 Теперь, познакомившись поближе с особенностями использования разделяемого пула для обслуживания содержимого библиотечного кэша, мы можем потратить некоторое время на исследование последовательности операций, выполняемых в ходе вызова
Теперь, познакомившись поближе с особенностями использования разделяемого пула для обслуживания содержимого библиотечного кэша, мы можем потратить некоторое время на исследование последовательности операций, выполняемых в ходе вызова parse для инструкции, которая прежде не была оптимизирована.
Выполняется проверка синтаксиса и определяется допустимость инструкции SQL.
Вычисляется хэш-значение для строки, определяется соответствующий хэш-блок в библиотечном кэше и проверяется наличие точно такой же строки в кэше.
В данном случае предполагается, что такая строка отсутствует, поэтому далее выполняется семантический анализ строки и проверяется присутствие в кэше словаря имен объектов, используемых в строке – это означает необходимость приобретения защелок кэша словаря и иногда выполнения некоторого кода SQL для загрузки определений в кэш.
Мы не будем останавливаться на парсинге, оптимизации и выполнении рекурсивных инструкций SQL, потому что мы уже в середине описания этого процесса. Достаточно будет сказать, что для загрузки определений в кэш может потребоваться освободить некоторую память из списка LRU в разделяемом пуле, вернуть ее в списки свободных фрагментов, затем найти свободные фрагменты и включить их в список LRU, и все это – удерживая кэш словаря строк.
После семантической проверки можно приступать к оптимизации инструкции, но при этом нужно гарантировать, что никакой другой сеанс не будет тратить свое время впустую, оптимизируя ту же инструкцию в то же время. Поэтому в данной точке приобретается некоторая память из списков свободных фрагментов (это снова означает, что может потребоваться сначала освободить некоторые объекты из списка LRU) и несколько фрагментов включается в список LRU, чтобы обеспечить удержание родительского и дочернего курсоров, а также некоторой информации о курсорах.
Примечание. Родительский курсор хранит обобщенную информацию об инструкции, дочерний курсор – информацию, касающуюся конкретного рабочего окружения, такую как имена таблиц, зависимости, окружение оптимизатора и окончательный план выполнения.
После получения родительского и дочернего курсоров они закрепляются в монопольном режиме, чтобы: (а) – они не ушли немедленно в «список LRU незакрепленных, воссоздаваемых фрагментов», оказавшись под угрозой удаления, и (б) – чтобы никакой другой сеанс не смог получить их, пока не завершится оптимизация. Если любой другой сеанс попытается оптимизировать ту же инструкцию в то же время, он перейдет в состояние ожидания (cursor: pin S waiton X – в последней версии Oracle, library cache pin – в более старых версиях).
В этот момент сеанс может сделать все необходимое для составления плана выполнения, но, поскольку я написал целую книгу, посвященную этой теме, я не буду описывать, как это происходит. Скажу лишь, что вся работа выполняется в основном в приватной памяти – после получения из кэша словаря информации о таблице, индексе и столбце, сеансу больше не потребуется обращаться к общей памяти, пока план выполнения не будет готов.
Примечание. Если описывать в общих чертах: оптимизатор находит лучший порядок соединения таблиц в запросе, определяет лучший метод соединения смежных пар таблиц и лучший метод доступа к каждой таблице. На каждом шаге выбор лучшей стратегии определяется оценкой объема данных и физической разбросанности этих данных.
В конечном итоге создается план выполнения, который должен быть сохранен в дочернем курсоре – в этот момент в разделяемом пуле приобретается дополнительная память (возможно с удалением некоторых объектов из списка LRU) и присоединяется к дочернему курсору. Планы выполнения могут быть очень большими, поэтому может потребоваться выделить несколько фрагментов памяти, из которых первый будет принадлежать классу recreate, а остальные – классу freeable.
В завершение родительский и дочерний курсоры открепляются, дочерний курсор закрепляется в разделяемом режиме, выполняется и открепляется. (Переход из монопольного в разделяемый режим означает, что любой сеанс, ожидавший окончания оптимизации той же инструкции, может теперь получить готовый к использованию план выполнения, приобрести собственное закрепление и выполнить инструкцию.)
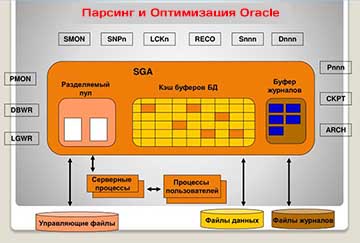
Вы можете сами оценить, какой объем работы выполняется и сколько операций с разделяемым пулом производится в ходе поиска объектов, создания и приобретения фрагментов памяти. Причем этот цикл может выполняться неоднократно в процессе оптимизации единственной инструкции. Помните, что до того, как будет начато создание плана выполнения, должна быть проверена вся информация из кэша словаря, для чего может потребоваться приобрести (относительно) большие объемы памяти для объектов в библиотечном кэше. Оптимизация – это процедура, которой желательно избегать. Просто чтобы дать вам представление о сложности манипуляций с фрагментами памяти, на рис. 1 приводится упрощенная схема строения родительского курсора с двумя дочерними курсорами.
