
 В данной статье будет рассмотрен вопрос создания приложений, ориентированных на работу в облаке с помощью Spring Boot и Cloud Foundry. Мы рассмотрим поддерживающий инструментарий (например, набор Spring Tool Suite), создадим конфигурацию Java на многочисленных примерах и затем сделаем обзор средств перемещения приложения в облачную среду. Мы автоматизируем процесс развертывания Java-кода в среде его промышленной эксплуатации и расскажем о процессе непрерывного развертывания.
В данной статье будет рассмотрен вопрос создания приложений, ориентированных на работу в облаке с помощью Spring Boot и Cloud Foundry. Мы рассмотрим поддерживающий инструментарий (например, набор Spring Tool Suite), создадим конфигурацию Java на многочисленных примерах и затем сделаем обзор средств перемещения приложения в облачную среду. Мы автоматизируем процесс развертывания Java-кода в среде его промышленной эксплуатации и расскажем о процессе непрерывного развертывания.
Что такое Spring Boot?
Когда приложение называют ориентированным на работу в облачной среде, это значит, что оно написано для успешного выполнения в рабочей среде на основе облака. Среда Spring Boot предоставляет способ создания готовых к использованию Spring-приложений с минимальным временем настройки. Основные цели создания проекта Spring Boot были сконцентрированы на идее, согласно которой пользователи должны иметь возможность быстро освоиться в среде Spring.
В проекте Spring Boot также прослеживается особый взгляд на платформу Spring и библиотеки сторонних разработчиков. Особый взгляд означает, что в Spring Boot излагается набор знакомых абстракций, общий для всех Spring-проектов. Этот особый взгляд предоставляет подводки к тому, что необходимо всем проектам, притом ничем не мешая создателю. Таким образом, Spring Boot упрощает замену компонентов при изменении проектных требований. Он основывается на экосистеме Spring и библиотеках сторонних разработчиков, включая мнения и формирование соглашений, призванных упростить реализацию приложений, готовых к эксплуатации.
Начало работы с проектом Spring Initializr
Spring Initializr представляет собой проект с открытым кодом и инструмент в экосистеме Spring, помогающий быстро создавать новые приложения Spring Boot. Pivotal запускает экземпляр Spring Initializr, размещенный на сервисах Pivotal Web Services. Он генерирует
проекты Maven и Gradle с любыми указанными зависимостями, схематический образ Java-класса, служащего точкой входа, и схематический образ блочного теста.
В мире монолитных приложений такая цена способна быть непомерно высокой, но стоимость инициализации можно легко амортизировать на протяжении всей жизни проекта. При переходе на архитектуру, ориентированную на использование облачной среды, понадобится создание все большего и большего количества приложений. Из-за этого разногласия в создании новых приложений в вашей архитектуре должны быть сведены к минимуму. Spring Initializr помогает снизить первоначальную стоимость. Это и веб-приложение, пригодное к применению из вашего браузера, и REST API, который будет создавать для вас новые проекты.
Например, этим инструментом можно воспользоваться для создания нового проекта Spring Boot, запустив команду curl:
curl http://start.spring.ioРезультат будет выглядеть примерно так же, как на рис. 1.
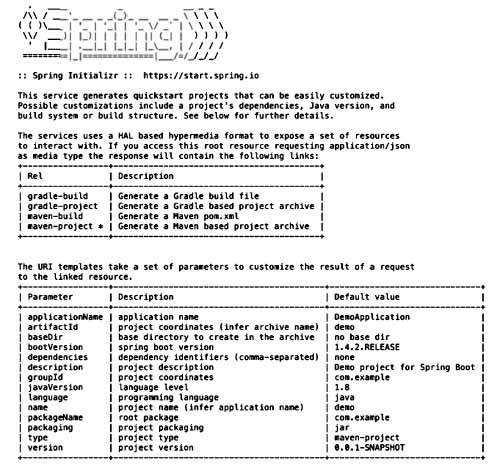
Рис. 1. Взаимодействие c Spring Initializr через REST API
В качестве альтернативы Spring Initializr можно применить из браузера (http:// start.spring.io/), как показано на рис. 2.

Рис. 2. Сайт Spring Initializr
А теперь предположим, что нам нужно создать простой веб-сервис RESTful, который обращается к базе данных SQL (Н2). Понадобится привлечь необходимые библиотеки из экосистемы Spring, включая Spring MVC, Spring Data JPA и Spring Data REST (табл. 1).
Таблица 1. Некоторые примеры Spring Boot Starters для типичного приложения Spring Boot
Проект Spring | Проекты Starter | Maven-идентификатор компонента |
Spring Data JPA | JPA | spring-boot-starter-data-jpa |
Spring Data REST | REST Repositories | spring-boot-starter-data-rest |
Spring Framework (MVC) | Web | spring-boot-starter-web |
Spring Security | Security | spring-boot-starter-security |
H2 Embedded SQL DB | H2 | h2 |
Чтобы найти эти ингредиенты, можно приступить к набору имени зависимостей в поле поиска или щелкнуть на пункте Switch to the full version (Переключиться на полную версию), а затем вручную установить флажки для желаемых зависимостей. Большинство из них называется зависимостями начального проекта (Starter Project dependencies).
Начальная зависимость starter — тип особой дополнительной библиотеки, которая автоматически вставит набор базовых функций, составленный из других проектов экосистемы Spring, в ваше новое приложение Spring Boot.
При создании приложения Spring Boot с самого начала пришлось бы перемещаться по сети промежуточных зависимостей. Вследствие этого можно столкнуться с проблемой, если у приложения есть зависимости от сторонних библиотек, имеющих конфликтующие версии. Spring Boot обрабатывает конфликтующие промежуточные зависимости, поэтому нужно только указать одну версию родительского проекта Spring Boot. Это затем гарантирует, что любая начальная зависимость Spring Boot от пути к классам вашего приложения будет использовать совместимые версии.
Выполним небольшое упражнение. Обратимся к Spring Initializr и включим начальные зависимости для Web, Н2, REST Repositories и JPA. Все остальное оставим в качестве установок по умолчанию. Нажмем кнопку Generate Project (Создать проект), и начнется загрузка архива demo.zip. Распакуем архив и получим исходный код схематического образа проекта, готовый к импортированию в IDE-среду по вашему выбору (пример 1).
Пример 1. Содержимое сгенерированного архива приложения Spring Boot после распаковки

