 Ответственность за восстановление, согласованное чтение и почти всё остальное – это действительно так!
Ответственность за восстановление, согласованное чтение и почти всё остальное – это действительно так!
Я часто предлагаю своим студентам назвать наиболее важные технологии Oracle и версии, в которых они появились. В ответ мне часто называют новейшие технологии, такие как секционирование по ссылке (ref partitioning), логические резервные базы данных (logical standby) и даже Exadata. Но, на мой взгляд, единственной важнейшей особенностью Oracle является вектор изменений (change vector) – механизм, появившийся еще в версии 6, который описывает изменения в блоках данных и является основой механизма повторений и отмены (redo и undo).
Эта технология обеспечивает безопасность данных, минимизирует конфликты между операциями чтения и записи, поддерживает восстановление экземпляров и носителей, а также все технологии резервирования, доступа к ретроспективным данным (flashback), захват изменений и потоки данных (streams). Поэтому данные технологии мы рассмотрим в первую очередь.
Но прежде мы рассмотрим несколько фрагментов блоков данных и файлов журналов. Это поможет вам чувствовать себя увереннее, когда мы подойдем к знакомству с упомянутыми технологиями. Не пугайтесь заранее – это всего лишь удобный способ исследования информации, хранимой в Oracle. Я не буду описывать все возможные параметры команды dump сейчас (тема отдельной статьи).
Изменение простых данных в БД Oracle
Одна из самых странных особенностей баз данных Oracle заключается в том, что запись данных осуществляется дважды. Одна копия записывается файлы, хранящие самую последнюю версию данных (обратите внимание, что самая свежая версия может храниться в памяти, в ожидании записи на диск); другая копия существует в виде набора инструкций – в файлах журнала повторений – сообщающих, как воссоздать содержимое файлов с данными, что называется «с нуля».
Примечание. Говоря о данных и блоках данных в контексте описания внутренних механизмов, следует помнить, что под словом «данные» обычно подразумеваются не только сами данные, но также индексы и метаданные, а иногда также данные для операции отмены.
Подход к изменению данных в базе Oracle
Выполняя команду на изменение элемента данных, Oracle не просто направляется в файл (или в память, если изменяемый элемент хранится в буфере), чтобы найти этот элемент и изменить его, а выполняет изменения в четыре этапа. Если отбросить ненужные детали, эти четыре этапа сводятся к следующему:
- Создается описание изменения элемента данных.
- Создается описание воссоздания первоначальных данных на случай, если это потребуется.
- Создается описание, как создать описание воссоздания первоначальных данных.
- Изменение элемента данных.
Замысловатый третий пункт показывает, насколько сложен механизм изменения. Однако, если заменить в этом списке некоторые термины, получится описание этапов изменения блоков данных:
- Создается вектор повторения изменений (redo change vector), описывающий изменения в блоке данных.
- Создается запись отмены (undo record) для вставки в блок отмены (undo block) в табличном пространстве отмены.
- Создается вектор повторения изменений, описывающий изменения в блоке отмены.
- Изменяется блок данных.
Точная последовательность этапов и дополнительных технических операций, связывающих их воедино, зависят от версии Oracle, природы транзакции, объема работы, выполненной в транзакции, состояния различных блоков в базе данных, в котором они находились до выполнения инструкции, является ли изменение первым в транзакции или нет, и так далее.
Пример изменения данных в СУБД Oracle
Я предлагаю начать с простейшего примера изменения данных, какой только можно увидеть при изменении единственной строки в середине транзакции OLTP, которая уже обновила множество разбросанных строк. Фактически, порядок выполнения шагов не совпадает с описанным в предыдущем разделе. В действительности шаги выполняются в порядке 3, 1, 2, 4, два вектора повторения изменений объединяются в единственную запись повторения изменений, которая копируется в журнал (буфер) повторения перед изменением блока отмены и блока данных (именно в таком порядке). То есть, немного более точная версия происходящего выглядит так:
- Создается вектор повторения изменений, описывающий, как вставить запись отмены (undo record) в блок отмены (undo block).
- Создается вектор повторения изменений для изменения блока данных.
- Векторы повторения изменений объединяются в запись повторения и записываются в буфер журнала.
- Запись отмены вставляется в блок отмены.
- Изменяется блок данных.
Ниже приводится небольшой пример, взятый из действующей системы Oracle 9.2.0.8 (последняя версия, в которой легко воспроизвести обобщенный пример работы механизма). Я собираюсь выполнить инструкцию обновления пяти строк, перепрыгивая взад и вперед между двумя блоками таблицы, и выводя различные порции информации в файл трассировки процесса до и после обновления. Мне пришлось немного усложнить операцию обновления, чтобы сделать пример максимально простым и избежать встреч с некоторыми «особыми случаями».
Примечание. Первое изменение в транзакции включает некоторые дополнительные шаги, и первое изменение, которое производит транзакция в каждом блоке, немного отличается от большинства «типичных» изменений. Эти особые случаи будут рассматриваться в главе 3.
Код запроса, который я написал, будет обновлять третью, четвертую и пятую строки в первом блоке таблицы, но между этими тремя обновлениями он будет изменять строку во втором блоке таблицы (см. core_demo_02.sql в библиотеке примеров, которую можно загрузить на сайте www.apress.com). Обновления будут изменять третий столбец – типа varchar2() – замещая строку xxxxxx (шесть символов «x» в нижнем регистре) строкой YYYYYYYYYY (десять символов «Y» в верхнем регистре).
Ниже приводится символический дамп пяти строк в блоке до и после обновления:
tab 0, row 4, @0x1d3f tl: 117 fb: --H-FL-- lb: 0x0 cc: 4 col 0: [ 2] c1 0a col 1: [ 2] c1 06 col 2: [ 6] 78 78 78 78 78 78 col 3: [100] 30 30 30 30 30 30 30 30 ... 30 30 30 30 30 (100 символов) tab 0, row 4, @0x2a7 tl: 121 fb: --H-FL-- lb: 0x2 cc: 4 col 0: [ 2] c1 0a col 1: [ 2] c1 06 col 2: [10] 59 59 59 59 59 59 59 59 59 59 col 3: [100] 30 30 30 30 30 30 30 30 ... 30 30 30 30 30 (100 символов)
Как видите, третий столбец (col 2:) в таблице изменился: строка символов с кодом 78 (x) заменила строка символов с кодом 59 (Y). Поскольку в результате обновления длина строки увеличилась, она была скопирована в свободное пространство в блоке, что объясняет, почему позиция начального байта @0x1d3f изменилась на @0x2a7. Однако, это все еще строка с порядковым номером 4 (пятая строка) в блоке; если проверить список указателей строк в блоке данных (каталог блока – row directory), можно убедиться, что пятая запись изменилась и теперь ссылается на строку с новым адресом.
