 В предыдущей моей заметке в блоге мы видели, как используется механизм защелок для защиты памяти на время поиска и, возможно, изменения элементов списков, но я отмечал, что защелки желательно освобождать как можно быстрее. Это означает, что для выполнения продолжительных операций с найденным элементом списка, следует использовать другие механизмы защиты памяти, чтобы освободить защелку. В этом нам помогут блокировки (и закрепления) библиотечного кэша.
В предыдущей моей заметке в блоге мы видели, как используется механизм защелок для защиты памяти на время поиска и, возможно, изменения элементов списков, но я отмечал, что защелки желательно освобождать как можно быстрее. Это означает, что для выполнения продолжительных операций с найденным элементом списка, следует использовать другие механизмы защиты памяти, чтобы освободить защелку. В этом нам помогут блокировки (и закрепления) библиотечного кэша.
Однако, прежде чем приступить к знакомству с блокировками в библиотечном кэше, поговорим о наиболее известном и заметном способе получения информации о блокировках – представлении v$lock, которое, вообще говоря, является представлением структуры x$ksqrs (ресурсы с блокировками) в соединении (union) со структурой x$ksqeq (блокировки с очередями) и некоторыми другими структурами.
Примечание
Инфраструктура
В Oracle имеется множество разных ресурсов – таблицы, файлы, табличные пространства, подчиненные параллельные процессы (parallel execution slaves), потоки журналирования (redo threads) и многие другие – и множество разных причин защитить эти ресурсы на продолжительное время (перефразируя изречение бывшего премьер-министра Соединенного Королевства Гарольда Вильсона (Harold Wilson): «а 7 миллисекунд в Oracle – срок немалый»).
Чтобы обеспечить единообразие обработки разнотипных ресурсов, в Oracle имеется массив в SGA (доступен как x$ksqrs и v$resource, с размером, определяемым скрытым параметром _enqueue_resources), каждый элемент которого можно использовать для представления ресурса. Важнейшими столбцами в этом массиве являются:
Name Null? Type ----------------- -------- ------------ KSQRSIDT VARCHAR2(2) KSQRSID1 NUMBER KSQRSID2 NUMBER
Возможно вы увидите в этих названиях имена type, id1 и id2, которые появляются в представлении v$lock. Чтобы использовать элемент массива для представления некоторого ресурса, сеанс должен просто заполнить его столбцы; например:
- (
‘PS’, 1, 4) представляет подчиненный параллельный процесс (parallel execution slave)P004в экземпляре 1. - (‘
TM’, 80942, 0) представляет таблицу сobject_id, имеющим значение 80 942. - (
‘TX’, 65543, 11546) представляет транзакцию, использующую слот 7 (mod(65543,65536)) в undo-сегменте 1 (trunc(65543/65536)) в 11 546-й раз.
Получив внутренний объект, представляющий некоторый ресурс, можно начинать подключать к нему разные признаки, чтобы показать, какие сеансы желают использовать его и какие ограничения они хотели бы наложить. Существует несколько массивов структур, которые Oracle использует с этой целью. Чаще других используется x$ksqeq (обобщенные блокировки с очередью), x$ktadm (блокировки таблиц/DML) и x$ktcxb (транзакции). В числе прочих можно назвать x$kdnssf, x$ktatrfil, x$ktatrfsl, x$ktatl, x$ktstusc, x$ktstusg и x$ktstuss. Элементы этих массивов имеют общее ядро, кроме пары столбцов в x$ktcxb, и придерживаются общего соглашения об именовании. Этим столбцам присваиваются другие при экспортировании посредством v$lock, но в исходных структурах x$ они имеют следующие имена:
Name Null? Type ----------------- -------- ------ ADDR RAW(4) -- ktcxbxba в x$ktcxb KSQLKADR RAW(4) -- ktcxblkp в x$ktcxb KSQLKMOD NUMBER KSQLKREQ NUMBER KSQLKCTIM NUMBER KSQLKLBLK NUMBER
Последние четыре столбца опознаются достаточно просто – это столбцы lmode, request, ctime и block в представлении v$lock. Некоторые структуры также имеют столбец ksqlkses, который представляет адрес блокировки сеанса, доступный косвенно через sid в представлении v$lock, а также столбец x$ksqlres, который представляет адрес блокируемого ресурса, доступного косвенно через type, id1 и id2.
Основная идея очень проста: если требуется защитить ресурс, необходимо получить строку из x$ksqrs, пометить ее идентификатором ресурса и затем получить строку из x$ksqeq (или другой подобной структуры), установить режим блокировки и связать ее со строкой из x$ksqrs. При этом, разумеется, необходимо позаботиться о множестве деталей:
- Как узнать (быстро и эффективно), не пометил ли какой-то другой процесс строку из
x$ksqrsидентификатором того же ресурса, чтобы не создать дубликат блокировки? - Если какой-то другой процесс уже пометил строку в
x$ksqrsидентификатором ресурса, будет ли вам позволено пометить другую строку вx$ksqeqтем же ресурсом? (Что если уже установленный режим блокировки (lmode) запрещает доступ к ресурсу?) - Если будет позволено добавить свою строку в
x$ksqeq, означает ли это разрешение на использование ресурса? Если нет, как определить момент, когда ресурс освободится?
Представление v$lock
Прежде чем пойти дальше, давайте извлечем несколько строк из v$lock и посмотрим, как они выглядят в SGA:
select
sid, type, id1, id2, lmode, request, ctime, block
from v$lock
where
type = ‘TM’
and id1 = 82772
;
SID TY ID1 ID2 LMODE REQUEST CTIME BLOCK
------- -- ---------- --------- --------- ---------- --------- ---------
37 TM 82772 0 3 5 66 1
36 TM 82772 0 3 0 42 1
39 TM 82772 0 0 6 27 0
35 TM 82772 0 0 3 3 0
У меня есть четыре сеанса, где обрабатывается таблица, являющаяся дочерней в иерархии родитель/потомок, и которая не имеет индексов поддержки ограничения внешнего ключа. Чтобы войти в это состояние, я выполнил в четырех сеансах следующие операции:
- Сеанс 37: единственный потомок родителя 1.
- Сеанс 36: единственный потомок родителя 2.
- Сеанс 39: пытается заблокировать дочернюю таблицу для монопольного использования (и переходит в режим ожидания).
