 Настройка экземпляра главным образом производится администраторами баз данных в ответ на снижение производительности базы данных Oracle. В этой статье блога будет описано, как приступить к анализу экземпляра для выяснения того, где скрывается проблема.
Настройка экземпляра главным образом производится администраторами баз данных в ответ на снижение производительности базы данных Oracle. В этой статье блога будет описано, как приступить к анализу экземпляра для выяснения того, где скрывается проблема.
Перед этим, однако, необходимо проанализировать показатели по использованию всех главных ресурсов, наподобие памяти, ЦП и подсистемы хранения, получив уверенность в том, что база данных работает медленно не из-за образования узких мест в этих критически важных областях.
На заметку! Сбор данных базовой линии по статистическим показателям базы данных, в том числе и событиям ожидания, очень важен для выявления и устранения проблем с производительностью. Наличие данных базовой линии позволяет сразу же проверить, соответствуют ли текущие схемы использования ресурсов объему нагрузки на систему.
Анализ происходящего в базе данных Oracle
Нередко SQL-запрос одного единственного пользователя способен вызывать ухудшение производительности в масштабах всего экземпляра, если он довольно плохо составлен. SQL-операторы исполняют центральную роль во всей работе базы данных, поэтому сначала следует проанализировать, что происходит в базе данных прямо в текущий момент. Ниже перечислены некоторые ключевые вопросы, на которые потребуется получить ответы.
- Какие пользователи идут первыми в списке Top Sessions?
- Какие точно SQL-операторы выполняют эти пользователи?
- Не является ли количество пользователей необычно большим по сравнению с показателями базовой линии за такой же период времени?
- Не является ли нагрузка на базу данных выше той, что должна быть согласно показателям базовой линии за такое же время дня, недели или месяца?
- Какие важные события ожидания отображаются в представлении V$SESSION или V$SESSION_WAIT. Эти работающие в режиме реального времени представления отображают события ожидания, которые либо происходят в экземпляре прямо сейчас, либо только что произошли. Способы выявления фактических пользователей, ответственных за те или иные события ожидания, посредством других представлений V$ рассматривались ранее в этой статье.
Другой важный вопрос состоит в том, возникла ли испытываемая сейчас проблема с производительностью внезапно безо всяких предварительных предпосылок или же постепенно в результате усугубления определенных факторов. Под такими факторами подразумеваются вещи наподобие разрастания базы данных, увеличения количества пользователей и повышения числа DML-операций обновления по сравнению с тем, на которые изначально рассчитывалась система. Проблемы подобного рода могут требовать перепроектирования, как минимум, некоторых таблиц и индексов с использованием для них других параметров хранения и прочих параметров, вроде списков свободных блоков (freelists). Если же, с другой стороны, работа базы данных замедлилась внезапно, тогда внимание понадобится сфокусировать на отдельном ряде элементов.
Лучший способ для проведения анализа того, что происходит в базе данных в текущий момент, предусматривает применение ASH. С помощью запроса к представлению V$ACTIVE_SESSION_HISTORY, о котором более подробно рассказывалось в блоге, в разделе “Использование представления V$ACTIVE_SESSION_HISTORY”, легко выяснить, какие пользователи, объекты и SQL-операторы вызывают в экземпляре ожидания. Можно также сгенерировать быстрый отчет ASH, охватывающий лишь последние несколько минут, и узнать, где в системе могут присутствовать узкие места и по чьей вине.
Совет. В OEM Database Control предлагается мастер Gather Statistics Wizard (Мастер сбора статистики), которым можно пользоваться в случае появления проблем с производительностью из-за устаревших статистических данных по фиксированным и словарным объектам.
Применение интерфейса OEM Database Control для изучения показателей по производительности базы данных
Интерфейсы OEM Database Control и OEM Grid Control подробно рассматривались в наших блогах. Знать обо все различных представлениях VS$, касающихся событий ожидания и производительности, несомненно, полезно, но ничто не может сравниться с интерфейсом Database Control по возможности быстрого выяснения того, что конкретно происходит в базе данных в любой момент времени. Ниже я опишу простой подход к использованию различных страниц Database Control, связанных с производительностью.
Домашняя страница Database Control
Начинать анализ следует с просмотра трех перечисленных ниже диаграмм производительности на домашней странице Database Control. На рис. 20.2 показано, как выглядит эта страница.
Диаграмма Host CPU
Потребление ресурсов ЦП на хост-сервере отображается в виде столбчатой диаграммы Host CPU (ЦП хоста). Эта диаграмма состоит из двух категорий: instance (экземпляр) и other (другие), в которой отображается информация обо всех процессах, не принадлежащих экземпляру базы данных.
Диаграмма Active Sessions
Диаграмма Active Sessions (Активные сеансы) является ключевой, поскольку отражает количество связанных с производительностью узких мест в экземпляре базы данных.