Блок был выведен перед подтверждением изменений, именно поэтому байт блокировки (lock byte, lb:) изменил значение 0x0 на 0x2 – строка заблокирована транзакцией, идентифицируемой вторым слотом в списке заинтересованных транзакций (Interested Transaction List, ITL)..
Теперь рассмотрим разные векторы изменений. Во-первых, по символическому дампу из текущего файла журнала повторений можно исследовать вектор изменений, описывающий наши действия, произведенные с таблицей:
TYP:0 CLS: 1 AFN:11 DBA:0x02c0018a SCN:0x0000.03ee485a SEQ: 2 OP:11.5 KTB Redo op: 0x02 ver: 0x01 op: C uba: 0x0080009a.09d4.0f KDO Op code: URP row dependencies Disabled xtype: XA bdba: 0x02c0018a hdba: 0x02c00189 itli: 2 ispac: 0 maxfr: 4863 tabn: 0 slot: 4(0x4) flag: 0x2c lock: 2 ckix: 16 ncol: 4 nnew: 1 size: 4 col 2: [10] 59 59 59 59 59 59 59 59 59 59
Я оставил в листинге только наиболее важные фрагменты вектора изменений. В строке 5 (Op code:) видно, что была выполнена операция URP (update row piece – обновление части строки). Строка 6 сообщает адрес изменившегося блока (bdba:) и сегмента заголовка блока (hdba:).
В строке 7 видно, что транзакция, выполняющая это изменение, использует элемент 2 в списке ITL (itli:), подтверждая увиденное нами в дампе блока: она обновляет tabn: 0 slot: 4 (пятая строка в первой таблице; запомните, что блоки в кластере могут хранить данные из нескольких таблиц, поэтому каждый блок включает список идентификаторов таблиц, строки из которых имеются в блоке). Наконец, в последних двух строках видно, что строка в таблице имеет четыре столбца (ncol:), из которых изменился только один (nnew:), длина строки (size:) увеличилась на 4 байта, и в результате изменений столбец 2 получил новое значение YYYYYYYYYY.
Далее нам нужно посмотреть описание, определяющее порядок возврата к прежним данным. Оно хранится в виде записи отмены в соответствующем блоке отмены. Способы поиска требуемого блока отмены рассматриваются в главе 3. В следующем листинге приводится запись из символического дампа блока:
*----------------------------- * Rec #0xf slt: 0x1a objn: 45810(0x0000b2f2) objd: 45810 tblspc: 12(0x0000000c) * Layer: 11 (Row) opc: 1 rci 0x0e Undo type: Regular undo Last buffer split: No Temp Object: No Tablespace Undo: No rdba: 0x00000000 *----------------------------- KDO undo record: KTB Redo op: 0x02 ver: 0x01 op: C uba: 0x0080009a.09d4.0d KDO Op code: URP row dependencies Disabled xtype: XA bdba: 0x02c0018a hdba: 0x02c00189 itli: 2 ispac: 0 maxfr: 4863 tabn: 0 slot: 4(0x4) flag: 0x2c lock: 0 ckix: 16 ncol: 4 nnew: 1 size: -4 col 2: [ 6] 78 78 78 78 78 78
И снова я опущу подробности и просто отмечу, что наиболее важной частью этой записи отмены (для нас) являются последние пять строк, почти полностью повторяющие содержимое вектора изменений, за исключением того, что на этот раз описывается уменьшение размера строки на 4 байта, из-за того, что столбец 2 получает значение xxxxxx.
Но это одна запись отмены, записанная в блок отмены и хранящаяся в табличном пространстве отмены, в одном из файлов с данными. А я говорил выше, что Oracle хранит все и вся по две копии – одну в файлах с данными и одну в файлах журналов повторения. Так как некоторая информация попала в файл с данными (пусть и в табличное пространство отмены), нужно создать описание выполненной операции и записать его в файл журнала повторения. Для этого создается другой вектор повторения изменений:
TYP:0 CLS:36 AFN:2 DBA:0x0080009a SCN:0x0000.03ee485a SEQ: 4 OP:5.1 ktudb redo: siz: 92 spc: 6786 flg: 0x0022 seq: 0x09d4 rec: 0x0f xid: 0x000a.01a.0000255b ktubu redo: slt: 26 rci: 14 opc: 11.1 objn: 45810 objd: 45810 tsn: 12 Undo type: Regular undo Undo type: Last buffer split: No Tablespace Undo: No 0x00000000 KDO undo record: KTB Redo op: 0x02 ver: 0x01 op: C uba: 0x0080009a.09d4.0d KDO Op code: URP row dependencies Disabled xtype: XA bdba: 0x02c0018a hdba: 0x02c00189 itli: 2 ispac: 0 maxfr: 4863 tabn: 0 slot: 4(0x4) flag: 0x2c lock: 0 ckix: 16 ncol: 4 nnew: 1 size: -4 col 2: [ 6] 78 78 78 78 78 78
Нижняя половина вектора изменений удивительно похожа на запись отмены, что, впрочем, не удивительно – в конце концов, он описывает информацию, помещенную в блок отмены. Верхняя половина вектора изменений сообщает, к чему относится нижняя половина и включает некоторую информацию о заголовке блока. Наиболее важной деталью для нас является адрес блока с данными DBA: (Data Block Address) в строке 1, который указывает на блок 0x0080009a: зная, как Oracle конструирует номера блоков в шестнадцатеричном виде, вы сможете определить, что в данном случае имеется ввиду блок с номером 154 в файле с данными 2 (номер файла для табличного пространства отмены во вновь созданной базе данных).
Коротко о главном
Итак, что же мы узнали? Когда изменяется блок данных, Oracle вставляет запись отмены (undo record) в блок отмены (undo block), чтобы запомнить, как потом отменить это изменение. Для каждого изменения в блоках данных Oracle создает вектор повторения изменений (redo change vector), описывающий, как выполняется изменение. Векторы создаются до выполнения фактических изменений. Так уж сложилось, что вектор отмены изменений (undo change vector) создается раньше «обратного» ему вектора изменений, то есть, имеет место следующая последовательность событий (см. рис. 1 ниже):

- Создание вектора изменений для записи отмены (undo record).
- Создание вектора изменений для блока данных.
- Объединение векторов изменений и сохранение записи повторения (redo record) в журнал повторений (в буфер).
- Вставка записи отмены в блок отмены (undo block).
- Изменение блока данных.
Конечно, нет никаких оснований полагать, что я расположил первые два события в правильном порядке. Ничего из моих слов выше или из листингов не свидетельствует, что эти действия должны выполняться именно в таком порядке. Но есть одна маленькая деталь, которую я сейчас покажу и которая была опущена в листингах векторов изменений, отчасти потому, что в версиях 10g и выше кое-что изменилось, а отчасти потому, что описанное проще будет постичь, если сначала представить выполнение действий в неправильном порядке.