- Сеанс 37: пытается удалить родителя 1 (и переходит в режим ожидания из-за отсутствия индекса внешнего ключа).
- Сеанс 35: пытается удалить единственного потомка родителя 3 (и переходит в режим ожидания).
Я придумал эту маловероятную последовательность событий, потому что хотел показать диапазон возможностей блокировок. Без начальной информации, которую я дал вам, было бы трудно понять, какая последовательность шагов привела к появлению такого набора строк в v$lock, даже при том, что все необходимые для этого подсказки находятся в выводе. На рис. 1 приводится графическое изображение ситуации.
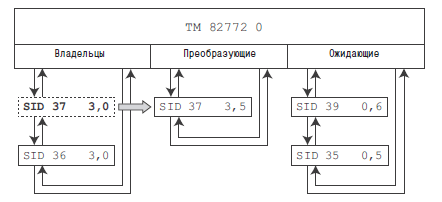
Рис. 1. Графическое изображение ситуации, описываемой строками в v$lock
Указатели на три двусвязных списка (в таких случаях их часто называют очередями) хранятся в одной строке из x$ksqrs (v$resource). Все списки включают элементы, каждый из которых является строкой, представляющей одну из структур блокировок с очередями, выбор структуры определяется типом представляемого ресурса. В данном случае блокировки с очередями получены из x$ktadm, потому что ресурсом является таблица (ресурс типа TM).
Списки хранят ссылки на процессы, владеющие блокировками (иногда говорят «удерживающие блокировки»), преобразующие и ожидающие. Процесс, «блокирующий» объект, должен добавляться в конец очереди ожидающих процессов, если очередь ожидающих или преобразующих процессов не пуста, и только потом можно будет добавить его в конец очереди владеющих процессов, если указанный режим блокировки совместим с режимами, уже присутствующих в очереди владельцев.
Примечание. В Oracle есть несколько мест, где процесс может приобрести блокировку в одном режиме, чтобы выполнить какую-то начальную работу, а затем более агрессивную блокировку, чтобы выполнить дополнительные операции, если потребуется. Для этого нужно выполнить «преобразование блокировки». Это не то же самое, что эскалация блокировки (lock escalation) – механизм, который не нужен в Oracle. Для преобразования, например, иногда необходимо заменить несколько блокировок строк единственной табличной блокировкой, чтобы минимизировать число блокировок, приобретенных сеансом для ресурса.
Наиболее типичным примером преобразования блокировок является проблема блокирования внешнего ключа. Если вы объявили внешний ключ в таблице, но не создали индекс для поддержки ограничений, тогда сеанс, пытающийся удалить или изменить значение родительского ключа, попытается заблокировать дочернюю таблицу с помощью разделяемой блокировки (режим 4); однако, если перед изменением родительской таблицы сеанс удалил несколько записей из дочерней таблицы, это означает, что он уже владеет блокировкой таблицы в режиме монопольной строки (subexclusive lock, режим 3) и ему достаточно преобразовать с повышением режим блокировки. В действительности правила преобразования режимов требуют поднять режим блокировки до 5, а не до 4, что и наблюдается в примере sdit.
Итак, на рис. 1 видно, что сеанс с SID 35 помещен в конце очереди ожидающих процессов, потому что в ней уже имеется процесс с SID 39. Процесс с SID 39 вынужден ждать, потому что процесс с SID 37 находится в очереди преобразующих процессов. Процесс с SID 37 застрял в очереди преобразующих процессов, потому что ему требуется преобразовать блокировку из режима 3 в режим 5, а процесс с SID 36 в очереди владельцев удерживает эту блокировку в режиме 3 – никакой другой процесс не сможет получить эту блокировку в режиме 5, если имеется хотя бы один процесс, удерживающий ее в режиме 3.
Как только процесс выполнит подтверждение (или отмену) транзакции, очереди двинутся вперед, как описывается ниже:
- Когда процесс с SID 36 подтвердит транзакцию, очередь владельцев опустеет, процесс с SID 37 переместится из очереди преобразующих процессов в очередь владельцев, приобретя блокировку в режиме 5 и установив значение
ctimeв 0. Сеансы 39 и 35 останутся в очереди ожидающих процессов. - Когда процесс с SID 37 подтвердит транзакцию, очередь владельцев вновь опустеет и в нее переместится процесс с SID 39, приобретя блокировку в режиме 6 и установив значение
ctimeв 0. Процесс с SID 35 теперь окажется в начале очереди ожидающих процессов, но он не сможет перекочевать в очередь владельцев, потому что невозможно приобрести блокировку на таблицу, если имеется сеанс, владеющий ею в монопольном режиме (6). - Когда процесс с SID 39 подтвердит транзакцию, очередь владельцев опять опустеет и в нее переместится процесс с SID 35, приобретя блокировку в режиме 3 и установив значение
ctimeв 0.
Если сравнить эту картину с выдержкой из v$lock, что была показана выше, можно заметить, что обычно невозможно получить цельную картину происходящего без некоторой доли везения (или услуг автора). В данном случае можно видеть, что сеанс 36 владеет блокировкой в режиме 3, блокирующей нечто неизвестное (block = 1). Так как известно, что процессы, находящиеся в очереди преобразующих, имеют преимущество перед ожидающими процессами, можно сделать вывод, что сеанс 37 блокируется сеансом 36 и желает приобрести блокировку на тот же самый объект. Из листинга видно, что сеансы 35 и 39 также заблокированы, но мы не можем сказать, какой из них находится в начале очереди – к счастью, я выдерживал паузу в несколько секунд после каждого шага, поэтому по значению в столбце ctime можно сказать, что сеанс 39 был помещен в очередь примерно на 24 секунды раньше, чем сеанс 35. Однако, столбец ctime обновляется, только когда истекает таймаут блокировки – обычно раз в 3 секунды – поэтому его значение не всегда позволяет сделать правильные выводы (это одно из мест, где оказывается недостаточно информации о происходящем, о чем я говорил выше):если в очередях преобразующих или ожидающих процессов имеется несколько сеансов, не всегда можно с уверенностью сказать, какой из них возобновит работу первым.