")
Рис. 2. Диаграмма Active Sessions (Активные сеансы)
Она состоит из трех компонентов:
- CPU (ЦП)
- User I/O (Пользовательский ввод-вывод)
- Wait (События ожидания)
Другими словами, она отражает потребляемое время в виде трех категорий: CPU, User I/O и Wait. Каждую из этих категорий можно изучить более подробно, щелкнув на соответствующей ссылке. Обратите внимание, что категория Wait включает в себя все события ожидания в экземпляре, кроме тех, которые связаны с пользовательскими операциями ввода-вывода, потому что они отображаются в отдельной категории.
Диаграмма SQL Response Time
Диаграмма SQL Response Time (Время отклика SQL) позволяет получать быстрое представление о том, насколько эффективно в экземпляре выполняются SQL-операторы. Если текущий коэффициент отклика SQL превышает коэффициент базовой линии, составляющий 100%, тогда, значит, SQL-операторы выполняются медленнее, чем “обычно”. Низкий процент отклика в диаграмме SQL Response Time свидетельствует о том, что обработка SQL-операторов в экземпляре происходит неэффективно.
На заметку! В базах данных версий, предшествующих Oracle Database 10g, может понадобиться настроить определенные вещи для того, чтобы метрические показатели активности отображались в диаграмме SQL Response Time. Для этого используется мастер Database Configuration, вызвать который можно, щелкнув на кнопке Configure (Настройка) напротив SQL Activity Monitoring (Мониторинг активности SQL) в разделе Diagnostic Summary (Диагностическая сводка).
Использование данных анализа ADDM в разделе Performance Analysis
В разделе Performance Analysis (Анализ производительности) домашней страницы Database Control отображаются суммарные данные самого недавнего анализа ADDM.
На рис. 3 показано, как выглядит этот раздел. В этом разделе можно щелкать на любых полученных сведениях и тем самым анализировать любые связанные с производительностью проблемы более детально. Отчеты ADDM, в которых используются статистические данные AWR, позволяют быстро производить нисходящий анализ активности экземпляра.
 страницы Database Control")
Рис. 3. Performance Analysis (Анализ производительности) страницы Database Control
Использование страницы Database Performance
Страница Performance (Производительность) является, можно сказать, отправной точкой для проведения анализа производительности экземпляра. Она помогает делать следующие вещи.
- Выполнять проверку на предмет наличия проблем как в базе данных, так и в системе.
- Запускать процесс генерации отчета ASH для получения быстрого диагностического отчета по производительности на основании выборочных данных сеансов.
- Быстро узнавать, какие узкие места существуют в системе.
- Генерировать отчеты ADDM.
- Переходить в режим Memory Access Mode (Режим доступа к памяти) в случае замедления или зависания системы.
Использование режима Memory Access Mode
Страницу Performance можно просматривать как в предлагаемом по умолчанию режиме SQL Access Mode (Режим доступа к SQL), так и в новом режиме Memory Access Mode. Режим SQL Access Mode подразумевает получение данных по производительности экземпляра за счет применения специальных SQL-операторов, которые по большей части выполняют запросы к динамическому представлению производительности V$. Однако, когда база данных работает чрезвычайно медленно или вообще зависла, применение режима SQL Access Mode накладывает на нее дополнительную нагрузку из-за необходимости дополнительно анализировать и выполнять SQL-операторы интерфейса OEM для диагностики производительности экземпляра. Если в экземпляре уже происходят интенсивные состязания за библиотечный кэш, попытка диагностировать проблему в таком режиме лишь усугубит ситуацию.
Поэтому для проведения диагностики в медленно работающих или зависших системах Oracle рекомендует переключаться в режим Memory Access Mode. При таком режиме база данных получает диагностические сведения прямо из SGA, используя более легкие системные вызовы, а не ресурсоемкие SQL-операторы, которые применяются при режиме SQL Access Mode. Благодаря тому, что в режиме Memory Access Mode выборка данных производится чаще, еще и снижается вероятность упущения событий, которые длятся короткое время. На рис. 4 показано, как можно переключаться в режим Memory Access Mode.

Рис. 4. Переключение в режим Memory Access Mode
В следующих разделах рассматриваются основные диаграммы, отображаемые на странице Performance.
Диаграмма Host
Диаграмма Host (Хост) отражает проблемы, связанные с использованием ЦП. Если количество пользователей небольшое, а в этой диаграмме отображается длинная очередь выполнения, значит, пользователи базы данных, скорее всего, являются не главными виновниками высокого потребления ресурсов ЦП. В таком случае потребуется выяснить, что еще может работать в системе и потреблять ресурсы ЦП.