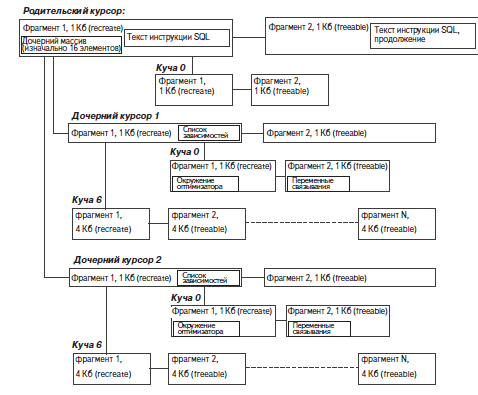
Рис. 1. Упрощенная схема строения родительского курсора с двумя дочерними курсорами
Схема на рис. 1 не совсем точно отражает способ выделения и связывания фрагментов памяти для курсоров, и различные элементы информации, такие как списки зависимостей, окружение оптимизатора и другие, в действительности не совсем так располагаются в памяти, как я показал – я позволил себе допустить поэтические отступления, только чтобы упростить картину.
Обратите внимание, что я изобразил на схеме два дочерних курсора и, взглянув на информацию, которую они несут (переменные связывания, окружение оптимизатора, списки зависимостей), вы легко поймете, как для одной инструкции SQL может быть создано несколько планов выполнения. В моем первоначальном описании процесса оптимизации не упоминалась возможность наличия сразу нескольких дочерних курсоров, но когда инструкция передается впервые, Oracle должен проверить – все ли в этой инструкции соответствует существующему дочернему курсору. Каждый дочерний курсор для данного родителя защищается той же самой защелкой библиотечного кэша, поэтому Oracle должен удерживать данную защелку на все время проверки. Очевидно, что это является одной из опасностей, которые влечет за собой установка параметра cursor_sharing в значение similar – в результате может получиться очень длинный список дочерних курсоров, подлежащих проверке.
В описании процедуры парсинга и оптимизации инструкции я пару раз упомянул закрепление (pinning). Закрепление также производится во время выполнения инструкции, и механизмы выполнения продолжали изменяться на протяжении последних нескольких выпусков Oracle, поэтому мы закончим копание в библиотечном кэше и в разделяемом пуле обсуждением выполнения, блокировки и закрепления.
Выполнение, блокировка и закрепление
Предположим, что мне требуется выполнить запрос, для которого в библиотечном кэше уже имеется подходящий дочерний курсор с готовым планом выполнения. В этой ситуации все равно придется выполнить некоторую работу, чтобы найти, подготовить и выполнить его. В худшем случае я просто передам в Oracle фрагмент текста с инструкцией. В ходе обработки текста Oracle выполнит синтаксический анализ, вычислит хэш-значение текста, найдет в библиотечном кэше соответствующий хэш-блок, просмотрит хэш-цепочку, найдет дочерний курсор, проверит его соответствие инструкции и выполнит план. В этой точке вполне может обнаружиться, что план был удален из памяти, и тогда Oracle вынужден будет повторно оптимизировать инструкцию – нарастить статистику parse count (hard) сеанса и увеличить Misses in library cache during execute, если в этот момент выполняется трассировка. Узнать, как часто такое случается, можно с помощью статистики v$librarycache.reloads для строки ‘SQL AREA’.
Примечание. Представление v$librarycache сообщает о двух причинах повторной загрузки плана выполнения: либо план был вытолкнут из памяти по требованию, либо он стал недействительным из-за переопределения некоторого зависимого объекта. Ориентировочно разность reloads - invalidations позволит оценить, сколько работы приходится делать из-за проблем, связанных с нехваткой свободной памяти.
На разных этапах описываемого процесса необходимо также позаботиться о проблемах конкуренции. Следуя традиционным путем, можно было бы приобрести и удерживать защелку хэш-цепочки в библиотечном кэше в течение всего времени поиска подходящего курсора. Можно было бы создать блокировку библиотечного кэша (блокировку KGL) для кучи 0, чтобы гарантировать, невозможность выталкивания ее из памяти, или создать закрепление библиотечного кэша (закрепление KGL), чтобы исключить возможность выталкивания плана (Куча 6 / SQL Area) до окончания выполнения запроса. Однако, как вы помните, все эти защелки, связанные с библиотечным кэшем, появившиеся в 10g – такие как library cache pin allocation – закрепления и блокировки представляют собой небольшие фрагменты памяти, размещаемые в разделяемом пуле. То есть, для закрепления курсора требуется приобрести несколько защелок и выделить память. Это довольно дорого, особенно если к скорости выполнения предъявляются жесткие требования.