Примечание. Если процесс ожидает приобретения блокировки, столбец ctime сообщает, как долго он ожидает, а если процесс владеет блокировкой, этот столбец сообщает, как долго процесс удерживает блокировку. Но, если процесс выполняет преобразование блокировки из одного режима в другой, о чем сообщает этот столбец? О времени ожидания возможности преобразовать блокировку в другой режим или о времени удержания блокировки в прежнем режиме? Было бы полезно знать и то и другое, но в данном случае столбец сообщает о времени удержания блокировки в прежнем режиме. Было бы хорошо, если бы в Oracle Corp. догадались расширить представление (и соответствующий код), чтобы можно было узнать оба времени.
Когда действительно необходимо получить больше информации, находясь в стесненных рамках шаблона использования блокировок, можно попробовать вывести дамп трассировки. В нем вы увидите множество информации, и чтобы разобраться в ней может потребоваться выполнить форматирование и декодирование, но в конечном итоге вы сможете получить более или менее полную картину происходящего. Получить дамп можно командой:
alter session set events ‘immediate trace name enqueues level 3’
Ниже приводится выдержка из файла трассировки, полученная мною после использования всех блокировок:
res identification NUL SS SX S SSX X md link
owners converters waiters
-------------------------------------------------------------------------
21A4CD90 TM-00014354-00000000 U 0 0 2 0 0 0 8 [21a5534c,21a5534c]
[212d1190,212d1190] [212d1008,212d1008] [212d1254,212d13dc]
lock que owner session hold wait ser link
----------------------------------------------------------------------
212D1188 OWN 2198C2C4 2198C2C4 (036) SX NLCK 12 [21a4cd98,21a4cd98]
212D1000 CON 2198D5AC 2198D5AC (037) SX SSX 65 [21a4cda8,21a4cda8]
212D124C WAT 2198FB7C 2198FB7C (039) NLCK X 17 [212d13dc,21a4cda0]
212D13D4 WAT 2198AFDC 2198AFDC (035) NLCK SX 6 [21a4cda0,212d1254]
Здесь имеется две строки с информацией о каждом ресурсе, начиная с его адреса в x$ksqrs, за которым следуют идентификационные данные о ресурсе (type, id1, id2).
Вторая строка определяет три связанных списка и имеет формат, типичный для всех файлов трассировки: два адреса в квадратных скобках, первый из которых действует как «прямой указатель», а второй – как «обратный указатель». В данном случае первый адрес указывает на первый элемент связанного списка, а второй – на последний элемент, но имейте в виду, что адреса имеют 8-байтное смещение. Взгляните на пару указателей в очереди ожидающих сеансов (waiters): прямой указатель (212d1254) минус 8 – получается значение, которое можно видеть в начале третьей строки под заголовком lock, а обратный указатель (212d13dc) минус 8 дает значение в начале четвертой строки. То же самое наблюдается в парах указателей очередей владельцев (owners) и преобразующих сеансов (converters), с той лишь разницей, что в этих очередях прямой и обратный указатели совпадают, потому что содержат только по одному элементу.
Тот же самый формат представления связанного списка можно наблюдать в разделе информации о блокировках, в столбце link. И снова проще начать исследование с ожидающих сеансов (que = WAT). Обратите внимание, что прямой указатель (212d13dc) минус 8, в строке 3, дает адрес блокировки (lock) в строке 4, а обратный указатель (212d1254) минус 8 в строке 4 соответствует адресу блокировки в строке 3.
Наконец, можно видеть, что обратный указатель в строке 3 и прямой указатель в строке 4 оба (21a4cda0) ссылаются на адрес ресурса (21A4CD90), хотя в этот раз смещение составляет 32 байта, а не 8. (Та же логика действует для списков преобразующих (converters) и владеющих (owners) сеансов, с той лишь разницей, что для владельцев смещение составляет 8 байт, а для преобразующих сеансов – 24 байта. Это может показаться странным, но, скорее всего, это всего лишь ссылки на определенные поля, а не на начало всей записи.)
Взаимоблокировка
Вернемся к рис. 1. Возможно вам интересно узнать, что произойдет, если сеанс 36 решит удалить родительскую строку в случае успешного удаления дочерней строки. Так как индекс внешнего ключа отсутствует, ему придется преобразовать свою блокировку из режима 3 в режим 5, для чего потребуется встать в очередь преобразующих сеансов, вслед за сеансом 37 – добавление в очередь всегда выполняется в ее конец.
Когда я рисовал картинку для рис. 1, я оставил «призрак» сеанса 37 в очереди владельцев. Если вы посмотрите на дамп из файла трассировки, вы увидите, что в действительности этого сеанса там нет, но для визуализации особенностей работы Oracle весьма полезно представлять, что он все еще находится в очереди владельцев, оставаясь при этом в очереди преобразующих сеансов.
Итак, в данный момент сеанс 37 находится в очереди преобразующих процессов, ожидая, пока опустеет очередь владельцев, а сеанс 36 находится «позади» сеанса 37. Но сеанс 36 (или его «призрак») находится также в очереди владельцев, то есть, сеанс 36 располагается «впереди» сеанса 37 – мы получили простую ситуацию взаимоблокировки, когда каждый из двух сеансов ждет, когда другой уйдет.
В течение 3 секунд один из сеансов выполнит откат на уровне инструкции и сгенерирует ошибку Oracle «ORA-00060, deadlock detected» («ORA-00060, обнаружена взаимоблокировка»), с выводом трассировочной информации в файл трассировки сеанса. Хотя руководства утверждают, что сеанс выбирается случайно, я обнаружил, что всегда выбирается сеанс, имеющий более длительный период ожидания. В данном случае таковым является сеанс, находящийся в начале очереди преобразующих процессов, то есть, сеанс 37. Такое поведение объясняется тем, что блокировка с очередью TM (как и многие другие типы подобных блокировок) имеют величину таймаута, равную 3 секундам. То есть, каждые 3 секунды сеанс, ожидающий на блокировке TM, будет возобновлять выполнение, проверять состояние всех табличных блокировок и (обычно) опять приостанавливаться на следующие 3 секунды. Такая проверка по таймауту позволяет сеансу заметить факт взаимоблокировки и сгенерировать ошибку.