Диаграмма Average Active Sessions
Диаграмма Average Active Sessions (Средний объем активных сеансов) отражает имеющиеся в экземпляре проблемы с производительностью, уделяя основное внимание происходящим в экземпляре событиям ожидания. Она является ключевой на странице Performance и должна служить отправной точкой при выполнении анализа производительности с помощью OEM. На рис. 20.5 приведен пример того, как она может выглядеть. В этом примере видно, что она показывает, какие активные сеансы ожидают ресурсов ЦП, а какие ожидают событий.

Для удобства диаграмма Average Active Sessions имеет цветовую кодировку. Зеленый цвет представляет тех пользователей, которые используют ресурсы ЦП, а остальные цвета — пользователей, которые ожидают различных событий, наподобие дискового ввода-вывода, блокировок или сетевых подключений. Определять, что в экземпляре происходит слишком много ожиданий, можно так: если уровень ожиданий в два раза превышает линию Max CPU (Максимальное использование ЦП), значит, в экземпляре возникает слишком много событий ожидания и потому его следует настроить.
Справа от диаграммы Average Active Sessions отображается классификация компонентов, оказывающих влияние на время длительности сеансов. Например, увидев в диаграмме, что больше всего ожиданий происходит из-за пользовательских операций ввода-вывода, можно щелкнуть в этой классификации на компоненте с соответствующим названием и узнать больше об этих ожиданиях. Над классификацией отображаются кнопки (см. рис. 20.5), на которых можно щелкать для запуска ADDM или получения отчета ASH.
Вдобавок можно щелкать на ссылке для перехода на страницу Top Activity (Наибольшая активность) и получать детали по тем сеансам, которые больше всех ответственны за происходящие в экземпляре ожидания в текущий момент. На рис. 6 показан пример того, как может выглядеть страница Top Activity в Database Control. Данные по активности базы отображаются в виде двух разделов: Top SQL (Самые интенсивные SQL-операторы) и Top Sessions (Самые активные сеансы). Из раздела Top SQL можно запускать советника SQL Tuning Advisor и получать рекомендации по настройке самых интенсивных SQL-операторов.
При наличии подозрений в том, что какой-то отдельный сеанс страдает от ожиданий, или при получении от определенных пользователей жалоб о том, что их сеансы выполняются слишком медленно, необходимо изучить страницу Top Sessions. Перейти на эту страницу можно, выполнив на странице Performance щелчок на ссылке Top Sessions в разделе Additional Monitoring Links (Дополнительные ссылки мониторинга). После попадания на страницу Top Sessions нужно щелкнуть на представляющем интерес имени пользователя и идентификаторе сеанса (SID) для отображения страницы Session Details (Детали сеанса) данного сеанса. Перейдя на вкладку Wait Event History (Хронология событий ожидания), можно легко выяснить природу последних ожиданий в этом сеансе. На рис. 7 показан пример страницы Session Details.

Рис. 6. Страница Top Activity в Database Control
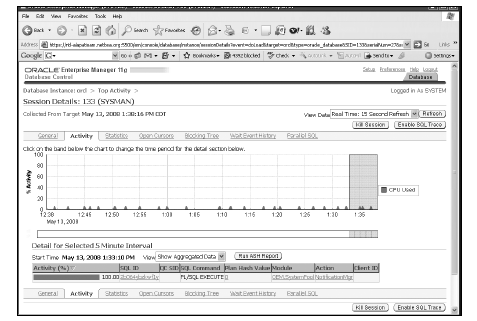
Рис. 7. Пример страницы Session Details
Страница Performance Data Report Page
Перейти на страницу Performance Data Report (Отчет по данным о производительности) можно, щелкнув на кнопке Create ASH Report (Создать отчет ASH) в разделе Average Active Sessions на домашней странице Performance в Database Control. Отчеты AWR хорошо подходят для анализа производительности экземпляра, но обычно подразумевают сбор данных за 30-минутные или часовые интервалы времени. Трех- или четырехминутный всплеск в производительности может запросто не попасть в агрегированный отчет AWR. Отчеты ASH предполагают выборку данных сеансов за недавний период времени.
После щелчка на кнопке Create ASH Report предлагается выбрать период времени, за который требуется создать отчет ASH. Выбираемый период не должен выходить за рамки последних семи дней, поскольку именно столько хранятся статистические данные ASH. Не следует забывать о том, что хранятся эти статистические данные ASH в репозитории AWR. На рис. 8 показан пример отчета ASH, созданного на основе представления V$ACTIVE_SESSION_HISTORY.

Рис. 8. Отчет ASH по представлению V$ACTIVE_SESSION_HISTORY
Он представляет собой точно такой же отчет ASH, который можно создавать с помощью сценария ashrpt.sql. В нем содержится информация о следующих элементах:
- самые интенсивные события (Top Events);
- диаграмма загрузки (Load Profile);
- самые интенсивные SQL-операторы (Top SQL);
- самые активные сеансы (Top Sessions), в том числе и наиболее страдающие от блокировки (Top Blocking Sessions).
