-блоками имеется еще один уровень, уменьшающий число блоков, приходящихся на одну защелку. Мы знаем, например, что существуют такие штуки, как очереди кэша строк (row cache enqueues, или блокировки), поэтому перед отдельными хэш-блоками, доступ к которым защищают защелки, вполне может находиться промежуточный уровень.
- Родительские элементы в хэш-блоках связаны между собой в двусвязные списки, аналогичным образом связаны родительские и подчиненные им элементы. Несмотря на то, что
x$kqrpdиx$kqrsdвыглядят так, как будто представляют хэш-блоки, они экспортируют только счетчики и размеры. Однако размеры соответствующих записей (которые можно вывести из столбцаaddrкаждого объекта) оказываются слишком велики для экспортируемой информации, а если вывести содержимое записи с помощьюoradebug peek(см. приложение), можно увидеть массу всякой всячины, напоминающей указатели.
Хотя я уже предположил, что каждый хэш-блок в кэше словаря скорее всего содержит очень небольшое число элементов, все же стоит сделать небольшую паузу и рассмотреть гистограммы. Собирая статистики по столбцам, мы имеем возможность собрать в гистограмму до 254 хэш-блоков (каждый из которых хранит, кроме всего прочего, 32-байтное значение endpoint_actual_value). Данные для гистограммы (dc_histogram_data) подчинены определениям гистограмм (dc_histogram_defs), откуда следует, что для хранения этих данных хэш-блок кэша словаря должен содержать 254 элемента. На самом деле я думаю, что Oracle конструирует единственный (возможно большой) элемент для данных гистограммы и затем передает его в кэш словаря, при этом сама гистограмма может занимать значительный объем памяти.
Желающие увидеть, какой объем памяти занимает кэш словаря, могут выполнить следующий запрос к v$sgastat:
SQL> select * from V$sgastat where name like ‘%KQR%’ order by name; POOL NAME BYTES ------------ -------------------------- ---------- shared pool KQR ENQ 82080 shared pool KQR L SO 65540 shared pool KQR M PO 1874488 shared pool KQR M SO 455312 shared pool KQR S PO 147288 shared pool KQR S SO 19456 shared pool KQR X PO 8016
Я думаю, что имена в результатах расшифровываются так:
- KQR обозначает кэш строк;
- ENQ, по всей видимости, обозначает очереди в кэше строк;
- X / L / M / S обозначают размер: очень большой (eXtra large) / большой (Large) / средний (Medium) / маленький (Small);
- PO/SO обозначают родительский объект (Parent Object) / подчиненный объект (Subordinate Object).
Если вам когда-нибудь доводилось видеть аварийное завершение сеанса с сообщением >>> WAITED TOO LONG FOR A ROW CACHE ENQUEUE LOCK! <<< (превышено время ожидания блокировки с очередью кэша строк), вы сразу подумаете, что имя KQR ENQ имеет некоторое отношение к очередям кэша строк. Но кроме пары событий (например, row cache lock) блокировки с очередью в кэше строк (row cache enqueues) почти нигде не упоминаются. Результаты, что приводятся выше, были получены в экземпляре 10.2.0.3, но когда я выполнил тот же запрос в экземпляре 11.2.0.2, в его результатах не обнаружилось элемента KQR ENQ – это может означать, что изменился код обработки кэша словаря или имя столбца со значением объема памяти, используемой для очередей в кэше строк.
Чтобы получить дополнительную информацию о распределении памяти, можно выполнить запросы к структурам x$kqrpd и x$kqrsd – первый из них вернет результаты, как показано в следующем (сокращенном) списке:
SQL> select * from x$kqrpd where kqrpdnmk != 0; ADDR INDX INST_ID KQRPDCID KQRPDOSZ KQRPDNMK KQRPDTSZ -------- ---------- ---------- ---------- ---------- ---------- ---------- 1FE45394 0 1 0 260 7 3584 1FE45474 2 1 2 208 406 103936 1FE454E4 3 1 3 216 68 17408 1FE456A4 7 1 7 284 9 4608 1FE45714 8 1 8 432 510 261120 1FE457F4 10 1 10 176 4 1024 ...