Примечание. Способ создания и объединения векторов изменений претерпел существенные изменения в версии Oracle Database 10g, но сами механизмы, лежащие в основе, все еще очень похожи на прежние. Кроме того, новые механизмы не используются в RAC, и даже в одиночный экземпляр
Oracle возвращается к использованию старого механизма, если транзакция оказывается слишком большой или если включено вспомогательное журналирование или резервирование базы данных. Новую стратегию мы рассмотрим далее в этой главе. Однако есть одна вещь, которая не изменилась, – векторы изменений генерируются перед применением изменений к данным и блокам отмены.
Выше я показал два вектора изменений, как две отдельные сущности. Если бы я показал полную картину передачи этих векторов в журнал повторений, вы увидели бы, как они объединяются в единую запись повторения (redo record):
REDO RECORD - Thread:1 RBA: 0x00036f.00000005.008c LEN: 0x00f8 VLD: 0x01 SCN: 0x0000.03ee485a SUBSCN: 1 03/13/2011 17:43:01 CHANGE #1 TYP:0 CLS:36 AFN:2 DBA:0x0080009a SCN:0x0000.03ee485a SEQ: 4 OP:5.1 ... CHANGE #2 TYP:0 CLS: 1 AFN:11 DBA:0x02c0018a SCN:0x0000.03ee485a SEQ: 2 OP:11.5 ...
Это типичный (хотя и не универсальный) шаблон записи соответствующей пары векторов изменений в файл журнала, когда вектор изменения для записи отмены предшествует вектору изменения для соответствующего повторения.
В предыдущей записи повторения обратите внимание на значение LEN: (в первой строке) – это длина записи: 0x00f8 = 248 байт. То есть, описание операции замены строки «xxxxxx» на строку «YYYYYYYYYY» в единственной строке таблицы занимает 248 байт в журнале. Похоже, что такая операция стоит весьма недешево: было сгенерировано два вектора повторения изменений и внесены изменения в два блока данных, и все это ради небольшого изменения, для которого требуется в четыре раза меньше шагов, чем было выполнено. Будем надеяться, что взамен мы получим немалые выгоды.
Подведение итогов
Прежде чем продолжить, подведем промежуточные итоги: всякий раз, когда предпринимается попытка изменить данные, Oracle создает соответствующую запись отмены (которая также сохраняется в файле с данными); одновременно в журнал повторений Oracle добавляет описание изменения данных и описание собственных изменений.
Возможно вы заметили: поскольку данные могут изменяться «на месте», в одной строке можно выполнить «бесконечное» (то есть, произвольно большое) число изменений, но совершенно очевидно, что нельзя создать бесконечное число записей отмены, не увеличивая файлы с данными для табличного пространства отмены, как и нельзя записать бесконечное число изменений в журнал повторений, не увеличивая эти файлы. Чтобы не усложнять обсуждение, мы пока отложим проблему бесконечных изменений и притворимся, что можно создавать столько записей повторения и отмены, сколько потребуется.
ACID
Хотя я и не предполагаю рассказывать о транзакциях в данной главе, все же считаю нужным упомянуть о требованиях ACID (см. таблицу ниже) к системе поддержки транзакций и рассказать о том, как реализация повторений и отмены в Oracle обеспечивает соответствие этим требованиям.
| Атомарность (Atomicity) | Изменения в транзакции должны быть невидимы снаружи до ее завершения. |
| Согласованность (Consistency) | В момент начала и в момент конца транзакции данные должны находиться в согласованном состоянии. |
| Изолированность (Isolation) | Внутри транзакции не должны быть доступны изменения, произведенные в другой, неподтвержденной транзакции. |
| Надежность (Durability) | Изменения, выполненные успешно завершённой транзакцией, должны сохраняться и восстанавливаться после сбоя системы. |
В следующем списке приводится более подробное описание каждого из требований.
- Атомарность (Atomicity): При внесении изменений в данные создаются записи отмены, описывающие порядок обращения этих изменений. Это означает, что когда мы находимся в середине транзакции и другой пользователь запросил уже измененные данные, для него могут быть задействованы записи отмены, чтобы вернуть старую версию данных и тем самым сделать изменения невидимыми до момента подтверждения транзакции. Атомарность гарантирует, что другой пользователь не увидит незавершенные изменения и увидит все сразу, когда мы закончим.
- Согласованность (Consistency): Это требование относится к ограничениям, определяющим допустимость состояния информации в базе данных. Можно также утверждать, что наличие записей отмены не позволяет другим пользователям видеть изменения, выполняемые нашим приложением внутри транзакции, и, соответственно, получать данные, временно находящиеся в недопустимом состоянии. То есть, они увидят данные либо в прежнем, либо в уже новом состоянии, без промежуточных переходов. (Внутренний код, разумеется, имеет доступ ко всем промежуточным состояниям – и может пользоваться этой возможностью для решения своих задач – но код конечного пользователя никогда не получит данные в несогласованном состоянии.)
- Изолированность (Isolation): Как уже говорилось, наличие записей отмены не позволяет другим пользователям видеть, как меняются данные до момента, когда мы решим, что работа выполнена и подтвердим транзакцию. На самом деле ситуация обстоит еще лучше: наличие записей отмены означает, что другим пользователям не нужно видеть эффект действия нашей транзакции в внутри их транзакций, даже если наша транзакция начинается и заканчивается между началом и
концом их транзакций. (В Oracle этот уровень изоляции поддерживается, но не используется по умолчанию; см. врезку «Уровни изоляции».) Конечно, можно столкнуться с запутанной ситуацией, когда два пользователя одновременно пытаются изменить одни и те же данные – идеальная изоляция невозможна в мире, где транзакции выполняются за конечный интервал времени. - Надежность (Durability): Это требование подчеркивает выгоды поддержки журнала повторений. Как бы вы гарантировали завершение транзакции в случае аварийного сбоя в системе? Очевидное решение: записывать изменения на диск либо сразу, по мере их выполнения, либо на последнем этапе, «завершающем» транзакцию. В отсутствие журнала повторений это означало бы необходимость записи на диск большого числа блоков данных по мере их изменения. Представьте, что мы выполняем вставку десяти записей в таблицу order_lines с тремя индексами. Это могло бы потребовать выполнить 31 операцию записи на диск, чтобы изменить 1 блок таблицы и 30 блоков индексов. Но в Oracle имеется механизм повторений. Вместо записи всего блока данных, подготавливаются небольшие описания изменений и в результате, когда потребуется сохранить результаты транзакции, 31 небольшое описание превращается в единственную операцию записи в конец файла журнала.