В примере 2 показана структура каталогов сгенерированного приложения. Выступая в качестве части содержимого сгенерированного проекта, инструмент Spring Initializr предоставляет сценарий-упаковщик, либо Gradle wrapper (gradlew), либо Maven wrapper (из проекта Maven wrapper) (mvnw). Этот упаковщик можно применить для сборки и запуска проекта. При первом запуске упаковщик загружает сконфигурированную версию инструмента сборки. Версии Maven или Gradle контролируются. Это значит следующее: все последующие пользователи будут иметь воспроизводимую сборку. Риск того, что кто-то попытается провести сборку вашего кода с несовместимой версией Maven или Gradle, отсутствует. Это также существенно упрощает процесс непрерывного развертывания: сборка, используемая для разработки, будет точно такой же, как и сборка, применяемая в среде непрерывной интеграции.
Следующая команда запустит новую установку Maven-проекта с загрузкой и кэшированием зависимостей, указанных в pom.xml, и установкой компонента сборки .jar в локальное Maven-хранилище (обычно это $H0ME/.m2/repository/*):
$ ./mvnw clean installЧтобы запустить приложение Spring Boot из командной строки, воспользуйтесь предоставляемым дополнительным модулем Spring Boot Maven, автоматически сконфигурированным в сгенерированном файле pom.xml:
$ ./mvnw spring-boot:runВеб-приложение должно быть успешно запущено и доступно по адресу http:// localhost:8080. Но беспокоиться не стоит, ничего особо интересного пока не произошло.
Откройте файл проекта pom.xml в привычном для вас текстовом редакторе: emacs, vi, TextMate, Sublime, Atom, Notepad.exe и т. д., подойдет любой из них (пример 2).
Пример 2. Раздел зависимостей из файла проекта демонстрационного сервиса pom.xml
<dependencies>
<!--- Блок №1 -->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-jpa</artifactld>
</dependency>
<!--- Блок №2 -->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-rest</artifactId>
</dependency>
<!--- Блок №3 -->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<!--- Блок №4 -->
<dependency>
<groupId>com.h2database</groupId>
<artifactld>h2</artifactld> <scope>runtime</scope>
</dependency>
<!--- Блок №5 -->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-test</artifactId>
<scope>test</scope>
</dependency>
</dependencies>
Блок №1. Компонент spring-boot-starter-data-jpa обеспечивает существующие Java- объекты всем необходимым, используя спецификацию объектно-реляционного отображения — Java ORM (Object Relational Mapping) и JPA (Java Persistence API), и обладает высокой продуктивностью на выходе. Этот компонент включает типы JPA-спецификации, основное подключение на Java к базам данных SQL — Java database connectivity (JDBC) и поддержку JPA для Spring, Hibernate в качестве реализации, Spring Data JPA и Spring Data REST.
Блок №2. Компонент spring-boot-starter-data-rest упрощает экспорт работающих с гипермедиа REST-сервисов из определения хранилища Spring Data.
Блок №3. Компонент spring-boot-starter-web обеспечивает всем необходимым для сборки REST-приложений со Spring. Он вводит поддержку JSON- и XML- маршализации, выгрузки файлов, встроенный веб-контейнер (по умолчанию используется самая последняя версия Apache Tomcat), поддержку проверочных операций, Servlet API и др. Это дублирующая зависимость, поскольку spring- boot-starter-data-rest автоматически введет ее для нас. Здесь она обозначена для прояснения ситуации.
Блок №4. Компонент h2 является встроенной базой данных SQL, хранящей данные в памяти. Если в путях классов среда Spring Boot обнаружит встроенную базу данных, подобную Н2, Derby или HSQL, и увидит, что вы не располагаете где-либо по-иному сконфигурированным источником данных javax. sql. DataSource, то сконфигурирует его за вас. Встроенный источник данных DataSource заработает при запуске приложения и сам себя уничтожит (вместе со всем своим содержимым!), когда приложение прекратит функционировать.
Блок №5. Компонент spring-boot-starter-test вводит все исходные типы, требуемые для написания эффективных имитаторов и комплексных тестов, включая среду тестирования Spring MVC. Предполагается, что поддержка тестирования необходима, и эта зависимость добавляется по умолчанию.
В родительской сборке указываются все версии этих зависимостей. В типовом проекте Spring Boot явно задается только версия для самой среды Spring Boot. Как только становится доступна новая версия последней, укажите в вашей сборке на нее, и с ней будут обновлены все соответствующие библиотеки и включения.
Затем откройте в привычном для вас текстовом редакторе класс точки входа приложения, demo/src/main/java/com/example/DemoApplication.java, и вместо него вставьте код примера 3.
Данный код должен функционировать, но убедиться в этом у нас не получится, пока мы его не протестируем! При наличии тестов можно установить контрольное рабочее состояние для разрабатываемого ПО, а затем усовершенствовать его на основе исходного уровня качества.
Пример 3. Простейшее приложение Spring Boot с JPA-классом Cat package com.example;
package com.example;
import org.springframework.boot.SpringApplication;
import org.springframework.boot.autoconfigure.SpringBootApplication;
import org.springframework.data.jpa.repository.JpaRepository;
import org.springframework.data.rest.core.annotation.RepositoryRestResource;
import javax.persistence.Entity;
import javax.persistence.GeneratedValue;
import javax.persistence.Id;
@SpringBootApplication
public class DemoApplication {
public static void main(String[] args) {
SpringApplication.run(DemoApplication.class, args);
}
}
@Entity
class Cat {
@Id
@GeneratedValue
private Long id;
private String name;
Cat() {
}
public Cat(String name) {
this.name = name;
}
@Override
public String toString() {
return "Cat{" + "id=" + id + ", name='" + name + '\'' + '}';
}
public Long getId() {
return id;
}
public String getName() {
return name;
}
}
@RepositoryRestResource
interface CatRepository extends JpaRepository<Cat, Long> {
}Строка 13. Выполнение аннотации класса в качестве приложения Spring Boot.
Строка 18. Запуск приложения Spring Boot.
Строка 23. Обычный JPA-элемент для моделирования элемента Cat.
Строка 54. Хранилище Spring Data JPA (в котором обрабатываются все общие операции создания, чтения, обновления и удаления), экспортированное в качестве REST API.
Запустите приложение и поработайте с базой данных через НAL-закодированный гипермедиа-REST API по адресу http://locahost:8080/cats. Если запустить тест, то он должен быть пройден!
Прежде чем приступить к созданию приложений, ориентированных на функционирование в облаке с помощью Spring Boot, нужно настроить среду разработки.
Начало работы со Spring Tool Suite
До сих пор все наши действия выполнялись с использованием текстового редактора, но большинство инженеров в наше время применяют IDE-среду. В этой области есть ряд вполне подходящих средств, и Spring Boot хорошо работает с любым из них. Если у вас еще нет Java IDE, то обратите внимание на Spring Tool Suite (STS) (http://spring.io/tools). Данная среда является IDE, основанной на Eclipse, и в ней собран общий инструментарий экосистемы, позволяющий не тратить время на его загрузку с сайта Eclipse (http://www.eclipse.org/). STS имеется в свободном доступе в соответствии с условиями Eclipse Public License.
STS позволяет получить при работе с Spring Initializr такие же ощущения, как и при обычном взаимодействии с IDE-средой. Фактически функциональные возможности, имеющиеся в Spring Tool Suite, IntelliJ Ultimate edition, Net Beans и в самом вебприложении Spring Initializr, делегируются REST API, имеющемуся в Spring Initializr, поэтому вы получаете одинаковый результат, независимо от того, откуда начнете.
Для написания приложений Spring или Spring Boot не нужно использовать некую конкретную IDE-среду. Авторы без каких-либо проблем создавали Spring- приложения в emacs, обычной среде Eclipse, Apache Netbeans (как с поддержкой, так и без поддержки замечательного дополнительного модуля Spring Boot, в создании которого поучаствовали специалисты такой серьезной компании, как Oracle), и IntelliJ IDEA Community edition и Ultimate edition. Для Spring Boot 1.x, в частности, требуется Java 6 и выше, а также поддержка редактирования обычных файлов . properties, как и поддержка работы со сборками на основе Maven или Gradle. Для этого подойдут любые IDE-среды начиная с 2010 года и выше.
При использовании Eclipse у Spring Tool Suite появляется множество приятных особенностей, которые придают дополнительные удобства работе с проектами на основе Spring Boot.
- В STS IDE можно получить доступ ко всем справочникам по Spring.
- IDE-среда позволяет создавать новые проекты с помощью Spring Initializr.
- При попытке обращения к типу, которого нет в путях к классам (classpath), но который может быть обнаружен в starter-зависимостях Spring Boot, STS автоматически добавит этот тип.
- Boot Dashboard позволяет беспрепятственно редактировать локальные приложения Spring Boot, сохраняя их синхронизацию с развертыванием Cloud
Foundry. Дальнейшую отладку и перезагрузку развернутых приложений Cloud Foundry можно проводить, не выходя из ГОЕ.
- STS облегчает редактирование файлов Spring Boot с расширениями . properties или .yml, предлагая, кроме всего прочего, функцию автозавершения.
- Spring Tool Suite представляет собой стабильное, интегрированное издание Eclipse, выпущенное вскоре после выхода основного издания Eclipse.
Установка Spring Tool Suite (STS)
Загрузите и установите Spring Tool Suite (STS) (http://spring.io/):
- перейдите на https://spring.io/tools/sts;
- выберите пункт Download STS (Скачать STS);
- загрузите, распакуйте и запустите STS.
После выполнения последнего пункта вам будет предложено выбрать расположение рабочей области. Выберите желаемый вариант и нажмите кнопку ОК. Если планируется применение той же области при каждом запуске STS, то щелкните на пункте Use this as the default and do not ask again (Использовать по умолчанию и больше не спрашивать). После определения расположения рабочей области и нажатия кнопки ОК среда STS ГОЕ будет загружена в первый раз (рис. 3).