Сравнив эти результаты с содержимым v$rowcache, можно заметить, что x$kqrpd.kqrpdnmk соответствует v$rowcache.count. Путем несложных манипуляций легко выясняется, что kqrpdtsz – это произведение значения kqrpdnmk на «значение kqrpdosz, округленное до 256 (S), 512 (M) или 1024 (L)» (исключение составляют «очень большие» (X) значения для kqrpdosz, которые могут просто умножаться на 8 (или на 16, в 64-разрядной версии Oracle)). Суммируя значения kqrpdtsz с соблюдением правил округления, мы получим числа, близко (но не точно) соответствующие значениям в v$sgastat. Однако имейте в виду, что данные правила округления подразумевают непроизводительное расходование памяти – сделано это с целью уменьшить риск фрагментации памяти из-за частого добавления и удаления элементов кэша словаря. Странно, но если выполнить heapdump (уровня 2 будет достаточно – но не делайте этого на промышленной системе) кучи SGA (разделяемого пула), можно заметить, что памяти из кучи обычно выделяется на 28 байт больше тех значений, что перечислены выше, то есть: 284, 540 и 1052.
Функционирование кэша словаря (dictionary cache)
Увидев, что структура кэша словаря имеет определенное сходство с кэшем буферов, библиотечным кэшем и очередями, вы едва ли удивитесь, узнав, что Oracle использует кэш словаря подобно этим структурам.
Чтобы найти элемент в кэше словаря, необходимо защитить хэш-цепочку от изменений на время поиска (и наоборот, чтобы изменить цепочку, необходимо предотвратить возможность ее чтения другими сеансами). Так как кэш словаря разбит на дискретные секции по типам объектов, Oracle легко может вычислить нужную защелку по типу искомого объекта. Но с этого момента мне остается только догадываться о вовлеченных стратегиях.
Я вижу, что при работе с кэшем словаря выполняется три операции приобретения защелки, но я не могу найти разумное объяснение, зачем это необходимо. Возможно, например, что существует еще какая-то структура между защелкой и конечным хэш-блоком (в конце концов, 65 536 хэш блоков на защелку – это довольно много), из-за чего Oracle вынужден приобретать две защелки разделяемом режиме, чтобы закрепить и открепить эту структуру, и приобретать еще одну защелку на время чтения самой хэш-цепочки.
Независимо от конкретного порядка следования событий при чтении (или изменении) содержимого кэша словаря, действия с хэш-блоками и хэш-цепочками выполняются все по тому же шаблону, как и во многих других местах в Oracle, – цепочки должны защищаться от конфликтов между читающими и пишущими сеансами.
Убедиться в этом можно на простом примере (см. core_dc_activity_01.sql в загружаемом пакете примеров), выполняя большое число очень простых инструкций в простом цикле PL/SQL и наблюдая за происходящим в кэше словаря. Основа теста выглядит, как показано ниже:
execute snap_rowcache.start_snap
execute snap_latch_child.start_snap(‘row cache objects’)
declare
m_n number;
m_v varchar2(10);
begin
for i in 1..1000 loop
execute immediate
‘select n1 from t1 where id = ‘ || i
into m_n;
end loop;
end;
/
execute snap_latch_child.end_snap(‘row cache objects’)
execute snap_rowcache.end_snap
Две процедуры snap_xxx получают мгновенный снимок содержимого v$latch_children и v$rowcache, и сообщают об изменениях, вызванных кодом PL/SQL. Код PL/SQL конструирует 1000 немного отличающихся друг от друга запросов, добавляя значения в конец шаблона, каждый из которых обращается к единственной строке в таблице по первичному ключу. Ниже приводятся результаты, полученные в версии 10.2.0.3 (сценарий в загружаемом пакете примеров включает результаты, полученные в версии 11.2.0.2, где можно наблюдать интересные отличия):
---------------- Dictionary Cache ---------------- Parameter Usage Fixed Gets Misses --------- ----- ----- ---- ------ dc_segments 0 0 2,000 0 dc_tablespaces 0 0 2 0 dc_users 0 0 1,014 0 dc_objects 0 0 1,000 0 dc_global_oids 0 0 12 0 dc_object_ids 0 0 3,012 0 dc_histogram_defs 0 0 2,000 0 ----------------------------- row cache objects latch waits ----------------------------- Address Gets Misses ------- ---- ------ 1FE4846C 6,000 0 1FEC84D4 3 0 1FEC910C 3,021 0 1FF495DC 3,000 0 1FFC9644 18 0 1FFCAF14 9,018 0 1F8B4E48 6,000 0 Latches reported: 7
Полученные результаты, с учетом небольших отклонений, отражают связь между всеми частями кэша словаря и соответствующими защелками, и при каждом обращении к словарю соответствующие защелки приобретаются трижды.