Уровни изоляции
Oracle поддерживает три уровня изоляции: read committed (чтение подтвержденных изменений, по умолчанию), read only (только для чтения) и serializable (упорядочиваемость). В качестве иллюстрации рассмотрим следующую ситуацию: имеется таблица t1, хранящая одну запись, и таблица t2 со структурой, идентичной структуре таблицы t1. Имеется два сеанса, в которых выполняются следующие действия в указанном порядке:
- Сеанс 1: select from t1;
- Сеанс 2: insert into t1 select * from t1;
- Сеанс 2: commit;
- Сеанс 1: select from t1;
- Сеанс 1: insert into t2 select * from t1;
Если предположить, что сеанс 1 выполняет операции с уровнем изоляции read committed (чтение подтвержденных изменений), он выберет одну строку в первой инструкции select, две строки во второй инструкции select и вставит две строки.
Если предположить, что сеанс 1 выполняет операции с уровнем изоляции read only (только для чтения), он выберет одну строку в первой инструкции select, одну строку во второй инструкции select и потерпит неудачу с ошибкой «ORA-01456: may not perform insert/delete/update operation inside a READ ONLY transaction» (ORA-01456: вставка/удаление/обновление данных невозможны внутри транзакции с уровнем изоляции READ ONLY.).
Если предположить, что сеанс 1 выполняет операции с уровнем изоляции serializable (упорядочиваемость), он выберет одну строку в первой инструкции select, одну строку во второй инструкции select и вставит одну строку.
Наличие механизмов отмены и повторения не только достаточно для реализации требований ACID, они также дают дополнительные преимущества производительности и надежности.
Причины увеличения производительности уже были обозначены в описании требования к надежности (durability). Например, представьте отчет, который выполняется несколько минут и при этом в системе имеются пользователи, обновляющие данные в то же самое время. В отсутствие механизма отмены пришлось бы выбирать между допустимостью ошибочных результатов и блокировкой всех, желающих изменить данные. Такой выбор часто приходится делать при использовании некоторых других баз данных. Но механизм отмены в Oracle обеспечивает непревзойденную степень параллелизма, потому что, как гласит реклама Oracle: «операции чтения не блокируют операции записи, а операции записи не блокируют операции чтения».
И еще о возможности восстановления после сбоев: имея полный список изменений, произведенных в базе данных, можно создать совершенно новую базу, просто применив каждое отдельно взятое описание изменений, и в результате воспроизвести полноценную копию оригинальной базы данных. Разумеется, на практике такое решение не используется (обычно); вместо этого регулярно создаются резервные копии файлов с данными, благодаря чему достаточно будет применить лишь малую часть записей в журнале повторений, чтобы получить актуальную копию базы данных.
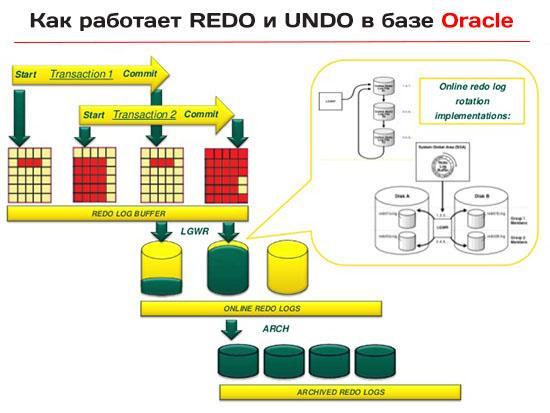
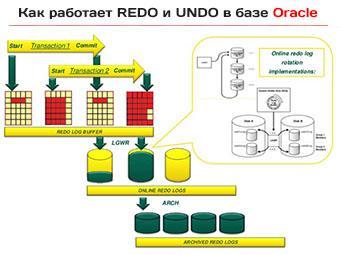
Простота механизма повторения
Алгоритм обработки записей повторения прост: непрерывно генерируемый поток записей повторения «перекачивается» в журнал повторений настолько быстро, насколько это возможно, через область разделяемой памяти, известной как буфер журнала повторений (redo log buffer). Очевидно, что в конечном счете буфер должен быть записан на диск и, для большей оперативности запись «непрерывного» потока производится в ограниченное множество оперативных файлов журнала повторений (online redo log files). Число оперативных файлов ограничено, поэтому они используются повторно, на манер циклического буфера.
Для защиты информации, хранящейся в оперативных файлах слишком долго, большинство систем настраивается на создание копии, или даже множества копий, каждого файла по мере заполнения, прежде чем Oracle сможет использовать его повторно: такие копии называют архивными файлами журнала повторений (archived redo log files). И еще о механизме повторения: по сути этот механизм действует по принципу «записал и забыл» – после попадания записи повторения (redo record) в журнал (буфер), мы (обычно) не ожидаем, что экземпляр повторно прочитает ее. На базовом уровне подход «записал и забыл» существенно упрощает механизм повторения.
Примечание. Несмотря на то, что оперативные файлы журнала повторений обычно предполагается использовать только для записи, в особых случаях все же бывает необходимо читать их. Например, если обнаруживается, что версия блока в памяти повреждена, предпринимается попытка восстановить ее из дискового файла. Кроме того, в последние годы были добавлены такие механизмы, как Log Miner, Streams и Change Data Capture, пользующиеся файлами журнала повторений, и некоторые из новейших механизмов для работы с резервными (Standby) базами данных превратились в инструменты реального времени и внедряются непосредственно в процесс, осуществляющий запись в оперативные файлы журнала. Подробнее об этих механизмах рассказывается в главе 6.
Есть, однако, одна сложность. В цепочке создания записей повторения имеется узкое место – момент, когда запись копируется в буфер журнала. В версиях Oracle ниже 10g вставка записей повторения (обычно состоящих из пар векторов изменений) в буфер журнала выполняется при каждом изменении пользовательских данных. Но в рамках одного сеанса за короткий промежуток времени может быть выполнено множество изменений, и таких сеансов, действующих параллельно, может быть множество, а буфер журнала, так нужный всем, всего один.
Относительно несложно создать механизм управления доступом к разделяемой памяти, и в Oracle уже имеется хорошо известная защелка redo allocation, защищающая буфер журнала повторений. Процесс, которому требуется получить некоторое пространство в буфере журнала, пытается приобрести защелку «redo allocation», после чего резервирует место в буфере для информации, которую нужно записать в буфер. Таким способом исключается вероятность записи данных в одну и ту же область внутри буфера несколькими процессами, действующими параллельно. Но, когда имеется большое число процессов, постоянно состязающихся за владение защелкой «redo allocation», это может привести к чрезмерным затратам ресурсов (обычно процессорного времени на обслуживание защелки) или даже к длительному бездействию процессов, из-за того, что они сами будут приостанавливаться на некоторое время после первой неудачной попытки приобрести защелку.