Рис. 3. Панель управления STS
Есть также пакеты для многочисленных операционных систем. Например, если применяется Homebrew Cask на OS X или macOS Sierra, то можно воспользоваться разделом репозитория Pivotal tap, а затем запустить команду brew cask install sts.
Создание нового проекта с помощью Spring Initializr
Только что созданный пример можно импортировать из Spring Initializr напрямую, для чего нужно перейти по пунктам File ► Import ► Maven (Файл ► Импорт ► Maven), а затем в корневом каталоге имеющегося проекта указать на необходимость импортирования файла pom.xml. Однако вместо этого для создания нашего первого приложения Spring Boot задействуем STS. Мы собираемся с помощью проекта Spring Boot Starter разработать простой веб-сервис Hello World. Чтобы создать новое приложение Spring Boot, используя проект Spring Boot Starter, выберите из меню, как показано на рис. 4, пункты File ► New ► Spring Starter Project (Файл ► Новый ► Spring Starter Project).

Рис. 4. Создание нового проекта Spring Boot Starter
После выбора пункта, позволяющего создать новый проект Spring Boot Starter, появится диалоговое окно, предназначенное для настройки вашего нового приложения Spring Boot (рис. 5).

Рис. 5. Настройка вашего нового проекта Spring Boot Starter
Можно, конечно, выбрать свои варианты, но, чтобы не усложнять нашу легкую прогулку, воспользуемся исходными значениями и щелкнем на кнопке Next (Далее). После этого будет показан набор проектов Spring Boot Starter, из которого можно выбрать некие элементы для вашего нового приложения Spring Boot. Для нашего первого приложения мы собираемся выбрать Web (рис. 6.).

Рис. 6. Выберите тип вашего проекта Spring Boot Start
Нажмите кнопку Finish (Завершить). После этого ваше приложение Spring Boot будет создано и импортировано для вас в рабочее пространство IDE-среды, став видимым в проводнике пакетов (Package Explorer).
Раскройте, если это еще не сделано, узел demo [boot] в Package Explorer, и просмотрите содержимое пакета, как показано на рис. 7.

Рис. 7. Раскройте в проводнике пакетов проект demo
Из раскрытых файлов проекта перейдите к файлу src/main/java/com/example/DemoApplication.java. И, не останавливаясь на этом, запустите приложение, воспользовавшись пунктами меню Run ► Run (Пуск ► Пуск) (рис. 8).