При выполнении каждого запроса производится два обращения к dc_segments, потому что доступ к таблице происходит по ее индексу. Обращение к dc_users происходит один раз в каждом запросе – возможно с целью аутентификации. К dc_objects и dc_object_ids было произведено 4000 обращений, в соотношении 1000/3000, а не 2000/2000, как можно было бы ожидать; эта аномалия была скрыта в 11g в результате слияния кэшей dc_object_ids и dc_objects. Наконец, к dc_histogram_defs было произведено 2000 обращений – по одному для каждого столбца в каждом запросе; если бы выбиралось два столбца и два столбца использовались в предикате, было бы произведено 4000 обращений к кэшу dc_histogram_defs. (Если вы не можете определиться, что лучше – выбрать один столбец или все (select *) – вспомните о стоимости дополнительных обращений к dc_histogram_defs, это достаточно веский аргумент.)
Нетрудно понять, что выполнение множества легковесных инструкций SQL в высоконагруженной системе породит значительную активность вокруг защелок для доступа к объектам в кэше строк – таким, как определения столбцов – и может привести к появлению множества конфликтов при попытках приобретения защелок. Именно это обстоятельство порождает массу споров вокруг использования параметров-переменных в системах OLTP вместо встраивания литералов значений в строки SQL.
Стоит лишь немного изменить тест (см. core_dc_activity_02. sql) и использовать немного иной подход, и результаты резко меняются, как показано ниже:
execute immediate ‘select n1 from t1 where id = :n’ into m_n using i; --------------------------------- Dictionary Cache --------------------------------- Parameter Usage Fixed Gets Misses --------- ----- ----- ---- ------ dc_segments 0 0 2 0 dc_tablespaces 0 0 2 0 dc_users 0 0 15 0 dc_objects 0 0 1 0 dc_global_oids 0 0 12 0 dc_object_ids 0 0 15 0 dc_histogram_defs 0 0 2 0
Число обращений (и попыток приобретения защелок) упало почти до нуля. Падение оказалось настолько существенным, что «хаотический шум», производимый фоновой деятельностью базы данных, воспринимается как существенные отклонения результатов. Текст инструкции SQL изменился так, что он остается постоянным, но в нее включен параметр (:n) – который обычно называют переменной связывания (bind variable) – и добавлено предложение using, благодаря которому теперь в вызовы execute можно передавать разные значения.
CURSOR_SHARING
Исторически сложилось так, что многие приложения конструируют инструкции SQL путем конкатенации текстовых шаблонов с пользовательским вводом. Из-за возникающих при этом проблем – и еще больше проблем мы увидим, когда займемся исследованием библиотечного кэша – в Oracle 8i был введен параметр cursor_sharing, область применения которого была расширена в версии 9i.
Этот параметр можно установить в значение exact (по умолчанию), force или (в 9i) similar. Когда этот параметр установлен в значение force, оптимизатор копирует литералы из инструкции SQL в приватную память и замещает их автоматически генерируемыми переменными связывания с именами, такими как «SYS_B_99», перед оптимизацией инструкции. Это заставило бы 1000 разных инструкций в моем первом примере выглядеть совершенно одинаково, и позволило бы достичь производительности, сопоставимой с производительностью второго примера. (Между прочим, это также означает, что разделяемый пул не будет заполняться массой небольших фрагментов текста, которые никогда не используются повторно, а просто ждут, когда будут удалены при нехватке свободной памяти.)
Если присвоить параметру значение similar, в пул будут сохраняться все отличающиеся инструкции, но оптимизатор все еще сможет оптимизировать их, если (в соответствии с несколькими правилами) для разных значений будут созданы разные планы выполнения. Вот эти правила: если имеется предикат на основе диапазона, если имеется предикат на основе столбца с гистограммой или если имеется предикат на основе столбца, который является ключом секционирования (partition key) в секционированной таблице (partitioned table).
Комбинация гистограмм и значения similar в параметре cursor_sharing, часто приводит к проблемам конкуренции, исследованием которых мы займемся далее, в разделе, посвященном библиотечному кэшу. По этой причине в версии 11g данный параметр был объявлен не рекомендуемым, и взамен было предложено пользоваться динамически разделяемыми курсорами (adaptive cursor sharing). В настоящее время рекомендуется использовать только значения exact и force.
Чтобы понять, почему переменные связывания оказывают такое влияние на работу кэша словаря, необходимо познакомиться с дополнительными различиями между парсингом и вызовами парсера, а также с особенностями работы библиотечного кэша.