В старых версиях Oracle, разрабатывавшихся во времена, когда базы данных были менее нагружены, и число генерируемых записей повторения было намного меньше, стратегия «одно изменение = одна запись = одна операция резервирования памяти» была вполне оправданна для большинства систем. Но, с ростом систем, значительное увеличение числа параллельных операций резервирования памяти (особенно в системах OLTP) потребовало разработки более масштабируемой стратегии. Поэтому в версии 10g появился новый механизм, объединяющий приватный буфер повторения (private redo) с технологией In-Memory Undo обслуживания блоков отмены.
Как результат, процесс может пройти через всю транзакцию, сгенерировать все векторы изменений и сохранить их в паре частных (приватных) буферов журнала повторений. По завершении транзакции процесс копирует содержимое частного буфера в общедоступный буфер, для чего используется традиционный подход к работе с буфером журнала. Это означает, что процесс приобретает защелку «redo allocation» уже не для каждого изменения, а только один раз за период транзакции.
Примечание. Как одна из мер улучшения масштабируемости, в Oracle 9.2 была введена возможность иметь несколько буферов журнала повторений и параметр log_parallelism, но его существование всячески замалчивалось и предлагалось вообще забыть о нем, если только число процессоров в системе не равно или не превышает 16. В версии 10g имеется как минимум два общедоступных буфера журнала (потоков журналирования – redo threads), если число процессоров в системе больше одного.
Есть множество тонкостей (и ограничений), которые следует упомянуть, но, прежде чем перейти к их обсуждению, я хочу показать, как они влияют на работу экземпляра с точки зрения динамической производительности. Я взял сценарий core_demo_02.sql, убрал из него команды dump и заменил их вызовами получения моментальных снимков состояния v$latch и v$sesstat (см. core_demo_02b.sql в библиотеке загружаемых примеров). Кроме того, я изменил запрос SQL так, чтобы он обновлял не 5, а 50 строк и разница стала более очевидной. Следующие результаты были получены в версиях Oracle 9i и 10g соответственно. Сначала рассмотрим результаты, полученные в Oracle 9i:
Latch Gets Im_Gets ----- ---- ------- redo copy 0 51 redo allocation 53 0 Name Value ---- ----- redo entries 51 redo size 12,668
Обратите особое внимание, что в Oracle 9i защелки «redo copy» и «redo allocation» приобретались 51 раз каждая (две дополнительные попытки приобретения «redo allocation» обусловлены работой другого процесса) и была создана 51 запись повторения. Сравните эти цифры с результатами, полученными в Oracle 10g:
Latch Gets Im_Gets ----- ---- ------- redo copy 0 1 redo allocation 5 1 In memory undo latch 53 1 Name Value ---- ----- redo entries 1 redo size 12,048
В Oracle 10g наш сценарий приобрел защелку «redo copy» только один раз, и проявил чуть больше активности в отношении защелки «redo allocation». В листинге также видно, что была сгенерирована единственная запись повторения с размером, немного меньшим, чем общий размер записей повторения, созданных в версии Oracle 9i. Эти результаты были получены после подтверждения транзакции. Если тот же снимок сделать перед подтверждением, мы увидели бы нулевое число записей повторения (redo entries) и нулевой суммарный размер (redo size), число попыток приобретения защелки «In memory undo» уменьшилось бы до 51, а число попыток приобретения защелки «redo allocation» стало бы равным 1, вместо 5.
Итак, налицо заметное снижение активности и опасности конфликтов в критической точке. Из недостатков Oracle 10g можно отметить, что наш тесовый сценарий 53 раза приобретает новую защелку «In memory undo». Это выглядит как простое перемещение проблемы конкуренции из одного места в другое, но в действительности это не так – мы уделим этому внимание ниже.
В базе данных есть несколько мест, куда можно заглянуть, чтобы понять, что собственно произошло. Исследование $latch_children поможет понять, почему новая защелка не влечет за собой новой опасности конфликтов. Исследовав содержимое файла журнала, можно увидеть, на что похожа одна большая запись повторения. И можно отыскать пару динамических объектов (x$kcrfstrand и x$ktifp), которые помогут понять, как различные операции связаны между собой.
Расширенная инфраструктура основана на двух множествах структур. Одно множество (называется x$kcrfstrand и представляет приватный буфер повторений) предназначено для обслуживания «прямых» векторов изменений, а другое (называется x$ktifp и представляет пул механизма «in-memory undo») предназначено для
обслуживания векторов отмены изменений. Структура приватного буфера повторений хранит также информацию о традиционных, «общедоступных» буферах, поэтому не пугайтесь, если в ответ на запрос увидите два разных шаблона представления информации.
Число пулов в x$ktifp (в механизме «in-memory undo») зависит от размера массива, хранящего информацию о транзакции (v$transaction), который определяется параметром transactions (но может также выводиться на основе параметров sessions и processes). По умолчанию число пулов определяется, как transactions / 10 и каждый пул защищается собственной защелкой «In memory undo».
Каждому элементу в x$ktifp соответствует элемент в приватном буфере x$kcrfstrand, и, как уже упоминалось выше, несколько дополнительных традиционных, «общедоступных» буферов журналирования (потоков журналирования). Число таких буферов определяется значением параметра cpu_count, как результат выражения ceil(1 + cpu_count / 16). Каждый элемент в x$kcrfstrand защищен собственной защелкой «redo allocation», а каждый общедоступный поток журналирования дополнительно защищен защелкой «redo copy latch», по одной на процессор.
А теперь вернемся к первоначальному тесту, обновляющему пять строк и два блока в таблице. Oracle все еще будет выполнять действия и обходить строки и кэшированные блоки в том же порядке, только вместо попарной упаковки векторов повторения изменений, записи их в буфер журнала повторений и изменения блоков, будут выполняться следующие действия:
- Запуск транзакции приобретением пары соответствующих приватных структур в памяти, одной из x$ktifp и одной из x$kcrfstrand.
- Каждый блок, который будет затронут изменениями, отмечается как «имеющий приватный буфер повторения» (при этом сам блок пока не изменяется).
- Запись каждого вектора отмены изменений в выбранный пул механизма «in-memory undo».
- Запись каждого вектора повторения изменений в выбранный приватный пул повторения.
- Завершение транзакции объединением двух структур в единую запись повторения изменений.
- Копирование записи в журнал повторений и применение изменений к блокам.
Если заглянуть в структуры (см. core_imu_01.sql в загружаемых примерах) непосредственно перед подтверждением транзакции, можно увидеть следующее:
INDX UNDO_SIZE UNDO_USAGE REDO_SIZE REDO_USAGE
----- ---------- ---------- ---------- ----------
0 64000 4352 62976 3920
Здесь видно, что область приватной памяти для сеанса позволяет хранить примерно 64 Кбайта информации об изменениях, и примерно столько же – с описанием, как «отменить» изменения. В 64-разрядной системе эти значения будут близки к 128 Кбайтам. Для обновления пяти строк потребовалось примерно 4 Кбайта памяти в каждой из областей.