Так что же должен сделать сеанс 37, обнаружив ошибку? Многие приложения отвечают на ошибку простым завершением сеанса (автоматически устраняя все проблемы с блокировками неявным выполнением отката). Некоторые приложения явно вызывают команду rollback;, которая также устраняет проблему, но может потребовать больше времени, чтобы откатиться до исходного состояния. Некоторые, к сожалению, просто повторяют последний шаг, который в данном случае поместит сеанс 37 в очередь ожидающих процессов, вслед за сеансом 36, в результате чего сеанс 36 обнаружит взаимоблокировку и сообщит об ошибке в течение ближайших 3 секунд. И если приложение останется верным себе, оно выполнит повторную попытку в сеансе 36, заставив сеанс 37 обнаружить взаимоблокировку в течение следующих 3 секунд. Круг замкнулся.
Проблема взаимоблокировок не имеет достаточно хорошего решения. Откат транзакции является безопасной, но потенциально дорогостоящей операцией; завершение сеанса с особым ущербом в виде невыполненной работы является не лучшей альтернативой. В идеале можно было бы подумать о проектировании приложения так, чтобы любые продолжительные задачи (для которых такая ситуация особенно важна) при получении ошибки взаимоблокировки выявляли вовлеченные сеансы и либо сообщали администратору о проблеме, либо определяли, в каком сеансе откат потребует меньше времени, и завершали его. В любом случае, не следует разрешать приложениям откликаться на ошибки взаимоблокировки бесконтрольно.
Примечание. Хотя я сказал, что ошибка взаимоблокировки передается сеансу, ожидавшему дольше других, я должен отметить, что в версии 9.2.0.1 мне удалось воспроизвести весьма специфичную ситуацию, когда оба сеанса одновременно получили ошибку взаимоблокировки. Мне не удалось воспроизвести ее в других версиях Oracle, поэтому, на мой взгляд, это был временный побочный эффект (или ошибка в реализации), вызванный изменениями в диспетчере блокировок с очередями в версии 9.2.

Возможно также (по крайней мере теоретически), что этот шаблон может «поломать» планировщик операционной системы. Даже если два ожидающих сеанса перезапустить в правильном порядке, это означает лишь, что в этом порядке они попадут в очередь действующих процессов. Если аппаратная часть реализует несколько очередей выполнения, есть вероятность, что процесс, попавший в очередь вторым, будет запущен первым.
Для демонстрации вовлеченных структур я использовал табличные блокировки и показал один классический пример блокировок и взаимоблокировок. Взаимоблокировки внешних ключей встречаются достаточно часто, но, скорее всего, вам чаще будут встречаться ошибки взаимоблокировки транзакций, или (второе их название) взаимоблокировки данных.
Как было показано в этой статье, слот в таблице транзакций является «точкой концентрации» всех работ, выполняемых в рамках транзакции, и в этом слоте будут храниться ссылки на все блоки данных (и индексов), измененные транзакцией, в виде списка заинтересованных транзакций (Interested Transaction List, ITL). Сеанс, выполняющий транзакцию, блокирует слот в таблице транзакций, создавая ресурс (типа TX, где id1 представляет номер undo-сегмента и номер слота, а id2 – последовательный номер слота) и добавляя блокировку с очередью – в частности, строку из x$ktcxb – в режиме 6 (исключительный, или монопольный режим).
Если второму сеансу потребуется изменить строку, измененную, но не подтвержденную первым сеансом, он встанет в очередь к ресурсу TX первого сеанса, запросив исключительную блокировку, и попадет в очередь ожидающих сеансов. Если в этот момент первый сеанс решит изменить строку, измененную, но не подтвержденную вторым сеансом, он встанет в очередь к ресурсу TX второго сеанса, и так же попадет в очередь ожидающих сеансов.
Как результат, первый сеанс окажется в очереди ожидающих на получение доступа к ресурсу TX второго сеанса, а второй сеанс – в очереди ожидающих на получение доступа к ресурсу TX первого сеанса.
Классический пример взаимоблокировки транзакций (или данных). В течение 3 секунд один из сеансов получит ошибку «ORA-00060» и произведет откат последней выполненной инструкции; если взаимоблокировка возникнет в блоке PL/SQL, где отсутствует обработчик исключений, будет выполнен откат результатов всех инструкций в этом блоке.
Примечание. Когда возникает ошибка взаимоблокировки данных и в файл трассировки выводится информация об ошибке, самыми ценными строками в блоке информации (по крайней мере с точки зрения Oracle Corp.) будут строки:
DEADLOCK DETECTED ( ORA-00060 ) [Transaction Deadlock] The following deadlock is not an ORACLE error. It is a deadlock due to user error in the design of an application or from issuing incorrect ad-hoc SQL.
(Ошибка «ORA-00060» – это (практически всегда) программная ошибка, хотя, последние изменения в 11g иногда приводят к очень странному поведению механизма блокировок.)
Когда возникает взаимоблокировка, сеанс, получивший ошибку, выводит блок информации в файл трассировки. Этот блок содержит массу сведений, но самые интересные из которых начинаются с графа взаимоблокировки (для нашего простого случая):
Deadlock graph:
---------Blocker(s)-------- ---------Waiter(s)---------
Resource Name process session holds waits process session holds waits
TX-00030026-000040d6 13 38 X 12 50 X
TX-00060002-00004113 12 50 X 13 38 X
В этом графе видно, что сеанс 38, процесс 13 удерживал блокировку TX (undo-сегмент 3, слот 38 (0x26), номер в последовательности 16 598) в режиме 6, а сеанс 50, процесс 12 ждал ее приобретения. Кроме того, сеанс 50 удерживал блокировку TX (undo-сегмент 6, слот 2, номер в последовательности 16 659), а сеанс 38 ждал ее приобретения.
Остальное содержимое трассировочного файла описывает инструкции SQL, которые выполнялись сеансами в момент появления ошибки, идентификаторы строк (rowid), где возникла проблема и дамп состояния всего процесса сеанса, вызвавшего ошибку.
Здесь следует отметить пару важных моментов. Во-первых, в клинч могут войти сразу несколько сеансов; состояние взаимоблокировки не ограничивается двумя сеансами, хотя такая ситуация встречается чаще других. Во-вторых, наиболее часто взаимоблокировки вызываются блокировками типа TX в режиме 6, всегда можно спроектировать сценарий, приводящий к взаимоблокировке, когда есть вероятность остановиться в ожидании на блокировке (как это было показано в обсуждении выше).