- другие сущности, вызывающие в экземпляре состязания за ресурсы, а именно — самые интенсивно используемые объекты базы данных (Top Database Objects), самые интенсивно используемые файлы базы данных (Top Database Files) и самые интенсивно используемые защелки (Top Latches).
- активность за определенный период времени (Activity Over Time).
Выявление долго выполняющихся транзакций
Для выяснения того, какие SQL-операторы в экземпляре выполняются дольше всего и потребляют больше всего ресурсов, можно использовать представление V$SQL, как показано в следующем примере. В этом примере транзакции ранжируются по общему количеству затраченных на их выполнение секунд. Однако их также можно ранжировать и по количеству только использованных на их выполнение секунд ЦП.
SQL> SELECT hash_value, executions, 2 ROUND (elapsed_time/1000000, 2) total_time, 3 ROUND (cpu_time/1000000, 2) cpu_seconds 4 FROM (SELECT * FROM V$SQL 5 ORDER BY elapsed_time desc); HASH_VALUE EXECUTIONS TOTAL_TIME CPU_SECONDS ---------- ---------- ---------- ----------- 238087931 168 9.51 9.27 1178035321 108 4.98 5.01 . . . SQL>
После получения хеш-значения (HASH_VALUE) с помощью такого запроса, далее останется просто выяснить, как выглядит план выполнения данного оператора, который хранится в библиотечном кэше. Просмотреть план выполнения самых долгих SQL-операторов можно посредством запроса к представлению V$SQL_PLAN:
SQL> SELECT * FROM V$SQL_PLAN WHERE hash_value = 238087931;

Заключается ли проблема в Oracle
Только из-за того, что пользователи жалуются на медленную работу базы данных, не следует торопиться делать вывод о том, что проблема заключается в базе данных. В конце концов, база данных не работает сама по себе: она функционирует на сервере и, следовательно, на ее производительности могут сказываться ограничения по ресурсам и узкие места, присутствующие на этом сервере. Если не работающие с Oracle пользователи используют на этом сервере все критически важные ресурсы наподобие вычислительных ресурсов ЦП и дисковых ресурсов ввода-вывода, база данных может быть просто жертвой обстоятельств и тогда необходимо искать ответы за ее пределами. Именно поэтому для администраторов баз данных так важно знать, каким образом измерять общую производительность системы, в том числе производительность памяти, дисковой подсистемы хранения, сети и процессоров. В следующих разделах описываются системные ресурсы, на которые необходимо обращать особое внимание.
Все ли в порядке с сетью
Первое, что нужно делать при анализе причин замедления работы базы данных — это исключать проблемы с сетью. Довольно часто пользователи жалуются на невозможность подключения к системе или частые внезапные разрывы соединения с ней. В таком случае необходимо проверить показатели по времени круговой передачи пакетов (round-trip ping times) и количеству конфликтов (collisions) и заставить администратора сети проверять подключения к Интернету и маршрутизаторы.
На стороне Oracle для выяснения того, не вызвано ли замедление в работе базы данных какой-то проблемой с сетью, можно заглянуть в описанные далее динамические представления. Представление V$SESSION_EVENT показывает, сколько в среднем времени уходит у Oracle на ожидание между сообщениями, а представление V$SESSION_WAIT, как уже упоминалось — чего именно ожидает сеанс и не является ли показатель по ожиданиям, связанным с передачей сообщений по сети, выше обычного.
Если на круговую пересылку SQL уходит чрезвычайно много времени, это может проявляться в представлениях V$ в виде высокого показателя по количеству времени ожидания, связанного с сетью. В таком случае необходимо проверить, не увеличилось ли значительно время круговой передачи пакетов по сети и посоветоваться с сетевым администратором касательно того, что можно сделать для сокращения ожиданий, связанных с трафиком.
Можно рассмотреть вариант установки в файле sqlnet.ora параметра TCP, NODELAY=TRUE, который вынуждает TCP отправлять пакеты без ожидания и, следовательно, увеличивает время отклика для работающих в реальном времени приложений.
Если кажется, что сеть представляет собой одно из постоянных узких мест, может быть, для подключения пользователей к базе данных лучше применять разделяемый, а не выделенный сервер. За счет использования разделяемого сервера и поддерживаемой им возможности организации пулов соединений можно значительно сократить количество физических сетевых соединений и, следовательно, помочь приложению более эффективно подстраиваться под большое количество пользователей.
Не ограничивают ли производительность системы возможности ЦП
Чтобы удостовериться в том, что никакой неконтролируемый или действительный процесс Oracle не пожирает все ресурсы одного или нескольких процессоров и тем самым не служит причиной замедления работы системы, необходимо проверять производительность ЦП. Зачастую уничтожение неконтролируемых процессов или потребляющих слишком много ресурсов сеансов приводит вещи в норму. С использованием OEM Database Control можно быстро оценить объемы использования ЦП для синтаксического анализа, рекурсивных вызовов и других операций.