В Oracle реализовано множество стратегий для минимизации «инфраструктурных» затрат на поиск и выполнение инструкций. В 10.2, например, сеансы получили возможность кэширования закреплений KGL (скрытый параметр _session_kept_cursor_pins), подобную возможности кэширования дескрипторов буферов. В 11g блокировки и закрепления KGL, которые может приобрести сеанс, размещаются страницами (а не по отдельности), за счет чего снижается число запросов на выделение памяти и ее фрагментация. Помимо этих последних нововведений, сохраняется также возможность удерживать курсоры открытыми, что по сути означает удержание блокировки библиотечного кэша в течение всего времени и закрепление Кучи 0 в памяти (хотя это не закрепление KGL, в данном случае под «закреплением» подразумевается флаг, установленный диспетчером кучи). Это – функция структуры x$kgllk, официально доступной через v$open_cursor. Имеется также кэш курсоров сеанса (session cursor cache), дающий библиотечным функциям возможность удерживать курсоры открытыми, даже когда пользовательское приложение не требует этого.
Можно сделать еще один шаг вперед, сохранив закрепление (x$kglpn) в куче 6 – план выполнения – установкой параметра cursor_space_for_time в значение true (не самое лучшее решение, если оно не основано на веских причинах, потому что побочный эффект закрепления кучи 6, когда уже закреплена куча 0, ограничивает число незакрепленных воссоздаваемых объектов, которые можно освободить в случае нехватки памяти). Однако, параметр cursor_space_for_time признан устаревшим в 11g, возможно потому, что в Oracle решили, что этот параметр был решением проблемы, которая отсутствует в новейшей стратегии закрепления (реализация которой начата в 10g и близка к завершению в 11g): мьютексах.
Мьютексы
Как мне кажется, мьютексы в Oracle выполняют две функции. Прежде всего они используются в качестве защелок – мьютекс является очень маленькой структурой (примерно 24 байта) и обрабатывается очень простым кодом, включающим атомарные, непрерываемые операции для изменения значения мьютекса. То есть мьютекс можно использовать, чтобы сказать: «Мьютекс установлен в блокирующее значение – не трогайте объект X». Но мьютексы могут также использоваться как счетчики, то есть, с его помощью можно сказать: «Сейчас объект читают N пользователей – не изменяйте его».
В Oracle мьютексы были введены для защиты хэш-блоков, в частности – хэш-блоков в библиотечном кэше. Вспомните, что у нас было всего несколько защелок (от 3 до 67), охватывающих десятки тысяч хэш-блоков в библиотечном кэше. В 11.2 каждый хэш-блок получил свой мьютекс; такое решение позволило свести к минимуму конфликты за обладание защелок и устранило ложную конкуренцию (например, когда одному сеансу нужен хэш-блок с номером 1, а другому – с номером 131 071 и оба состязаются за обладание одной и той же защелкой). Это – пример использования мьютекса в роли защелки.
Примечание. Одно из важнейших отличий между мьютексами и защелками состоит в том, что Oracle всегда знает, где находятся все защелки – то есть внутренний код может накапливать информацию об использовании всех защелок. Мьютексы являются динамическими образованиями – когда сеанс создает новый дочерний курсор, он создает также новые мьютексы, как часть дочернего курсора. Это делает невозможным сбор информации об использовании всех мьютексов более или менее эффективным способом. Цена обхода связанного списка мьютексов могла бы оказаться слишком высокой, а если на мьютексы возложить задачу самим сохранять информацию в центральном пуле статистик, это привело бы к тем же самым проблемам конкуренции, для решения которых были созданы мьютексы. Поэтому мьютексы ведут только статистики, сообщающие о проблемах, которых, теоретически, должно быть не так много и тяжелых проблем с конкуренцией из-за этого не должно наблюдаться.
В этом блоге отмечалось, что мьютекс может удерживаться «продолжительное» время. Именно поэтому мьютексы могут занять место закрепления библиотечного кэша (library cache pin, x$kglpn). Перед выполнением запроса, вместо присоединения структуры к дочернему курсору, чтобы закрепить Кучу 6 в памяти, сеанс может просто увеличить значение мьютекса (выполнив атомарную машинную инструкцию), являющегося частью этого дочернего курсора, а затем уменьшить его. В теории кажется возможным точно так же заменить блокировку библиотечного кэша (library cache lock, x$kgllk) для Кучи 0, и это действительно так. Кроме того, в структуру дочернего курсора встроено два мьютекса – в действительности x$kglob (структура, являющаяся основой для представления v$sql) сообщает о трех мьютексах, но я думаю, что один из них просто является ссылкой на мьютекс хэш-блока.