Примечание. Когда возникает взаимоблокировка транзакций, один из вовлеченных сеансов должен выполнить commit; или rollback;, чтобы решить проблему. Даже при том, что в транзакции есть возможность установить точку сохранения, важно помнить, что откат до точки сохранения не поможет выйти из состояния взаимоблокировки, так как при этом не освобождается ресурс TX; все, что делает механизм отката в этом случае – применяет все записи отмены, созданные с момента установки точки сохранения.
Существует несколько разновидностей взаимоблокировок TX, о которых хотелось бы упомянуть. Если одна из таблиц является индекс-организованной таблицей (Index Organized Table, IOT), один из сеансов будет ожидать блокировки в режиме S (share – разделяемая). IOT – это индекс, и если требуется внести изменения в IOT, ожидается приобретение блокировки в режиме 4 (share – разделяемая), а не 6 (exclusive – исключительная).
Это влечет некоторые дополнительные следствия, имеющие отношение к индексам – примите во внимание мой комментарий выше, где я говорил, что при наличии вероятности остановиться в ожидании освобождения блокировки, всегда есть шанс попасть в состояние взаимоблокировки. К конфликтам при работе с индексами могут приводить разнообразные ошибки программирования, например:
- два сеанса пытаются одновременно изменить значение одного и того же первичного ключа;
- один сеанс вставляет строку в дочернюю таблицу, а другой удаляет соответствующую ей строку из родительской таблицы;
- один сеанс вставляет строку в родительскую таблицу, а другой пытается вставить соответствующую ей строку в дочернюю таблицу до того, как первый сеанс подтвердит транзакцию;
- два сеанса пытаются удалить строки, которые охватываются одним и тем же фрагментом битового индекса.
По сути, если из-за конфликта по индексам (или, может быть, из-за ограничений, накладываемых этими индексами) один сеанс ожидает, пока другой подтвердит изменения, вы увидите ожидание блокировки TX в режиме 4. Существует ситуация с индексами, когда проблема не связана с ошибками программирования – она проявляется, когда приходится ждать, пока другой сеанс завершит разделение листового блока (leaf block split).
Имеются и другие причины, вызывающие ожидание TX/4. Наиболее общей (хотя и редко проявляющейся) причиной является необходимость изменить в транзакции блок, список ITL которого заполнен активными транзакциями и в нем не осталось свободного места. Если это происходит слишком часто, следует подумать о том, чтобы найти проблемный объект и изменить его определение (обычно достаточно изменить значение initrans). В версии 10g ожидание освобождения места в списке ITL отображается как ожидание особого типа TX (enq: TX - allocate ITL entry), а информация об объектах сохраняется в отчетах Statspack и AWR в виде Segments by ITL Waits.
Распределенные транзакции также могут быть причиной появления ожиданий TX/4 и, что удивительно, подобные типы ожиданий могут появляться даже при выполнении инструкций select. В последних версиях Oracle (9.2.0.6 и выше) подобное может происходить, только при использовании связей между базами данных (database links); в предшествующих версиях это могло происходить в XA-совместимых мониторах обработки транзакций (Transaction-Processing Monitors, TPM). Проблема обусловлена действиями механизма двухфазного подтверждения транзакций (two-phase commit, 2PC) – если удаленная база данных изменила некоторые ваши данные и выполнила подготовительный шаг, но не успела выполнить заключительный шаг в последовательности двухфазного подтверждения, ваша база данных не знает, как интерпретировать изменения – как подтвержденные или как отмененные, поэтому любой сеанс, запросивший измененные данные, вынужден будет ждать, пока не произойдет подтверждение (или откат). (При использовании XA-совместимого TPM, Oracle просто создает согласованную версию данных, что, теоретически, может привести к несогласованным результатам, с точки зрения распределенной системы.)
Существует еще ряд весьма экзотических причин появления ожиданий TX/4. Одна из них связана с нехваткой списков свободных блоков (но это весьма редкая ситуация и как бы то ни было, в большинстве систем эти списки не используются). Другая связана с ожиданием прекращения роста файла данных, поэтому обязательно посмотрите, какое значение установлено в параметре autoextend в вашей системе. Кроме того, когда производится переключение табличного пространства в режим «только для чтения», возникает необходимость дождаться завершения всех активных транзакций в этом табличном пространстве, однако подобная необходимость возникает достаточно редко.
Режимы блокировок
Мне всегда было трудно запомнить названия разных уровней (или режимов) блокировок в Oracle. Я больше привык к восприятию числовой информации, а Oracle не особенно стремится помочь в этом, определяя порой по два разных названия для некоторых режимов. Поэтому ниже я привожу табл. 1 со списком режимов блокировок и с кратким описанием их применения к таблицам. Понять работу режимов проще всего в контексте таблиц, поэтому описание касается таблиц, но вообще говоря, любой ресурс может стать целью блокировки в любом из режимов.
| Режим Имя | Применение к таблице |
| 1 Null Lock (NL) | Не применяется к таблицам. Удерживается параллельными подчиненными процессами в ходе выполнения некоторых параллельных операций DML (например, обновление), пока QC удерживает монопольную блокировку. |
| 2 Sub Share (SS) Row Share (RS) | Выборка для обновления (select for update) до 9.2.0.5. Блокировка таблицы в режиме разделяемой строки. Блокировка таблицы в режиме разделяемого обновления. Используется для ограничения ссылочной целостности в ходе выполнения инструкций DML, начиная с 9.2.0.1. |
| 3 Sub Exclusive (SX) Row Exclusive (RX) | Обновление (а также выборка для обновления, начиная с 9.2.0.5). Блокировка таблицы в режиме монопольного владения строкой. Используется для ограничения ссылочной целостности в ходе выполнения инструкций DML, начиная с 11.1. |
| 4 Share (S) | Блокировка таблицы в разделяемом режиме. Может появляться в ходе параллельного выполнения инструкций DML в параллельных подчиненных процессах, кроме тех, что имеют id2 = 1, то есть это не обычный ресурс таблицы. Типичный симптом проблемы блокирования внешнего ключа (из-за отсутствия индекса). |
| 5 Share Sub Exclusive (SSX) Share Row Exclusive (SRX) | Монопольная блокировка таблицы в режиме разделяемой строки. Менее типичный симптом проблемы блокирования внешнего ключа, но может часто появляться, если используется ограничение внешнего ключа on delete cascade. |
| 6 Exclusive (X) | Блокировка таблицы в монопольном режиме. |
Если вы не реализовали в приложении какие-то необычные операции и не учитываете некоторые ошибки, связанные с блокировками, которые появились в 11g, тогда единственное, о чем следует вспомнить, увидев режим 4 или 5, – не забыли ли вы создать индекс для внешнего ключа.