Рис. 8. Запуск приложение Spring Boot
После выбора из меню пункта Run (Пуск) появится диалоговое окно Run As (Запустить как). Выберите пункт Spring Boot Арр (Приложение Spring Boot), после чего нажмите кнопку ОК (рис. 9).

Рис. 9. Выберите Spring Boot App и запустите приложение
Теперь ваше приложение Spring Boot запустится (рис. 10). Если посмотреть на консоль STS, то там после запуска будет значок Spring Boot, составленный из ASCII-символов, и версия Spring Boot. Там же можно увидеть вывод регистрационных записей данного приложения. Вы увидите, что был запущен встроенный сервер Tomcat и этот запуск произошел с привязкой к порту 8080, используемому по умолчанию. К вашему веб-сервису Spring Boot можно обратиться с адреса http://localhost:8080.

Рис. 10. Вывод регистрационных записей Spring Boot в консоли STS
Руководства no Spring
Руководства по Spring (https://spring.io/guides) представляют собой набор небольших, конкретизированных введений во всевозможные темы, относящиеся к проектам Spring. Существует множество руководств, большинство из которых написано специалистами из команды Spring, а к отдельным из них приложили руку партнеры по экосистеме. В каждом из руководств по Spring используются одинаковые подходы с целью предоставить всеобъемлющее и в то же время практичное справочное руководство, которое можно было бы изучить за 15-30 минут. Эти руководства — одни из наиболее полезных ресурсов для тех, кто приступает к работе со Spring Boot.
Как показано на рис. 11, на сайте Spring Guides предоставляется целая коллекция постоянно поддерживаемых примеров, нацеленных на конкретные варианты использования.

Рис. 11. Сайт Spring Guides
На рис. 12 был введен поисковый запрос spring boot, сужающий список руководств, имеющих отношение к Spring Boot.

Рис. 12. Просмотр руководств по Spring
В качестве части каждого руководства по Spring будут встречаться уже знакомые разделы:
- Getting started (С чего начать);
- Table of contents (Содержимое);
- What you'll build (Что будет создаваться);
- What you'll need (Что понадобится);
- How to complete this guide (Порядок изучения руководства);
- Walkthrough (Пошаговая инструкция);
- Summary (Резюме);
- Get the code (Получение кода);
- Link to GitHub repository (Ссылка на репозиторий GitHub).
А теперь выберем одно из основных руководств по Spring Boot под названием Building an Application with Spring Boot (Создание приложения с помощью Spring Boot).
На рис. 13 показана основная структура руководства по Spring. Каждое руководство структурировано узнаваемым образом, чтобы помочь усвоить содержимое наиболее рациональным способом. В каждом руководстве имеется ссылка на репозиторий GitHub, включающий в себя три папки: complete, initial и test. В папке complete хранится конечный вариант работоспособного примера, по которому можно проверить результат усилий. В папке initial содержится схематическая модель, почти пустая файловая система, пригодная для обхода рутинного кода и концентрации внимания на том, что является уникальным для данного руководства. В папке test имеется все необходимое для подтверждения работоспособности всего проекта.

Рис. 13. Создание приложения с помощью руководства по Spring Boot
В вашей практике кодинга будут встречаться ситуации или сценарии, которые могут потребовать использования расширенного справочного руководства, чтобы помочь вам лучше понять материал. В таких случаях рекомендуется обращаться к руководствам по Spring и найти то, которое будет отвечать вашим потребностям наилучшим образом.
Следование руководствам в STS. При использовании Spring Tool Suite можно следовать рекомендациям руководств прямо из IDE-среды. Для этого нужно пройти по пунктам меню File ► New ► Import Spring Getting Started Content (Файл ► Новый ► Импортировать содержимое Spring Getting Started) (рис. 14).

Рис. 14. Импортирование содержимого Spring Getting Started
В вашем распоряжении окажется точно такой же каталог руководств, что и на сайте справки (рис. 15).

Рис. 15. Выбор руководства из диалогового окна Import Getting Started Content (Импортировать содержимое Getting Started)
Выберите руководство, и оно отобразится в вашей IDE-среде, как и соответствующий код (рис. 16).