Обычно процент использования ЦП самой системой должен составлять не более 20–25%, а приложением Oracle — около 60–65%. Если показатель по использованию ЦП системой достигает 50%, это может свидетельствовать, например, о наличии слишком большого количества системных вызовов, которые и приводят к чрезмерному расходованию ресурсов ЦП.
Представление V$SESSTAT показывает, как ресурсы ЦП распределяются между сеансами. Поэтому с помощью показанного ниже запроса можно легко выявить сеансы в Oracle, которые потребляют больше всего ресурсов ЦП. При желании можно также просматривать и сам SQL-код, который выполняется в этих сеансах.
SQL> SELECT a.sid,a.username, s.sql_text FROM V$SESSION a, V$SQLTEXT s WHERE a.sql_address = s.address AND a.sql_hash_value = s.hash_value AND a.username = '&USERNAME' AND A.STATUS='ACTIVE' ORDER BY a.username,a.sid,s.piece;
Не испытывает ли система проблем с вводом-выводом
Прежде чем двигаться дальше и анализировать другие события ожидания, стоит выяснить, не заключается ли проблема в подсистеме хранения, посмотрев, как обстоят дела с вводом-выводом. Находятся ли показатели по времени чтения и записи в серверной системе в пределах нормы? Равномерно ли распределяются операции ввода-вывода, или же есть горячие точки, в которых один или несколько дисков подвергаются этим операциям слишком интенсивно? Если обычный хороший показатель составляет 40–50 операций ввода-вывода в миллисекунду, а в текущий момент этот показатель достигает 80 операций ввода-вывода в миллисекунду, очевидно, что-то не так. Отчеты AWR и ASH включают в себя информацию о времени, которое затрачивается на ввод-вывод (дисковое чтение и запись) на уровне файлов данных. Обычно эта информация подсказывает, что может служить причиной всплеска. Например, если в списке высоких коэффициентов ввода-вывода часто фигурируют файлы данных из временных табличных пространств, это обычно является признаком того, что операции сортировки выполняются не в памяти, а на диске, и требует более глубокого анализа.
С помощью представления V$SYSTEM_EVENT можно выяснить, не входят ли в число самых активных событий ожидания такие события, как db file scattered read, db
file sequential read, db file single write и Logfile parallel write, которые представляют собой события ожидания, связанные с файлами базы данных, файлами журналов и файлами журналов повторного выполнения. Сгенерировав отчет AWR, можно определить, какие табличные пространства и файлы данных вызывают состязания за ресурсы подсистемы ввода-вывода. Выполнив запрос к представлению V$SQLAREA, можно выявить те SQL-операторы, которые приводят к многочисленным операциями чтения с диска и настроить их так, чтобы они этого не делали.
Довольно часто всплески в показателях по вводу-выводу может вызывать какая- нибудь выполняющаяся в дневное время пакетная программа. Администратору баз данных нужно стараться делать так, чтобы подсистема ввода-вывода не представляла собой узкое место. Признаком чрезвычайной загруженности подсистемы ввода-вывода может служить возникновение в базе данных Oracle нескольких типов событий ожидания, подобных db file sequential read и db file scattered read. Если в среднем на ожидание любого из этих связанных с вводом-выводом событий уходит приличное количество времени, следует сфокусировать внимание на улучшении ситуации с подсистемой ввода-вывода. Для увеличения пропускной способности подсистемы ввода-
вывода можно сделать две вещи: сократить рабочую нагрузку на эту подсистему и увеличить ее пропускную способность.
Улучшение SQL-операторов — это нечто такое, что не может происходить сразу же, поэтому для улучшения состояния дел в таком случае, т.е. для увеличения пропускной способности подсистемы ввода-вывода необходимо сделать еще кое-что:
- удостовериться, что ключевые объекты базы данных, которые используются наиболее интенсивно, равномерно распределены по дискам;
- увеличить количество дисков.
Объемы дисков становятся все больше и больше, но средства ввода-вывода пока не совсем успевают за ними. Поэтому серверы довольно часто испытывают проблемы с вводом-выводом в средах с крупными базами данных. Новые технологии, наподобие кэширования файлов, могут быть одним из решений для устранения таких проблем. В среднем около 50% активности подсистемы ввода-вывода приходится на менее чем 5% из всех файлов данных в базе, поэтому кэширование этого небольшого количества особо интенсивно используемых файлов должно значительно облегчать дело. Главное преимущество кэширования состоит в том, что оно обеспечивает возможность выполнения операций чтения и записи со скоростью памяти, которая может в 200 раз превышать скорость диска. В частности, к числу файлов, которые можно помещать в файловый кэш для ускорения связанных с ними операций ввода-вывода относятся временные файлы, файлы журналов повторного выполнения, файлы табличных пространств отката, а также файлы данных наиболее часто используемых таблиц и индексов.