Фактически, в большинстве приложений табличные блокировки появляются только в режиме 3, когда выполняется обновление таблиц, а режим 2 (в версиях 9.2) связан с внешними ключами.
Защелки для блокировок
Мы еще не ответили на вопрос, как эффективно узнать, нужно ли добавить новую строку в x$ksqrs (v$resource) для представления нового ресурса, или такая строка уже имеется и следует только присоединить к ней свою блокировку. У нас также неразрешенным остался вопрос о кажущихся случайными значениях «ссылок» в файле трассировки.
Чтобы ответить на эти вопросы, следует познакомиться с еще двумя разделами инфраструктуры – возвращающих нас к массивам, указателям, связанным спискам и хэш-таблицам, работа с которыми неразрывно связана с применением защелок.
Мы уже знаем, что x$ksqrs и x$ksqeq (которые я использовал как представителей остальных структур блокировок с очередями) являются массивами – каждая строка в них имеет фиксированный размер и мы легко можем получить n-ю строку, зная, где начинается массив и размер одной строки в нем. Но мы также знаем, что каждая строка в этих структурах хранит множество указателей – мы видели их в блоке информации из трассировочного файла, даже при том, что они невидимы в самих структурах x$ – и манипулируя указателями, Oracle может «видоизменять» массивы, превращая их в нечто совсем иное.
Мы уже видели, что к массиву ресурсов (x$ksqrs) подключены три двусвязных списка, образующих цепочки из массивов в очереди (x$ksqeq, и др.). Но мы пока не видели, как Oracle обеспечивает эффективную работу с этими структурами. Ответом может служить изображение схемы библиотечного кэша на рис. 2.
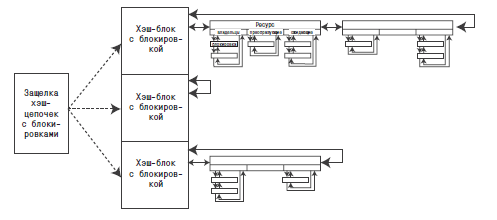
Рис. 2. Блокировки с очередями и используемые ресурсы – общая картина
Ресурс на рис. 2, подписанный как «Ресурс» – это миниатюрная копия ресурса, изображенного на рис. 1, но теперь он показан, как один из элементов в хэш-цепочке. Общую картину лучше объяснить, описав процесс приобретения блокировки:
- На основе идентификатора ресурса (
type, id1, id2) генерируется хэш-значение. Размер хэш-таблицы, похоже, выбирается равным2 * число_сеансов + 35, то есть не соответствует привычным шаблонам «простое число» или «степень 2»! - Хэш блоки защищены защелками, которые называют защелки хэш-цепочек с блокировками (enqueue hash chains latches). Число защелок соответствует числу процессоров, и хэш-блоки «циклически» распределяются между защелками. Поэтому нужно сначала получить защелку и затем выполнить поиск хэш-блока (то есть, обойти элементы цепочки), чтобы узнать, была ли строка из
x$ksqrsсвязана с этой хэш-цепочкой для представления ресурса, который требуется заблокировать. - Если ресурс уже присутствует в очереди, можно извлечь строку из соответствующей структуры (
x$ksqeq, и др.), но для этого нужно получить соответствующую защелку, чтобы не дать другим сеансам получить доступ к той же очереди в то же время. Выбор защелки для приобретения зависит от типа блокировки с очередью; например, чтобы получить строку изx$ksqeq, нужно приобрести защелку для очереди, а чтобы получить строку изx$ktadm, нужно приобрести защелку «dml allocation». Защелка должна освобождаться сразу же, как только строка из очереди оказывается в безопасности. - Если ресурс отсутствует в очереди, тогда (продолжая удерживать защелку хэш-цепочек с блокировками) нужно выбрать строку из
x$ksqrs, отметить ее для представления вашего ресурса, добавить в хэш-цепочку и затем извлечь строку из очереди для связи с ней. - • Когда все это будет сделано, можно освободить защелку хэш-цепочек с блокировками.
Есть два места, где нам, вероятно, придется побеспокоиться об эффективности, и в обоих случаях придется проделать одну и ту же работу: если нужно получить строку из ресурса или блокировки в очереди, возможно ли избежать необходимости просматривать все элементы массива в поисках неиспользуемого? В большой, высоконагруженной системе с огромным числом ресурсов и блокировок может потребоваться обойти значительную часть массива, прежде чем будет найден свободный элемент.
Как это ни удивительно, но, похоже, что Oracle именно так и поступает, когда пытается найти строку в очереди (из x$ktadm, x$ksqeq или [как мне кажется] из любых других коротких массивов).
С другой стороны, массив x$ksqrs обрабатывается совершенно иначе. Я не уверен в абсолютной точности, и фактическая стратегия может иметь пару-тройку отличий, которые трудно выявить экспериментальным путем, но, наблюдая за тем, как Oracle извлекает ресурсы из хэш-цепочки, создается впечатление, что имеется какой-то другой механизм, использующий другой набор указателей в «связанных списках», которые образуют структуру в виде стека (LIFO), чтобы всегда была возможность непосредственного доступа к первой свободной строке в x$ksqrs, и не нужно было выполнять поиск по массиву.
Я думаю, что имеется также механизм, реализующий стратегию «отложенной очистки». Когда с ресурса снимается последняя блокировка, похоже, что Oracle оставляет этот ресурс в хэш-цепочке, просто помечая его как «доступный для повторного использования». Преимущество такого решения состоит в том, что через некоторое время все хэш-цепочки будут содержать по несколько «пустых» ресурсов, поэтому, если вы не найдете требуемый ресурс, загляните в хэш-цепочку – вы наверняка найдете там пустой, готовый к использованию ресурс, и вам не придется сканировать массив x$ksqrs. Если это предположение верно, где-то должен быть и код, обрабатывающий ситуацию отсутствия свободных ресурсов в хэш-цепочке, когда остается только одна возможность – передать ресурс из другой хэш-цепочки.