Рис. 16. IDE-среда загружает руководство и соответствующие ему Git-проекты
Конфигурация Java
По сути, приложение Spring — коллекция объектов. Spring управляет ими и их взаимоотношениями в ваших интересах, предоставляя по мере необходимости сервисы этим объектам. Среда Spring сможет поддерживать ваши объекты в виде библиотечных компонентов (bean-компонентов), если будет осведомлена о них. В среде Spring предоставляется несколько различных (дополнительных) способов описания ваших компонентов.
Предположим, у нас имеется типичный многоуровневый сервис с объектом сервиса, который, в свою очередь, обращается к javax.sql.DataSource, чтобы обменяться данными (в этом конкретном случае) со встроенной базой данных, то есть с Н2. Нам необходимо определить сервис. Ему понадобится источник данных (datasource). Мы можем создать его экземпляр в требующем его месте, но затем придется продублировать эту же логику там, где нужно будет повторно воспользоваться источником данных в других объектах. Получение и инициализация ресурса происходят на месте вызова, следовательно, мы не можем где-либо применить эту же логику еще раз. Пример 5 показывает, что встроенный экземпляр DataSource позже способен стать источником проблемы.
Пример 5. Приложение, в котором экземпляр DataSource создается в классе, что фактически не позволяет рассчитывать на совместное использование определения
package com.example.raai;
import com.example.Customer;
import org.springframework.core.io.ClassPathResource;
import org.springframework.jdbc.datasource.embedded.EmbeddedDatabaseBuilder;
import org.springframework.jdbc.datasource.embedded.EmbeddedDatabaseType;
import org.springframework.jdbc.datasource.init.DataSourceInitializer;
import org.springframework.jdbc.datasource.init.ResourceDatabasePopulator;
import org.springframework.util.Assert;
import javax.sql.DataSource;
import java.sql.Connection;
import java.sql.ResultSet;
import java.sql.SQLException;
import java.sql.Statement;
import java.util.ArrayList;
import java.util.Collection;
import java.util.List;
public class CustomerService {
private final DataSource dataSource = new EmbeddedDatabaseBuilder()
.setName("customers").setType(EmbeddedDatabaseType.H2).build();
public static void main(String argsp[]) throws Throwable {
CustomerService customerService = new CustomerService();
// БЛОК №1
DataSource dataSource = customerService.dataSource;
DataSourceInitializer init = new DataSourceInitializer();
init.setDataSource(dataSource);
ResourceDatabasePopulator populator = new ResourceDatabasePopulator();
populator.setScripts(new ClassPathResource("schema.sql"),
new ClassPathResource("data.sql"));
init.setDatabasePopulator(populator);
init.afterPropertiesSet();
// БЛОК №2
int size = customerService.findAll().size();
Assert.isTrue(size == 2);
}
public Collection<Customer> findAll() {
List<Customer> customerList = new ArrayList<>();
try {
try (Connection c = dataSource.getConnection()) {
Statement statement = c.createStatement();
try (ResultSet rs = statement.executeQuery("select * from CUSTOMERS")) {
while (rs.next()) {
customerList.add(new Customer(rs.getLong("ID"), rs.getString("EMAIL")));
}
}
}
}
catch (SQLException e) {
throw new RuntimeException(e);
}
return customerList;
}
}БЛОК №1. Трудно выставить источник данных (datasource), поскольку единственная ссылка на него скрыта в закрытом неизменяемом поле (private final field) в самом классе CustomerService. Единственный способ получения доступа к этой переменной заключается в использовании имеющегося в Java «дружественного» доступа (friend access), где экземпляры заданного объекта способны видеть другие экземпляры, а также закрытые переменные.
БЛОК №2. Здесь применяются типы из самой среды Spring, а не из JUnit, поскольку библиотека JUnit для «отработки» компонента использует типы, относящиеся к области видимости test. Класс Assert среды Spring поддерживает проектирование по контракту, а не блочное тестирование!
Поскольку мы не в состоянии подключить имитатор источника данных (mock datasource) и выставить источник данных каким-либо иным образом, мы вынуждены встроить тестовый код в сам компонент. Провести тестирование надлежащим образом будет нелегко, следовательно, в пути к классам для нашего основного кода понадобятся test-зависимости на период проверки.
Мы задействуем встроенный источник данных, который будет одинаковым как для разработки, так и для эксплуатации. В реальном примере конфигурация особенностей, относящихся к среде окружения, таких как имена пользователей и хостов, будет параметризирована; в противном случае при любой попытке выполнения кода будет задействоваться источник данных, предназначенный для практического использования!
Рациональнее было бы централизовать определение bean-компонентов, вынеся его за пределы тех мест вызова, где оно применяется. Каким образом код нашего компонента получит доступ к этой централизованной ссылке? Мы можем сохранить ее в статических переменных, но как тогда проводить тестирование, при условии, что статические ссылки будут разбросаны по всему коду? Как имитировать ссылку? Ссылки можно сохранить в каком-либо совместно используемом контексте, подобном интерфейсу доступа к сервисам имен и каталогов — JNDI (Java Naming and Directory Interface), но тогда мы столкнемся с похожей проблемой: возникнут сложности с тестированием такой схемы без имитации всего интерфейса JNDI!
Вместо того чтобы закрывать логику инициализации ресурсов и их получения во всех потребителях этих ресурсов, можно создать объекты и установить их подключение в одном месте: в отдельном классе. Данный принцип называется инверсией управления — Inversion of Control (IoC).
Подключение объектов отделяется от самих компонентов. Благодаря этому разделению появляется возможность создавать код компонентов, имеющий зависимость от базовых типов и интерфейсов и не содержащий привязки к конкретной реализации. Такая операция называется внедрением зависимостей. Компонент, не знающий о том, как и где создана конкретная зависимость, проигнорирует тот факт, что в ходе блочного тестирования она будет представлена поддельным (имитационным) объектом.
Переместим подключение объектов — конфигурацию — в отдельный класс, то есть в класс конфигурации. А теперь посмотрим в примере 6, как это поддерживается имеющейся в Spring конфигурацией Java.
A как насчет XML? Среда Spring дебютировала с поддержкой конфигурации на основе XML. Такая конфигурация предлагает множество преимуществ, сходных с конфигурацией Java: она является централизованным компонентом, отделенным от подключаемых компонентов. Она по-прежнему поддерживается, но не очень подходит приложениям Spring Boot, зависящим от конфигурации Java. В моем блоге конфигурация на основе XML использоваться не будет.
Пример 6. Класс конфигурации, позволяющий удалить определения bean-компонентов из мест их вызова