Еще бывает, что большие сегменты тратят много дискового пространства зря из-за фрагментации, которая появляется со временем в результате выполнения операций обновления и удаления. Такая фрагментация пространства тоже может приводить к серьезному ухудшению производительности. С помощью утилиты Segment Advisor (Советник по сегментам) легко выяснить, какие объекты являются кандидатами на освобождение места из-за чрезмерной фрагментации данных внутри сегмента.
Не является ли нагрузка на базу данных слишком высокой
При наличии показателей базовой линии по нагрузке на базу данных, можно проверять, не является ли текущая нагрузка слишком высокой по сравнению с ними. К числу данных, на которые следует обращать особое внимание и которые можно получать из представления V$SYSSTAT, относятся данные о количестве физических операций чтения и записи, данные о размере журналов повторного выполнения, данные о количестве операций полного и частичного синтаксического анализа и данные о вызовах пользователей. Кроме того, в разделе Load Profile (Профиль нагрузки) отчета AWR можно узнать, после каких транзакций или какого времени нагрузка приходила обратно в норму.
Проверка на предмет наличия проблем с памятью
Высокие коэффициенты попаданий в кэш буферов и разделяемый пул не гарантируют эффективной производительности экземпляра. В некоторых случаях чрезмерная обеспокоенность коэффициентами попадания может приводить к выделению слишком большого объема памяти для Oracle, ведущего к появлению серьезных проблем вроде страничного обмена и подкачки на уровне операционной системы. Поэтому нужно обязательно проверять, не выглядят ли необычно показатели по страничному обмену и подкачке. Большое количество операций страничного обмена и подкачки тормозит все, в том числе и работу всех функционирующих на этом сервере баз данных.
Из-за того, что в большинстве операционных систем используется подсистема виртуальной памяти, определенное количество операций страничного обмена является нормальным и ожидаемым. Если физической памяти не хватает для удовлетворения спроса в памяти, операционная система обратится к диску для использования виртуальной памяти, а это ведет к возникновению страничной ошибки. Процессы, сопровождаемые большим количеством таких ошибок, будут выполняться медленно.
При выделении памяти для Oracle следует обращать должное внимание на выделение памяти для PGA, особенно в среде типа DSS. Базы данных, в которых выполняется большое количество интенсивных операций сортировки и хеширования, нуждаются в выделении большого объема памяти для PGA. База данных самостоятельно подстраивает размер PGA, но для того, чтобы она могла это делать, все равно необходимо проверять, чтобы значение pga_aggregate_target было достаточно высоким.
Совет. В отличие от SGA, память, выделяемая для PGA, не отдается немедленно и навсегда базе данных Oracle. Базе данных Oracle разрешено использовать память PGA вплоть до предела, заданного в параметре PGA_TARGET. После завершения выполнения задания пользователя, память, использовавшаяся для его выполнения, возвращается обратно операционной системе. Поэтому не стоит бояться устанавливать для параметра инициализации PGA_TARGET высокое значение. Применение высокого значения не влечет за собой никаких негативных последствий и гарантирует, что экземпляр не будет страдать от выполнения ненужных операций сортировки и хеширования на диске.
Еще необходимо проверить, нельзя ли завершить какие-нибудь процессы из списка Top Sessions, которые, похоже, потребляют необычно большое количество памяти. Вполне вероятно, что некоторые из этих процессов являются зависшими или неконтролируемыми.
Правильный ли размер имеют журналы повторного выполнения
Если журналов повторного выполнения слишком мало или если их размер является недостаточно большим по сравнению с объемом DML-активности в базе данных, процессу архивирования придется усиленно работать над архивированием заполненных файлов журналов повторного выполнения. Это чревато замедлением работы экземпляра. Лучше изменить размер журналов повторного выполнения или добавить дополнительные группы таких журналов. При использовании параметра FAST_START_MTTR_TARGET для установки потолка по времени восстановления экземпляра, Oracle будет создавать контрольную точку настолько часто, насколько необходимо, для гарантии того, что экземпляр удастся восстановить после отказа в пределах заданного в параметре MTTR времени. Во избежание создания излишних контрольных точек нужно обязательно проверить, достаточно ли большой размер журналов повторного выполнения. Узнать, какой размер является оптимальным для журналов повторного выполнения, можно по значению столбца OPTIMAL_LOGFILE_SIZE в представлении V$INSTANCE_RECOVERY. Для получения совета по размерам журналов повторного выполнения можно воспользоваться предлагаемой в Database Control страницей Redo Log Groups (Группы журналов повторного выполнения). Как правило, Oracle рекомендует делать размер файлов журналов таким, чтобы они переключались каждые 20 минут.