Если вам будет интересно самим заняться исследованием тонкостей работы Oracle, одной из лучших отправных точек для этого является механизм блокировок с очередями. В нем используются методы и структуры, встречающиеся в Oracle повсеместно, но блокировки с очередями лучше других подходят для исследований – они действуют достаточно медленно и просты в управлении, поэтому наблюдать за их деятельностью и делать выводы намного проще.
Блокировки KGL (и закрепления)
После знакомства с основами блокировок с очередями (enqueues), мне почти нечего добавить по теме блокировок библиотечного кэша (а также закреплений и мьютексов); мы узнали, почему необходимо защищать области памяти в многопользовательских системах, и поговорили о необходимости иметь как можно более эффективный механизм поиска участков памяти.
Используя начальное представление библиотечного кэша, мы исследовали роль хэш-блоков со связанными списками, как эффективного механизма поиска (или размещения) объектов. Затем мы рассмотрели представление ресурса (рис. 1) с множеством цепочек блокировок, связанных с ним – этот шаблон взят за основу организации библиотечного кэша (хотя объекты, попадающие в библиотечный кэш, берутся из разных структур x$). Наконец, на примере хэш-цепочек с блокировками (рис. 2) мы познакомились с защелками и коллекцией хэш-блоков, которую они защищают. Защелки и хэш-блоки в библиотечном кэше продолжали использоваться в неизменном виде до версии 10g, но к моменту выхода версии 11.2 этот механизм полностью изменился. Однако мы пока продолжим придерживаться старых решений в реализации библиотечного кэша, потому что они все еще используются в буферном кэше, даже в 11g.
Каждый объект в библиотечном кэше принадлежит некоторому хэш-блоку, номер которого определяется по имени объекта (термин «имя» в данном контексте имеет более широкое толкование, чем, может быть, вы привыкли). Хэш-блоки примерно равномерно распределены между защелками библиотечного кэша, число которых, по всей видимости, соответствует числу процессоров, но не превышает 67 (у вас, как и меня, может сложиться впечатление, что действительное число защелок невелико). Самым существенным отличием блокировок, присоединяемых к объектам в библиотечном кэше, от блокировок, присоединяемых к ресурсам в очереди, является наличие двух множеств структур, связанных с объектами в библиотечном кэше, – блокировок KGL и закреплений (pins) KGL – и я не думаю, что в Oracle создается три очереди для каждого типа, то есть я считаю, что может быть только две очереди: очередь владельцев и очередь ожидающих сеансов.
Блокировки и закрепления
В объектах библиотечного кэша используются две структуры блокировок, потому что они выражают два разных намерения. (Должен отметить, что лично я никогда не считал использование двух структур оправданным и необходимым, но, вероятно, просто потому, что я не обдумывал требования достаточно глубоко – возможно, разработчики приняли такое решение для повышения масштабируемости.)
Важнейшей задачей блокировки KGL (KGL lock, которая экспортируется из x$kgllk и доступна в v$open_cursor) является улучшение параллелизма. Если сеанс владеет блокировкой KGL для некоторого объекта – и для инструкции SQL, то есть блокирует родительский курсор и соответствующий дочерний курсор, – у него автоматически появляется возможность непосредственно перейти по адресу объекта, без необходимости получать защелку хэш-цепочки библиотечного кэша и выполнять поиск в этой хэш-цепочке.
Убедиться, что такой подход дает экономию времени, можно тремя основными способами:
- Можно написать клиентский код, «захватывающий» курсор, о котором известно, что он используется достаточно часто.
- Можно присвоить параметру
session_cached_cursorsтакое значение, что библиотечный код в Oracle автоматически будет захватывать курсор, обнаружив, что инструкция используется вами два или три раза. - Выгоду можно получить от особенности PL/SQL полуавтоматически захватывать курсоры, открываемые (явно или неявно) в вызовах PL/SQL – начиная с версии 9.2.0.5, этой особенностью управляет также параметр
session_cached_cursors.
Примечание. Параметр session_cached_cursors определяет максимальное число курсоров, которые могут удерживаться, когда ваш код явно не захватывает курсоры. Он также управляет числом курсоров, которые могут удерживаться открытыми кодом PL/SQL, выполняющимся в сеансе. Исторически (до версии 9.2.0.5) размер кэша курсоров в PL/SQL определялся параметром open_cursors. Многие присваивают параметру open_cursors довольно большое значение (иногда слишком большое), но в параметре session_cached_cursors зачастую оставляют значение по умолчанию, которое в многих ситуациях оказывается слишком маленьким.
Закрепление KGL (KGL pin) вступает в игру, когда вы фактически начинаете использовать объект. Несмотря на то, что блокировка KGL будет удерживать объект в памяти, некоторые части объекта воссоздаются динамически (например, план выполнения инструкции SQL), и эти части могут удаляться в случае нехватки памяти, даже при наличии блокировки KGL.
Однако, когда начинается фактическое использование объекта (например, запускается инструкция SQL), необходимо гарантировать, что воссозданные его части не будут удалены из памяти, поэтому объект закрепляется.
Блокировки и закрепления KGL сами по себе являются небольшими участками в памяти, которые создаются и освобождаются по требованию, операциями управления памятью в разделяемом пуле. Так как блокировка KGL занимает примерно 200 байт, а закрепление KGL – 40 байт, можно предположить, что постоянное выделение памяти для них и ее освобождение могут вызывать сильную фрагментацию пула, когда имеется множество свободных блоков, но ощущается нехватка блоков достаточно большого размера. Ситуация с закреплениями KGL особенно осложняется коротким периодом их существования; ситуация с блокировками KGL немного лучше, потому что они остаются присоединенными к объектам более продолжительное время.
Другая проблема с блокировками и закреплениями KGL заключается в необходимости постоянно манипулировать связанными списками, присоединять и отсоединять фрагменты памяти, и делать это, удерживая защелку в монопольном режиме (а, как я уже отмечал, в библиотечном кэше имеется удивительно небольшое число защелок). Поэтому в высоконагруженных системах проблема блокировок/закреплений могла нести существенную угрозу масштабируемости. Чтобы ослабить эту угрозу, в версии 10g были реализованы защелка блокировки библиотечного кэша (library cache lock latch) и защелка закрепления библиотечного кэша (library cache pin latch), которые обеспечили некоторую возможность параллельного использования разных хэш-блоков, охватываемых одной и той же защелкой библиотечного кэша (library cache latch, появилась возможность закрепить курсор в одном хэш-блоке и одновременно заблокировать курсор в другом хэш-блоке, потому что отпала необходимость приобретать одну и ту же защелку библиотечного кэша).