package com.example.javaconfig;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import org.springframework.jdbc.datasource.embedded.EmbeddedDatabaseBuilder;
import org.springframework.jdbc.datasource.embedded.EmbeddedDatabaseType;
import javax.sql.DataSource;
// БЛОК №1
@Configuration
public class ApplicationConfiguration {
// БЛОК №2
@Bean(destroyMethod = "shutdown")
DataSource dataSource() {
return new EmbeddedDatabaseBuilder().setType(EmbeddedDatabaseType.H2)
.setName("customers").build();
}
// БЛОК №3
@Bean
CustomerService customerService(DataSource dataSource) {
return new CustomerService(dataSource);
}
}БЛОК №1. Данный класс относится к Spring-классу @Configuration, который сообщает среде Spring, что она может ожидать обнаружения определений объектов и порядка их взаимного подключения в этом классе.
БЛОК №2. Определение DataSource будет извлечено и помещено в определение bean-компонента. Это позволит увидеть его и работать с ним любому другому элементу Spring, и это единственный экземпляр DataSource.
Если от DataSource зависят десять компонентов Spring, то у них у всех будет исходный доступ к одному и тому же экземпляру в памяти. Это связано с понятием области видимости среды Spring. По умолчанию bean-компонент Spring имеет одноэлементную область видимости.
БЛОК №3. Регистрация экземпляра CustomerService со Spring и принуждение Spring к соответствию требованиям DataSource с помощью сквозного анализа других зарегистрированных библиотечных модулей в контексте приложения и нахождения тех, чей тип соответствует параметру поставщика bean-компонента.
Вернитесь к CustomerService и удалите явно указанную логику создания DataSource (пример 7).
Пример 7. Очищенный код CustomerService, из которого убрана логика инициализации и получения ресурсов
package com.example.javaconfig;
import com.example.Customer;
import javax.sql.DataSource;
import java.sql.Connection;
import java.sql.ResultSet;
import java.sql.SQLException;
import java.sql.Statement;
import java.util.ArrayList;
import java.util.Collection;
import java.util.List;
public class CustomerService {
private final DataSource dataSource;
// БЛОК №1
public CustomerService(DataSource dataSource) {
this.dataSource = dataSource;
}
public Collection<Customer> findAll() {
List<Customer> customerList = new ArrayList<>();
try {
try (Connection c = dataSource.getConnection()) {
Statement statement = c.createStatement();
try (ResultSet rs = statement.executeQuery("select * from CUSTOMERS")) {
while (rs.next()) {
customerList.add(new Customer(rs.getLong("ID"), rs.getString("EMAIL")));
}
}
}
}
catch (SQLException e) {
throw new RuntimeException(e);
}
return customerList;
}
}БЛОК №1. Определение типа CustomerService существенно упростилось, поскольку теперь он зависит от DataSource. Мы сняли с себя часть ответственности, возможно, чтобы больше думать об области видимости этого типа: о взаимодействии с dataSource, а не об определении самого dataSource.
Конфигурация задается явно, но имеет слегка избыточный характер. Если среде Spring позволить, то она способна создать ряд конструкций! В конце концов, зачем нам брать на себя все трудности? Можно же воспользоваться стереотипными аннотациями Spring, чтобы пометить собственные компоненты и позволить Spring создать их экземпляры на основе соглашения.
Вернемся к классу ApplicationConfiguration и позволим Spring обнаружить наши стереотипные компоненты, используя сканирование компонентов (пример 8). Теперь уже не нужно составлять явные описания относительно конструкции компонента CustomerService, поэтому его определение также подвергнется удалению. Тип CustomerService будет точно таким же, как и раньше, за исключением того, что к нему применится аннотация @Component.
Пример 8. Выделение конфигурации DataSource в отдельный конфигурационный класс
package com.example.componentscan;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.ComponentScan;
import org.springframework.context.annotation.Configuration;
import org.springframework.jdbc.datasource.embedded.EmbeddedDatabaseBuilder;
import org.springframework.jdbc.datasource.embedded.EmbeddedDatabaseType;
import javax.sql.DataSource;
@Configuration
@ComponentScan
// БЛОК №1
public class ApplicationConfiguration {
@Bean(destroyMethod = "shutdown")
DataSource dataSource() {
return new EmbeddedDatabaseBuilder().setType(EmbeddedDatabaseType.H2)
.setName("customers").build();
}
}БЛОК №1. Эта аннотация указывает среде Spring на необходимость обнаружения других bean-компонентов в контексте приложения путем сканирования текущего пакета (или того, что находится ниже) и поиска всех объектов, аннотированных с помощью стереотипных аннотаций наподобие @Component. Эта аннотация и другие, которые сами аннотируются благодаря @Component, действуют в качестве своеобразного маркера для Spring, сходного с тегами. Spring различает их по компонентам и создает новый экземпляр объекта, к которому они применяются. По умолчанию они вызывают конструктор без аргументов или же конструктор с параметрами, если все параметры удовлетворяют ссылкам на другие объекты в контексте приложения. Spring предоставляет множество сервисов в виде присоединенных аннотаций, ожидаемых в классе @Configuration.
В коде нашего примера источник данных (datasource) используется напрямую, и для получения простого результата мы вынуждены набирать массу низкоуровневого шаблонного JDBC-кода. Внедрение зависимостей представляется весьма эффективным инструментом, но это наименее интересный аспект среды Spring. Воспользуемся одной из наиболее привлекательных особенностей Spring — портируемыми абстракциями сервисов — для упрощения взаимодействия с источником данных. Мы заменим наш соответствующий руководству и пространный JDBC-код, применив вместо него шаблон JdbcTemplate среды Spring (пример 9).
Пример 9. Использование JdbcTemplate вместо низкоуровневых вызовов JDBC API
package com.example.psa;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.ComponentScan;
import org.springframework.context.annotation.Configuration;
import org.springframework.jdbc.core.JdbcTemplate;
import org.springframework.jdbc.datasource.embedded.EmbeddedDatabaseBuilder;
import org.springframework.jdbc.datasource.embedded.EmbeddedDatabaseType;
import javax.sql.DataSource;
@Configuration
@ComponentScan
public class ApplicationConfiguration {
@Bean(destroyMethod = "shutdown")
DataSource dataSource() {
return new EmbeddedDatabaseBuilder().setType(EmbeddedDatabaseType.H2)
.setName("customers").build();
}
// БЛОК №1
@Bean
JdbcTemplate jdbcTemplate(DataSource dataSource) {
return new JdbcTemplate(dataSource);
}
}БЛОК №1. Шаблон JdbcTemplate — одна из реализаций Spring-экосистемы шаблонных образцов. Он предоставляет удобные и полезные методы, делающие общение с JDBC простым и обыденным. Он управляет инициализацией и получением ресурсов, уничтожением, обработкой исключений и др., позволяя сконцентрироваться на самой сути решаемой задачи.