Если теперь, после подтверждения изменений, вывести содержимое файла журнала повторений, мы получим единственную запись (в следующем листинге я оставил только самое необходимое):
REDO RECORD - Thread:1 RBA: 0x0000d2.00000002.0010 LEN: 0x0594 VLD: 0x0d SCN: 0x0000.040026ae SUBSCN: 1 04/06/2011 04:46:06 CHANGE #1 TYP:0 CLS: 1 AFN:5 DBA:0x0142298a OBJ:76887 SCN:0x0000.04002690 SEQ: 2 OP:11.5 CHANGE #2 TYP:0 CLS:23 AFN:2 DBA:0x00800039 OBJ:4294967295 SCN:0x0000.0400267e SEQ: 1 OP:5.2 CHANGE #3 TYP:0 CLS: 1 AFN:5 DBA:0x0142298b OBJ:76887 SCN:0x0000.04002690 SEQ: 2 OP:11.5 CHANGE #4 TYP:0 CLS: 1 AFN:5 DBA:0x0142298a OBJ:76887 SCN:0x0000.040026ae SEQ: 1 OP:11.5 CHANGE #5 TYP:0 CLS: 1 AFN:5 DBA:0x0142298b OBJ:76887 SCN:0x0000.040026ae SEQ: 1 OP:11.5 CHANGE #6 TYP:0 CLS: 1 AFN:5 DBA:0x0142298a OBJ:76887 SCN:0x0000.040026ae SEQ: 2 OP:11.5 CHANGE #7 TYP:0 CLS:23 AFN:2 DBA:0x00800039 OBJ:4294967295 SCN:0x0000.040026ae SEQ: 1 OP:5.4 CHANGE #8 TYP:0 CLS:24 AFN:2 DBA:0x00804a9b OBJ:4294967295 SCN:0x0000.0400267d SEQ: 2 OP:5.1 CHANGE #9 TYP:0 CLS:24 AFN:2 DBA:0x00804a9b OBJ:4294967295 SCN:0x0000.040026ae SEQ: 1 OP:5.1 CHANGE #10 TYP:0 CLS:24 AFN:2 DBA:0x00804a9b OBJ:4294967295 SCN:0x0000.040026ae SEQ: 2 OP:5.1 CHANGE #11 TYP:0 CLS:24 AFN:2 DBA:0x00804a9b OBJ:4294967295 SCN:0x0000.040026ae SEQ: 3 OP:5.1 CHANGE #12 TYP:0 CLS:24 AFN:2 DBA:0x00804a9b OBJ:4294967295 SCN:0x0000.040026ae SEQ: 4 OP:5.1
Обратите внимание на длину записи отмены (LEN:), равную 0x594 = 1428, совпадающую со значением размера записи повторения, которое я увидел, когда выполнял данный тест. Это значительно меньше суммы 4352 и 3920 байтов, использованных под структуры в памяти, из чего можно заключить, что дополнительная израсходованная память – это накладные расходы механизмов приватных буферов повторения и отмены.
Обратите внимание на заголовки 12 отдельных векторов изменений, и в особенности – на код операции OP:. У нас имеется пять векторов с кодом 11.5, которые сопровождаются пятью векторами с кодом 5.1. Это – пять векторов, описывающих изменения, и соответствующие им пять векторов отмены изменений. Вектор с номером #2 (с кодом 5.2) – это начало транзакции, а вектор с номером #7 (с кодом 5.4) – это, так называемая, запись подтверждения (commit record), то есть конец транзакции. Более подробно эти векторы будут рассматриваться в главе 3, тем не менее, важно отметить, что в отличие от большинства векторов изменений, которые применяются к блокам данных только в момент подтверждения транзакции, вектор начала транзакции считается особым случаем и применяется к заголовку undo-сегмента блока в момент начала транзакции.
Итак, в Oracle имеется механизм, снижающий число операций выделения памяти и копирования информации в (общедоступный) буфер журнала повторений, благодаря которому увеличивается степень параллелизма... до определенной степени. Если вы подумали, что за эти выгоды придется заплатить чем-то другим, то оказались совершенно правы.
Ранее было показано, что каждое изменение влечет необходимость приобретения защелки «In memory undo». Означает ли это, что мы просто перенесли опасность конкуренции за защелку из одного места в другое, вместо того, чтобы избавиться от нее? И да, и нет. Теперь требуется приобретать единственную защелку («In memory undo») вместо двух («redo allocation» и «redo copy»), то есть, количество операций с защелками уменьшилось ровно наполовину, но, что гораздо важнее, для каждой защелки «In memory undo» имеется множество дочерних защелок, по одной для каждого пула отмены (in-memory undo pool). До появления нового механизма большинство систем работало с единственной защелкой «redo allocation», поэтому, несмотря на то, что защелка «In memory undo» используется столько же раз, что и защелка «redo allocation», операции с ней разбросаны по множеству дочерних защелок.
Также важно отметить, что новый механизм имеет два типа защелок «redo allocation»: один тип служит для работы с приватными потоками журналирования, а другой – для работы с общедоступными потоками журналирования, при этом каждый поток защищается собственной защелкой. Это объясняет увеличенное потребление памяти в статистике использования защелки «redo allocation», которую мы видели выше: наш сеанс использует приватную защелку «redo allocation» для доступа к приватному потоку журналирования, затем, на этапе подтверждения, он должен приобрести общедоступную защелку «redo allocation», после чего механизм записи в журнал (как мы увидим в главе 6) приобретает общедоступные защелки «redo allocation» (в моей тестовой системе имелось два общедоступных потока журналирования), чтобы выполнить запись буфера в файл журнала.
В целом, когда количество операций с защелками уменьшается, и эти операции распределяются по более широкому кругу защелок, это хорошо. Но в многопользовательской системе всегда имеются другие аспекты, которые также следует учитывать, – при использовании прежнего механизма, объем информации для копирования в буфер журнала повторений и применения к блокам данных в любом единственном экземпляре был очень невелик; при использовании нового
механизма, объем информации для копирования и применения существенно вырос, а это означает увеличение времени, необходимого на применение изменений к блокам данных, и увеличение вероятности блокировки доступа к этим блокам на время выполнения изменений. Это может быть одной из причин ограничения размеров приватных потоков журналирования.