Несмотря на то, что мьютексы были введены в 11g для замены механизма закреплений, структура x$kglpn никуда не делась (как и x$kgllk) и кое-где мьютексы еще не заменили закрепления. Например, если попытаться перекомпилировать процедуру PL/SQL в то время, как она выполняется, можно увидеть, что сеанс ожидает освобождения library cache pin. Возможно, вам интересно будет провести один стандартный тест, который я выполняю после обновления. Он заключается в том, чтобы скомпилировать и выполнить следующую хранимую процедуру:
create or replace procedure self_deadlock as begin execute immediate ‘alter procedure self_deadlock compile’; end; /
Однажды вы можете обнаружить, что блокировки и закрепления просто исчезли из библиотечного кэша. Однако, имеются изменения и другого рода, коснувшиеся узких мест в механизмах распределения памяти и создания защелок, вообще устранившие потребность в блокировках и закреплениях. В 11g (и даже в 10g) сеанс один раз приобретает большой фрагмент памяти и затем создает в нем блокировки и закрепления, благодаря этому устраняется конкуренция за доступ к разделяемой памяти.
В заключение
Сравнивая кэш буферов с разделяемым пулом, можно заметить, что им свойственны похожие проблемы, имеющие похожие пути решения. Своим назначением и поведением защелка цепочек LRU в кэше буферов похожа на защелку разделяемого пула. Точно так же имеются сходства между защелками цепочек в кэше буферов и защелками в библиотечном кэше.
Защелка разделяемого пула контролирует перемещение памяти из пула свободных фрагментов в пул занятых фрагментов, включая фрагменты в список LRU и исключая из него. Защелка цепочек LRU в кэше буферов также контролирует перемещение буферов между вспомогательным (с давно использовавшимися блоками) и основным (с недавно использовавшимися блоками) списками. Защелки в библиотечном кэше упорядочивают доступ к коду и метаданным объектов в соответствии с их хэш-значениями, и защелки цепочек в кэше буферов также упорядочивают доступ к блокам данных по их хэш-значениям.
Разумеется, имеются отличия в числе защелок и особенностями их использования, а также применяются разные стратегии закрепления и использования элементов. Так как кэш буферов (или, по крайней мере, каждый рабочий набор данных) работает с фрагментами памяти одного размера, управлять памятью в кэше буферов проще, чем в разделяемом пуле, где память может выделяться фрагментами практически любого размера. Из соображений производительности, в разделяемом пуле реализовано несколько списков свободных фрагментов (тогда как в кэше буферов имеется единственный вспомогательный список) и применяются разные стратегии минимизации фрагментации памяти.
Всегда рассматривайте парсинг и оптимизацию, как две отдельные операции. И помните о различиях между вызовами парсера и операцией парсинга.
Оптимизация является дорогостоящей процедурой, парсинг может быть дорогостоящей процедурой – в системах OLTP, где большую часть составляют легковесные запросы, возвращающие небольшие объемы данных, избегайте конструирования инструкций SQL путем конкатенации литеральных значений, потому что стоимость выполнения таких запросов выше.
Вызов парсера в вашем коде может:
- вообще ничего не сделать – особенно в коде PL/SQL;
- выполнить проверку синтаксиса, произвести поиск в библиотечном кэше, провести семантический анализ и оптимизацию;
- выполнить проверку синтаксиса и перейти к нужному курсору (в кэше курсоров сеанса);
- ничего не сделать и сразу перейти к нужному курсору (если имеется в кэше PL/SQL).
Для парсинга и оптимизации новой инструкции SQL Oracle должен посетить (и, возможно, загрузить) кэш словаря, для чего необходимо приобрести защелку кэша словаря и, возможно, выполнить некоторые операции с разделяемым пулом, чтобы выделить фрагмент памяти. Более того, при загрузке инструкции и курсора в библиотечный кэш, может потребоваться выполнить дополнительные операции с разделяемым пулом, чтобы вытеснить из памяти какие-либо объекты и объединить смежные фрагменты.
Несмотря на то, что оптимизация и кэширование призваны минимизировать стоимость выполнения, иногда вызовов парсера может оказаться полезным, особенно в высоконагруженных системах OLTP, когда ради уменьшения конфликтов имеет смысл явно создать и удерживать курсор, пусть и ценой усложнения кода.