Благодаря JdbcTemplate пересмотренный код CustomerService становится намного чище (пример 10).
Пример 10. Значительно упрощенный код CustomerService
package com.example.psa;
import com.example.Customer;
import org.springframework.jdbc.core.JdbcTemplate;
import org.springframework.jdbc.core.RowMapper;
import org.springframework.stereotype.Component;
import java.util.Collection;
@Component
public class CustomerService {
private final JdbcTemplate jdbcTemplate;
public CustomerService(JdbcTemplate jdbcTemplate) {
this.jdbcTemplate = jdbcTemplate;
}
public Collection<Customer> findAll() {
// БЛОК №1
RowMapper<Customer> rowMapper = (rs, i) -> new Customer(rs.getLong("ID"),
rs.getString("EMAIL"));
// БЛОК №2
return this.jdbcTemplate.query("select * from CUSTOMERS ", rowMapper);
}
}БЛОК №1. Существует множество перезагружаемых вариантов метода query, одним из которых ожидается реализация RowMapper. Это объект обратного вызова, который среда Spring будет вызывать в отношении каждого возвращаемого результата, позволяя отображать объекты, поступившие из базы данных, на объект области вашей системы. Интерфейс RowMapper также отлично подходит для лямбда-выражений Java 8!
БЛОК №2. Метод query — обычный метод, умещающийся в одной строке. Так уже гораздо лучше!
Поскольку управление подключением происходит централизованно, то конфигурация bean-компонентов позволяет выполнить подстановку (или внедрение) реализаций с различными специализациями или свойствами. При желании можно изменить все внедренные реализации для поддержки сквозной функциональности, не меняя получателей bean-компонентов. Предположим, что нужно регистрировать время, затрачиваемое на вызов всех методов. Можно создать класс, являющийся подклассом существующего CustomerService, а затем в переопределении метода вставить функцию регистрации до и после вызова реализации в родительском классе. Данная функция является сквозной функциональностью, но для внедрения ее в поведение иерархии объектов придется переопределить все методы.
В идеале нам не придется проходить столь много стадий, чтобы вставить обычные сквозные функциональные возможности поверх таких объектов. Языки, подобные Java, в которых поддерживается только единичное наследование, не предоставляют четкого способа рассмотрения данного варианта использования для любого произвольного объекта. В среде Spring поддерживается альтернативный вариант: аспектно-ориентированное программирование — aspect-oriented programming (АОР). Это более обширная тема, нежели Spring, но последняя предоставляет весьма доступный поднабор АОР для Spring-объектов. Имеющаяся в Spring поддержка АОР сосредотачивается вокруг понятия аспекта, кодирующего сквозное поведение. Элемент среза (pointcut) дает описание шаблона, соответствие которому должно соблюдаться при использовании аспекта. Шаблон в элементе среза — часть полноценного языка срезов, поддерживаемого средой Spring. Язык срезов позволяет описывать вызовы методов для объектов в приложении Spring. Предположим, что нужно создать аспект, соответствующий всем вызовам методов в нашем примере CustomerService сегодня и завтра, и вставить регистрирование для фиксации отметок времени.
Для активации имеющейся в Spring АОР-функциональности добавьте @EnableAspectDAutoProxy к классу ApplicationConfiguration @Configuration. После чего останется только выделить сквозную функциональность в отдельный тип, в @Aspect-аннотированный объект (пример 11).
Пример 11. Выделение сквозной функциональности в аспект Spring АОР
package com.example.aop;
import org.apache.commons.logging.Log;
import org.apache.commons.logging.LogFactory;
import org.aspectj.lang.ProceedingJoinPoint;
import org.aspectj.lang.annotation.Around;
import org.aspectj.lang.annotation.Aspect;
import org.springframework.stereotype.Component;
import java.time.LocalDateTime;
@Component
@Aspect
// БЛОК №1
public class LoggingAroundAspect {
private Log log = LogFactory.getLog(getClass());
// БЛОК №2
@Around("execution(* com.example.aop.CustomerService.*(..))")
public Object log(ProceedingJoinPoint joinPoint) throws Throwable {
LocalDateTime start = LocalDateTime.now();
Throwable toThrow = null;
Object returnValue = null;
// БЛОК №3
try {
returnValue = joinPoint.proceed();
}
catch (Throwable t) {
toThrow = t;
}
LocalDateTime stop = LocalDateTime.now();
log.info("starting @ " + start.toString());
log.info("finishing @ " + stop.toString() + " with duration "
+ stop.minusNanos(start.getNano()).getNano());
// БЛОК №4
if (null != toThrow)
throw toThrow;
// БЛОК №5
return returnValue;
}
}БЛОК №1. Пометка этого bean-компонента в качестве аспекта.
БЛОК №2. Объявление о предоставлении данному методу возможности выполниться в режиме охвата, то есть до и после выполнения любого метода, соответствующего выражению среза в аннотации @Around. Существует множество других аннотаций, но на данный момент именно эта придает нашему коду высокую эффективность. Кроме того, можно исследовать имеющуюся в Spring поддержку AspectJ.
БЛОК №3. При вызове метода, соответствующего срезу, сначала вызывается наш аспект и передается ProceedingJoinPoint, являющемуся дескриптором вызова запущенного метода. Можно выбрать опрос выполнения метода, его продолжение, его пропуск и т. д. Этот аспект выполняет регистрационную запись до и после того, как продолжит вызов метода.
БЛОК №4. При выдаче исключения оно перехватывается и чуть позже выдается повторно.
БЛОК №5. Если записывается возвращаемое значение, то оно также и возвращается (при условии, что не было выдано исключение).
В случае необходимости АОР можно использовать напрямую, но многие из действительно значимых сквозных функций, с большей долей вероятности встречающихся при создании обычного приложения, уже извлечены в самой среде Spring. Образцом способно послужить декларативное управление транзакциями. В нашем примере имеется один метод, предназначенный только для чтения. Если бы нужно было ввести еще один обслуживающий бизнес метод, который при одном вызове сервиса вносил бы изменения в базу данных несколько раз, то пришлось бы обеспечить внесение данных изменений в едином рабочем блоке. При этом либо каждое взаимодействие с ресурсом, имеющим состояние (с источником данных), завершалось бы успехом, либо ни одно из взаимодействий не признавалось бы успешным.
Нам бы не хотелось оставлять систему в противоречивом состоянии. Это идеальный пример сквозной функциональности: АОР послужит для начала блока транзакций перед каждым вызовом метода в бизнес-сервисе и для фиксации (или отката) данной транзакции по завершении вызова. Можно сделать именно так, но, к счастью, имеющаяся в Spring поддержка декларативных транзакций уже делает это за нас; не придется создавать низкоуровневый код, выстраиваемый вокруг АОР, чтобы получать работоспособный сеанс транзакций. Добавьте @EnableTransactionManagement к классу конфигурации, а затем опишите границы транзакций в бизнес-сервисе, применив аннотацию @Transactional.