Кроме того, при использовании старого механизма другой сеанс, читающий измененный блок, сразу же увидел бы изменения. С новым механизмом другой сеанс увидит только, что для блока имеется некоторый приватный буфер повторения, поэтому теперь второй сеанс должен разыскать этот буфер и применить изменения к блоку (если необходимо), а затем решать, что делать дальше. (Подумайте о проблеме ссылочной целостности, если вам сложно понять вот так сразу, что получится, когда другой сеанс, например, удалит нужный вам первичный ключ.) Выполнение пойдет по более сложному и извилистому пути, но, даже если для обеспечения согласованного чтения потребуется больше вычислительных ресурсов, чем раньше, очевидно, что лучше пожертвовать небольшим увеличением потребления процессорного времени и тем самым избежать конкуренции между несколькими сеансами в одной точке.
Примечание. Существует один важный принцип оптимизации, про который часто забывают. Иногда для всех лучше сделать поработать немного больше в разных местах, чем постоянно конфликтовать в одном месте – конфликты влекут за собой напрасное потребление ресурсов.
Я не знаю, сколько разных событий существует, которые могут вынуждать сеанс конструировать новые версии блоков на основе приватных буферов повторения и отмены, но я знаю, что есть такие события, которые могут заставить сеанс отказаться от новой стратегии до подтверждения.
Наиболее очевидной является ситуация, когда Oracle отказывается от использования нового механизма в случае переполнения приватного потока журналирования или пула механизма «In-memory undo». Как было показано выше, размеры приватных областей имеют размер, что-то около 64 Кбайт (128 Кбайт в 64-разрядной версии Oracle). Когда область памяти оказывается заполненной, Oracle создает единственную запись повторения, копирует ее в общедоступный поток журналирования и затем продолжает использовать его старым способом.
Но есть другие события, заставляющие этот переключатель срабатывать преждевременно. Например, запрос SQL может вызывать рекурсивную инструкцию. Для быстрой проверки возможных причин и количества раз их появления можно попробовать подключиться к базе данных как SYS и выполнить следующий код SQL (результаты были получены в версии 10.2.0.3):
select ktiffcat, ktiffflc from x$ktiff; KTIFFCAT KTIFFFLC ---------------------------------------- ---------- Undo pool overflow flushes 0 Stack cv flushes 21 Multi-block undo flushes 0 Max. chgs flushes 9 NTP flushes 0 Contention flushes 18 Redo pool overflow flushes 0 Logfile space flushes 0 Multiple persistent buffer flushes 0 Bind time flushes 0 Rollback flushes 6 Commit flushes 13628 Recursive txn flushes 2 Redo only CR flushes 0 Ditributed txn flushes 0 Set txn use rbs flushes 0 Bitmap state change flushes 26 Presumed commit violation 0 18 rows selected.
К сожалению, несмотря на наличие различных статистик в представлении v$sysstat, имеющих отношение к механизму IMU (например, IMU flushes), они плохо коррелируют с картиной из структуры x$ – хотя, если игнорировать пару значений, можно найти немало близких совпадений.
Сложность механизма отмены
Механизм отмены (undo) имеет более сложную организацию, чем механизм повторения Oracle (redo). Самое важное, что благодаря этому механизму практически любой процесс может обратиться к любой записи отмены и «скрыть» элемент данных, который, как предполагается, он не должен видеть. Для большей эффективности Oracle хранит записи отмены внутри базы данных, в специальном табличном пространстве с названием «undo», а реализация поддерживает различные указатели на записи отмены, чтобы процессы могли без труда находить нужные. Преимущество хранения записей отмены внутри базы данных, в «обычных» файлах с данными, заключается в возможности использования для обработки блоков отмены тех же механизмов буферизации, записи и восстановления, что и для любых других блоков данных – управление блоками отмены осуществляет тот же код, который управляет блоками всех остальных типов.
Существует три причины, по которым процессу может потребоваться читать записи отмены, и, соответственно, три способа пересечения табличного пространства отмены с помощью цепочек указателей. Мне хотелось бы дать несколько общих комментариев о двух наиболее типичных способах прямо сейчас.
Примечание. Связанные списки записей отмены используются для согласованного чтения, отката изменений и получения SCN подтверждений, которые были «потеряны» из-за отложенной очистки блока. Исследование третьей темы мы до следующих статей.
Согласованное чтение
Чаще всего записи отмены используются для поддержки согласованного чтения (read consistency), о чем уже упоминалось выше. Наличие записей отмены позволяет сеансу получать более старые версии данных, когда по тем или иным причинам он не должен видеть новую версию.
Требование согласованности чтения означает, что блок должен содержать указатель на записи отмены, описывающие, как скрыть изменения в блоке. Но, число изменений, которые должны быть скрыты, может оказаться настолько большим, что в единственном блоке не хватит места для всех указателей. Поэтому Oracle ограничивает число указателей в каждом блоке (по одному для каждой конкурирующей транзакции, воздействующей на блок), которые хранятся в элементах списка ITL. Когда процесс создает запись отмены, он (обычно) затирает один из имеющихся указателей, сохраняя предыдущее значение как часть записи отмены.
Рассмотрим еще раз запись отмены, демонстрировавшуюся выше, полученную после обновления трех строк в одном блоке:
*----------------------------- * Rec #0xf slt: 0x1a objn: 45810(0x0000b2f2) objd: 45810 tblspc: 12(0x0000000c) * Layer: 11 (Row) opc: 1 rci 0x0e Undo type: Regular undo Last buffer split: No Temp Object: No Tablespace Undo: No rdba: 0x00000000 *----------------------------- KDO undo record: KTB Redo op: 0x02 ver: 0x01 op: C uba: 0x0080009a.09d4.0d KDO Op code: URP row dependencies Disabled xtype: XA bdba: 0x02c0018a hdba: 0x02c00189 itli: 2 ispac: 0 maxfr: 4863 tabn: 0 slot: 4(0x4) flag: 0x2c lock: 0 ckix: 16 ncol: 4 nnew: 1 size: -4 col 2: [ 6] 78 78 78 78 78 78
На эту запись отмены указывает блок таблицы с пятой обновленной строкой, и мы можем видеть во второй строке дампа, что это – запись с номером 0xf в блоке отмены. Семь последних строк в дампе показывают, что запись имеет код op: C, то есть является продолжением обновлений, начатых ранее в этой транзакции. По этому коду Oracle определяет, что остаток строки uba: 0x0080009a.09d4.0d является частью информации, которую можно использовать для воссоздания более старой версии блока: содержащей строку «xxxxxx» (последовательность числовых кодов 78) в столбце 2 строки 4, и значение 0x0080009a.09d4.0d в элементе 2 списка ITL.
Разумеется, как только будут выполнены все шаги по восстановлению более старой версии блока, реализация Oracle обнаружит, что ушла недостаточно далеко, и что в элементе 2 списка ITL 2 имеется указатель на следующую запись отмены, которую также нужно применить. Таким способом процесс может последовательно, шаг за шагом, вернуться назад во времени; указатель в каждом элементе ITL сообщает реализации Oracle, где находится следующая запись отмены для применения, и каждая запись включает информацию не только о данных, хранившихся в прошлом, но и элемент списка ITL для возврата назад во времени.