Не испытывает ли система проблем, связанных с событиями ожидания
Если ни один из предыдущих шагов не выявил никаких проблем, скорее всего, система страдает от серьезного состязания за какой-нибудь ресурс, например, за защелки библиотечного кэша. Поэтому не помешает выполнить проверку на предмет наличия состязаний за критически важные ресурсы базы данных вроде блокировок и защелок. Например, синтаксический анализ похожих SQL-операторов влечет за собой чрезмерное потребление ресурсов ЦП и влияет на производительность экземпляра тем, что увеличивает состязания за библиотечный кэш или разделяемый пул. Присутствие состязаний за ресурсы проявляется в виде событий ожидания. Анализе событий ожидания было предоставлено подробное объяснение различных критически важных событий ожидания. Для получения информации о самых интенсивных (top) событиях ожидания, можно использовать отчеты AWR и ASH.
Представление V$SESS_TIME_MODEL (и V$SYS_TIME_MODEL) помогает узнать суммарное время, затраченное на выполнение различных операций в базе данных на уровне отдельных сеансов. Оно позволяет точно понять, где было потрачено больше всего времени ЦП. В наших блогах можно прочесть, что в представлении V$SESS_TIME_MODEL, помимо всего прочего, содержатся следующие столбцы:
- DB time, в котором отображается время БД, потраченное на выполнение вызов пользователей;
- DB CPU, в котором отображается количество времени ЦП, потраченное на выполнения вызовов пользователей;
- Background CPU time, в котором отображается количество времени ЦП, потраченное на выполнение фоновых процессов;
- Hard parse elapsed time, в котором отображается количество времени, потраченное на выполнение полного синтаксического анализа SQL-операторов;
- PL/SQL execution elapsed time, в котором отображается количество времени, потраченное на работу интерпретатора PL/SQL;
- Connection management call elapsed time, в котором отображается количество времени, потраченное на выполнение вызовов на подключение и отключение сеансов.
С помощью данных по сегментам из представления V$SEGMENT_STATISTICS можно выявить “горячие” сегменты в таблицах и индексах, вызывающие определенный тип событий ожидания, и сфокусироваться на устранении (или хотя бы сокращении) этих событий.
Использование отчета Compare Periods Report
Предположим, что возникла следующая ситуация: выполнение одного из ключевых еженощных пакетных заданий стало выходить за пределы выделенного для него окна и продолжать протекать в дневное время, тем самым угрожая производительности оперативных OLTP-запросов. Точно известно, что раньше выполнение этого задания заканчивалось в пределах отведенного времени, но теперь на него почему-то уходит гораздо больше времени. Начиная версии Oracle Database 10g Release 2, появилась возможность сравнивать изменения в ключевых метрических показателях базы данных между двумя интервалами времени с помощью предлагаемого в Database Control средства Compare Periods Report (Отчет по сравнению периодов). Как уже известно, снимок AWR захватывает информацию между двумя точками во времени. С использованием средства Time Periods Comparison (Сравнение периодов времени) можно изучать отличия в метрических показателях базы данных между двумя разными интервалами или периодами времени путем анализа статистических данных по производительности, зафиксированных в двух наборах снимков AWR. То есть если еженощное пакетное задание во вторник выполнялось нормально, а в среду — медленно, с помощью Compare Periods Report можно легко выяснить, почему так получилось.
Необходимые для этого шаги перечислены ниже.
- На домашней странице Database Control перейдите на вкладку Performance (Производительность).
- В разделе Additional Monitoring Links (Дополнительные ссылки для мониторинга) щелкните на ссылке Snapshots (Снимки).
- В раскрывающемся списке Actions (Действия) выберите действие Compare Periods (Сравнить периоды) и щелкните на кнопке Go (Начать).
- Появится страница Compare Periods: First Period End (Сравнение периодов: Конец первого периода). На этой странице нужно указать начальное время для проведения сравнительного анализа, выбрав идентификатор конечного снимка за первый период. При желании здесь также можно выбрать период времени вместо идентификатора конечного снимка. По завершении щелкните на кнопке Next (Далее).
- Далее появится страница Compare Periods: Second Period Start (Сравнение периодов: Начало второго периода). Выберите идентификатор снимка, обозначающего начало второго периода, и щелкните на кнопке Next.
- Потом появится страница Compare Periods: Second Period End (Сравнение периодов: Конец второго периода). Выберите конечный снимок для второго периода и щелкните на кнопке Next.
- После этого появится страница Compare Periods: Review (Сравнение периодов: Обзор) с идентификаторами начального и конечного снимка для первого и второго периода, как показано на рис. 9. Удостоверьтесь в том, что диапазоны периодов выглядят правильно, и щелкните на кнопке Finish (Готово).