Однако, в процессе перехода от версии 10g к версии 11g, весь механизм блокировок/закреплений KGL постепенно заменили механизмом мьютексов.
Мьютексы, часть 2 (часть 1 здесь)
Механизм блокировок и закреплений в библиотечном кэше страдает от двух проблем. Во-первых, в кэше не так много защелок; во-вторых, слишком много усилий требуется, чтобы выделить фрагмент памяти, инициализировать его и вставить в связанный список (или, напротив, удалить из связанного списка и вернуть в пул). Поэтому в версии 11.2 было решено уйти от использования небольших фрагментов памяти и связанных списков, а также избавиться от использования защелок для защиты хэш-цепочек и заменить их мьютексами.
Мьютекс – это «микро-защелка», которая используется очень короткое время. Подобно обычной защелке, мьютекс – это всего лишь счетчик. Его можно увеличивать, чтобы показать, что «кто-то заинтересован в доступе к защищенному ресурсу», или использовать прием «изменения старшего бита», чтобы заявить: «я жду монопольного владения», – с последующим изменением другого бита, имеющего значение: «я монопольно распоряжаюсь ресурсом», – после того, как все остальные сеансы освободят мьютекс. Если погрузиться в детали реализации, мьютексы имеют массу отличий от защелок, но на более высоком уровне эти два механизма имеют много общего.
Благодаря механизму мьютексов, вы получаете по одной микро-защелке на каждый хэш-блок, вместо, максимум, 67 защелок, охватывающих (в моем случае) 131072 блоков. При наличии мьютексов в каждом объекте библиотечного кэша, представляющих блокировки и закрепления KGL, отпадает необходимость во всех этих операциях управления памятью и связанными списками. (В действительности, механизм блокировок и закреплений все еще присутствует в 11.2, но весь код, использующий их, был переписан; возможно, что в ближайшем будущем этот механизм полностью исчезнет.)
Разумеется, придется переписать весь код управления хэш-цепочками, блокировками, закреплениями при работе с объектами библиотечного кэша, но, как только это будет сделано, получится система, потенциально более масштабируемая, благодаря распределению механизма управления параллелизмом по большему числу узловых точек.
Неизбежно возникает угроза нехватки информации. Структуры блокировок и закреплений KGL включали информацию о сеансе, владеющем блокировкой или закреплением. Мьютексы слишком малы и не имеют в свое составе списков. Поэтому теперь у нас имеется только односторонняя информация: сеанс знает, какими мьютексами владеет, но мьютексы не знают, какие сеансы удерживают их. Если в код поддержки мьютексов закрадется ошибка, сеанс может «потерять» мьютекс и потерпеть неудачу при попытке уменьшить его, а накладные расходы на выполнение задач проверки наличия потерянных мьютексов могут оказаться существенными.
Защелки и мьютексы имеют одно интересное отличие: защелки приобретаются процессами, тогда как мьютексы приобретаются сеансами – один процесс может действовать от имени нескольких сеансов (представьте разделяемый сервер или пул соединений). С технической точки зрения это означает, что два сеанса, действующие в рамках одного процесса, могут попасть в состояние взаимоблокировки. Однако я пока не занимался исследованием состояний, которые могли бы привести к этому.
В заключение
В многопользовательской системе, где разделяемая память используется для поддержки масштабируемости, нужны механизмы, не позволяющие двум процессам одновременно изменять одну и ту же структуру в памяти. В Oracle имеется четыре таких механизма: блокировки (locks), закрепления (pins), защелки (latches) и мьютексы (mutexes). В табл. 2 перечислены ключевые особенности этих механизмов.
| Тип | Продолжительность удержания | Поведение | Уровни |
| Защелка | Короткая | Приобретение, затем блокировка (10g+) | Разделяемый или монопольный |
| Блокировка | Долгая | Запрос с соединением | Блокировки с очередями: различные, сложные Блокировки KGL: разделяемый или монопольный |
| Закрепление | Долгая (относительно) | Запрос с соединением | Разделяемый или монопольный |
| Мьютекс | Долгая, когда действует как закрепление; короткая, когда действует как защелка | Приобретение, затем блокировка | Разделяемый или монопольный |
Для блокирования процессов, с целью предотвращения деструктивного взаимовлияния, на самом низком уровне Oracle использует защелки или их «младших братьев» – мьютексы. Есть определенные операции, которые сеанс может выполнить, только если он сначала приобретет защелку или мьютекс в установленном порядке. Обычно защелки и мьютексы основаны на атомарной операции «сравнения с обменом», которая утверждает: «Если удалось изменить значение слова с X на Y, значит можно продолжать работу».
Некоторые задачи, которые могут выполняться параллельно, требуют защиты с применением защелок или мьютексов, чтобы обеспечить последовательное выполнение деструктивных операций. Это вынудило Oracle Corp. реализовать возможность разделяемого доступа для чтения, позволяющую нескольким читающим сеансам одновременно обращаться к защищенному ресурсу, и вынуждающую пишущие сеансы приобретать защелку или мьютекс в монопольном режиме с изменением двух старших битов, поддерживающих двух-фазную стратегию «запросить/получить».
Для случаев, когда ресурс может удерживаться (относительно) продолжительное время и требуется применение механизма очередей, в Oracle имеется универсальный механизм блокировки, поддерживающий организацию очередей в виде связанных списков элементов в памяти, представляющих сеансы, желающие приобрести доступ к структуре ресурса. Имеется два основных места, где такие блокировки можно наблюдать: представление v$lock, отображающее блокировки, присоединенные к ресурсам, и представление v$open_cursor, отображающее список блокировок KGL, присоединенных к объектам библиотечного кэша (к объектам библиотечного кэша также присоединяются закрепления KGL, но они не отображаются ни в одном динамическом представлении). Две разновидности блокировок используют внешне очень похожие механизмы, но они имеют массу внутренних отличий. В последних двух версиях Oracle механизмы, имеющие отношение к блокировкам и закреплениям KGL были переделаны на использование мьютексов.