Откат
Второй важнейшей причиной использования записей отмены является откат изменений (rolling back changes) – либо явный откат (откат к точке сохранения), либо неявный откат из-за неудачи в транзакции, который в Oracle выполняется автоматически, на уровне инструкций.
Согласованное чтение затрагивает единственный блок и связано с поиском связанного списка всех записей отмены для этого блока. Для отката нужна вся история транзакции, то есть связанный список указателей на все записи отмены для транзакции, расположенных в правильном (в данном случае – в обратном) порядке.
Примечание. Вот простой пример, показывающий, почему записи отмены должны располагаться в «обратном» порядке. Представьте, что строка обновляется дважды: один и тот же столбец меняет свое значение сначала с A на B, а затем с B на C, в результате чего получается две записи отмены. Если впоследствии потребуется обратить изменения, сначала нужно будет заменить значение C на B, и только потом можно будет применить запись отмены, которая говорит, что «значение B следует изменить на A». Иными словами, вторая запись отмены должна быть применена раньше первой.
Взгляните еще раз на пример записи отмены и обратите внимание на признаки связанного списка: элемент rci 0x0e в строке 3 дампа. Он сообщает, что запись отмены, созданная непосредственно перед этой, имеет номер 14 (0x0e) в том же блоке отмены. Разумеется, предыдущая запись отмены вполне может находиться в другом блоке отмены, но это имеет место, только если текущая запись отмены является первой в блоке, и тогда элемент rci будет иметь нулевое значение, а элемент rdba: в четвертой строке будет содержать адрес блока с предыдущей записью отмены. Если возникнет необходимость вернуться назад к предыдущему блоку, тогда искомой обычно является последняя запись в блоке, хотя с технической точки зрения искомой является запись, на которую ссылается элемент irb:. Однако, единственным случаем, когда элемент irb: может указывать не на последнюю запись, является откат к точке сохранения.
Согласованное чтение и откат имеют важные отличия. При согласованном чтении создается копия блока данных в памяти, к которой применяются записи отмены и которую можно просто отбросить, когда надобность в ней отпадет. В случае же отката, записи отмены применяются к фактическому блоку данных. Это имеет три важных следствия:
- блок данных является текущим, и именно эта версия в конечном счете будет записана на диск;
- так как блок является текущим, для него будет создана запись повторения, описывающая изменения (даже при том, что «изменения возвращают блок в исходное состояние»);
- так как в Oracle имеются механизмы восстановления после аварий, устраняющие последствия максимально эффективно, насколько это вообще возможно, запись отмены должна быть отмечена как «примененная», что приводит к созданию дополнительной записи повторения.
Если запись отмены уже была использована для выполнения отката, строка 4 дампа будет иметь следующий вид:
Undo type: Regular undo User Undo Applied Last buffer split: No
Флаг User Undo Applied в дампе блока будет указывать размер 1 байт вместо 17-символьной строки.
В процессе отката выполняется масса операций, на выполнение которых может потребоваться столько же времени, как и на оригинальную транзакцию, и при этом будет сгенерирован сопоставимый объем записей повторения. Но вы должны помнить, что откат является операцией, изменяющей блоки данных, поэтому такие блоки вновь извлекаются из файлов, изменяются и сохраняются, при этом создаются и сохраняются записи повторения, описывающие изменения в блоках. Кроме того, при выполнении обширных и продолжительных транзакций может получиться так, что некоторые измененные блоки будут записаны на диск и вытолкнуты из кэша – то есть придется прочитать с диска, прежде чем выполнить откат!
Примечание. Некоторые системы используют таблицы Oracle для хранения «временных» или «оперативных» данных. При работе с такими таблицами часто используется такая стратегия: данные добавляются без подтверждения, чтобы согласованное чтение было возможно только в рамках сеанса, после чего они «удаляются» операцией отката. Эта стратегия имеет множество недостатков, одним из которых является потенциально высокая цена отката. Возможность уменьшить накладные расходы за счет отказа от отката является одной из важнейших причин, делающих привлекательными глобальные временные таблицы.
Разумеется, откат влечет за собой и другие накладные расходы. Когда сеанс создает записи отмены, он приобретает, удерживает и заполняет блок отмены сразу; а когда выполняет откат, извлекает записи отмены из блока по одной, освобождая и приобретая вновь блок для каждой записи. То есть, при выполнении отката происходит больше обращений к буферу, чем при выполнении транзакции. Кроме того, каждый раз, извлекая запись отмены, Oracle проверяет присутствие целевого табличного пространства в памяти (иначе Oracle передаст запись в сохраненный сегмент отката в табличном пространстве SYSTEM); это проявляется как обращение к кэшу словаря данных (в частности, к кэшу dc_tablespaces).
Предварительное описание процедуры отката можно завершить упоминанием еще одной неприятной особенности. Когда сеанс запускает команду отката, она завершается подтверждением.
Итоги
Механизм повторения (redo) реализует довольно простую концепцию: каждое изменение в блоке данных описывается вектором повторения изменения (redo change vector), эти векторы (практически) немедленно записываются в буфер журнала повторений и затем, рано или поздно, в файл журнала повторений.
Кроме того, при изменении данных (включая индексы и метаданные) создаются записи отмены (undo records) в табличном пространстве отмены, описывающие порядок обращения (отмены) этих изменений. Так как табличное пространство отмены представлено всего лишь еще одним набором файлов, создаются дополнительные векторы изменений, описывающие записи отмены.
В ранних версиях Oracle векторы изменений обычно объединялись в пары (один описывал изменение, а второй – запись отмены), чтобы получить единственную запись повторения (redo record), которая затем сохранялась (сначала) в буфер журнала повторений.
В последних версиях Oracle этап записи векторов изменений в буфер журнала стал оцениваться как узкое место в системах OLTP (обработки транзакций в реальном масштабе времени). В результате был создан новый механизм, позволяющий сеансам аккумулировать все изменения в транзакции в «приватном» буфере и затем создавать одну большую запись повторения.
Новый механизм имеет строгие ограничения, при нарушении которых происходит выталкивание векторов изменений в буфер журнала и переход к использованию старого механизма. Кроме того, имеется множество событий, которые могут вызвать такой переход преждевременно.
В отличие от механизма повторений, который действует по принципу «записал и забыл», механизм отмены может часто перечитывать свои записи в процессе работы базы данных, поэтому записи отмены должны быть связаны несколькими разными способами, чтобы обеспечить максимально высокую эффективность их использования. Для согласованного чтения (read consistency) требуется, чтобы записи были объединены в цепочки по блокам; тогда как для отката требуется, чтобы они объединялись по транзакциям. (Существует и третий вид цепочек, о котором я расскажу в следующих статьях блога).