")
Рис. 9. Страница Compare Periods: Review (Сравнение периодов: Обзор)
- И, наконец, появится страница Compare Periods: Results (Сравнение периодов: Результаты) с суммарными сведениями об отличиях, обнаруженные в метрических показателях базы данных между двумя указанными периодами.
Просмотр отличий в ключевых метрических показателях базы данных между двумя периодами поможет выявить основные причины снижения производительности в более позднем периоде по сравнению с более ранним “хорошим” периодом. Также можно просмотреть и отличия в конфигурации базы данных между двумя этими периодами.
Чтобы сравнить два периода детальным образом и углубленно изучить различные элементы, вроде выполнявшихся SQL-операторов, объема использования SGA и т.д., нужно щелкнуть на ссылке Report (Отчет) внутри страницы Compare Periods: Results. После этого появится удобно отформатированный отчет, сравнивающий два периода по конфигурации, пяти самым длительным по времени событиям и профилю нагрузки. Просмотр этих различных статистических данных по двум периодам позволит определить, не наблюдалась ли во время второго периода чрезмерная нагрузка или что-нибудь подобное.
В нижней части отчета будет отображаться раздел Report Details (Детали отчета) со ссылками на различные элементы, такие как события ожидания, статистические данные по вводу-выводу, статистические данные по сегментам и статистические данные по использованию SGA. Щелчок на любой из этих ссылок поможет детально посмотреть, что конкретно происходило внутри базы данных на протяжении двух данных периодов. Например, выполнение щелчка на ссылке SQL Statistics (Статистические данные по SQL) позволяет получить сведения о десяти самых интенсивных SQL-операторах и сравнить их по времени выполнения, времени использования ЦП, количеству произведенных операций buffer gets, количеству произведенных операций physical reads и т.д. На рис. 10 показан пример сравнения десяти самых интенсивных SQL-операторов по количеству произведенных во время каждого периода операций physical reads.

Рис. 10. Сравнение SQL-операторов по количеству операций physical reads
Устранение состязаний за ресурсы
После выявления событий ожидания, возникающих из-за состязаний за какие-то ресурсы системы, необходимо устранить это узкое место. Конечно, это легче сказать, чем быстро сделать. Одни связанные с состязаниями за ресурсы проблемы может получиться удалить сразу же, а на другие — требоваться больше времени. Проблемы наподобие высокого показателя по событиям ожидания db file scattered read, которые происходят из-за выполнения полного сканирования таблиц, могут свидетельствовать о необходимости сократить связанную с вводом-выводом нагрузку на систему. Однако если сокращение такой нагрузки требует создания новых индексов и переписывания SQL-операторов, очевидно, что устранить проблему сразу же не получится. Добавлять диски и переорганизовывать объекты для немедленного сокращения “горячих точек” тоже нельзя. Аналогичным образом, состязания за защелки в большинстве ситуаций требуют внесения изменений на уровне приложения. Главное — не вносить все изменения сразу, иначе так никогда не получится узнать, что помогло устранить проблему (или, как бывает в некоторых случаях, ухудшило ее).
Как обычно, начинать следует с тех проблем, которые можно исправить быстро. Проблемы, которые можно исправить за счет изменения объема памяти, выделяемого разделяемому пулу или кэшу буферов, легко устранить практически немедленно за счет динамической настройки значений кэша. Заботиться о любых изменениях, касающихся журналов повторного выполнения, тоже можно сразу же. В случае обнаружения, что один или два пользователя вызывают нехватку ресурсов ЦП, может быть удачной идеей уничтожить их сеансы, чтобы лучше работать стала вся база данных в целом. Как известно, предупреждение всегда лучше лечения, поэтому стоит рассматривать вариант применения инструмента Oracle Database Resource Manager для создания групп ресурсов и предотвращения монополизации ресурсов ЦП одним или несколькими пользователями.
Если работу базы данных замедляют интенсивные состязания за защелки, пожалуй, стоит установить для параметра инициализации CURSOR_SHARING значение FORCE или SIMILAR, чтобы улучшить ситуацию.
Большинство остальных изменений могут требовать применения более длительных по времени решений. Некоторые из них могут даже требовать внесения серьезных изменений в код или же добавления или изменения важных индексов. Однако даже если исправить проблему немедленно не удается, не стоит расстраиваться, потому что такой путь является правильным и в конечном итоге все равно приведет к улучшению производительности экземпляра.
Хотя здесь и были показаны различные методы и приемы, подразумевающие использование SQL-сценариев для анализа производительности экземпляра, при мониторинге производительности базы данных лучше все-таки стараться делать центральным местом интерфейс OEM Database Control (или OEM Grid Control) и применять предлагаемые Oracle мощные инструменты, подобные ADDM, для экономии времени. Отчеты AWR и ASH тоже чрезвычайно полезны при поиске основных причин проблем с производительностью.