У нас имеется сервисное звено, по логике, следующим шагом может стать создание веб-приложения. Создать конечную точку REST поможет Spring MVC. Для этого понадобится задать конфигурацию самой среды Spring MVC, развернуть ее на сервлет-совместимом сервере приложений, а затем сконфигурировать взаимодействие сервера приложений с Servlet API. Прежде чем сделать следующий шаг и реализовать весьма скромное рабочее веб-приложение и конечную точку REST, может понадобиться выполнить довольно много действий!
Здесь мы использовали стандарт JDBC, но могли выбрать и применение уровня ORM. Но тогда все еще больше усложнилось бы. По отдельности, при пошаговой разработке, все это не слишком сложно, но по совокупности когнитивная нагрузка может стать чрезмерной.
И здесь на сцену выходит среда Spring Boot и ее автоматическое конфигурирование.
В первом примере данной статьи создавалось приложение с интерфейсом, JPA-элемент, несколько аннотаций, класс точки входа public static void main и... все! Среда Spring Boot все запустила, и вуаля! Это был действующий REST API, запускаемый на http://localhost:8080/cats. Приложение поддерживало работу с JPA-элементами с помощью хранилища на основе Spring Data JPA. Делалось многое, для чего, казалось бы, не было указано никакого явного кода, — просто волшебство.
Если вы уже знаете многое о среде Spring, то, без сомнения, сможете распознать, что, кроме всего прочего, мы задействовали среду Spring и имеющуюся в ней надежную поддержку JPA. Spring Data JPA используется для конфигурирования декларативного хранилища, основанного на интерфейсе. Spring MVC и Spring Data REST применяются для обслуживания REST API на основе HTTP, но даже при этом вас может заинтересовать, откуда берется сам веб-сервер. Каждому из упомянутых модулей требуется некая конфигурация. Обычно не слишком объемная, но, конечно же, более пространная, чем та, которую мы здесь создавали! По крайней мере им требуется аннотация для выбора определенного поведения по умолчанию.
Исторически сложилось так, что для среды Spring была выбрана конфигурация. В ее плоскости лежит возможность уточнить поведение приложения. Приоритет в Spring Boot — предоставление разумного поведения по умолчанию и поддержка несложных переопределений. Это полномасштабное использование соглашения по конфигурации. По сути, автоматическое конфигурирование, имеющееся в Spring Boot, есть конфигурация того же порядка, что и конфигурация, создаваемая вручную, с применением тех же аннотаций и тех же bean-компонентов, которые вы можете зарегистрировать, а также с разумными настройками по умолчанию.
В Spring поддерживается понятие загрузчика сервисов для поддержки регистрации пользовательских вкладов в приложение без изменения самой среды Spring. Загрузчик сервисов — отображение типов на имена классов конфигурации Java, которые затем анализируются и позже становятся доступными для приложения Spring. Регистрация пользовательских вкладов выполняется в файле МЕТА-INF/spring.factories. Среда Spring Boot заглядывает в файл spring.factories, чтобы, кроме всего прочего, найти все классы ниже записи org.springframework.boot.autoconfigure.EnableAutoConfiguration. В файле spring-boot-autoconfigure.jar, поставляемом вместе со средой Spring Boot, имеются десятки различных классов конфигураций, и Spring Boot будет пытаться проанализировать все эти классы! Данная среда попробует как минимум проанализировать все имеющиеся классы, но безуспешно вследствие использования различных условий, если хотите, защитников, помещенных в классы конфигурации и в находящиеся в них определения @Bean. Этот инструмент условной регистрации компонентов Spring происходит из самой среды Spring, на основе которой построена Spring Boot. Данные условия весьма разнообразны: они тестируют доступность bean-компонентов заданного типа, наличие свойств среды, доступность конкретных типов в путях к классам и др.
Рассмотрим пример CustomerService. Нам нужно создать версию приложения Spring Boot, использующую встроенную базу данных и шаблон фреймворка Spring JdbcTemplate, а затем поддержку создания веб-приложения. Все необходимое будет сделано средой Spring Boot. Вернемся к приложению ApplicationConfiguration (пример 12) и превратим его в соответствующее приложение Spring Boot.
Пример 12. Класс ApplicationConfiguration.java
package com.example.boot;
import org.springframework.boot.autoconfigure.SpringBootApplication;
@SpringBootApplication
public class ApplicationConfiguration {
//БЛОК №1
}БЛОК №1. Конфигурации-то и нет! Spring Boot внесет все то, что было внесено нами вручную, а также многое другое.
Применим контроллер на основе среды Spring MVC, чтобы показать конечную точку REST для ответа на HTTP GET-запросы на /customers (пример 13).
Пример 13. Класс CustomerRestController.java
package com.example.boot;
import com.example.Customer;
import org.springframework.web.bind.annotation.GetMapping;
import org.springframework.web.bind.annotation.RestController;
import java.util.Collection;
//БЛОК №1
@RestController
public class CustomerRestController {
private final CustomerService customerService;
public CustomerRestController(CustomerService customerService) {
this.customerService = customerService;
}
//БЛОК №2
@GetMapping("/customers")
public Collection<Customer> readAll() {
return this.customerService.findAll();
}
}БЛОК №1. @RestController — еще одна стереотипная аннотация, подобная @Component. Она сообщает среде Spring, что этот компонент предназначен для работы в качестве контроллера REST.
БЛОК №2. Можно воспользоваться аннотациями Spring MVС, приводящими к отображению на область того, что мы пытаемся сделать: в данном случае приведением HTTP GET-запросов к конкретной конечной точке с помощью @GetMapping.
Точку входа можно сделать в классе ApplicationConfiguration (пример 14), затем запустить приложение и перейти в браузере на http://localhost:8080/customers. Разобраться в происходящем в бизнес-логике будет гораздо проще, и мы добились большего с меньшими усилиями!
Пример 14. Создание конечной точки REST с помощью Spring MVC
public static void main(String [] args){
SpringApplication.run (ApplicationConfiguration.class, args);
}Мы получили больше пользы при меньших затратах. Нам известно, что где-то нечто другое создает точно такую же конфигурацию, которую мы сделали ранее. Где создается шаблон JdbcTemplate? В классе автоматической конфигурации по имени JdbcTemplateAutoConfiguration, чье определение показано в примере 15 (в слегка упрощенном виде).
Пример 15. JdbcTemplateAutoConfiguration
@Configuration // БЛОК №1
@ConditionalOnClass({ DataSource.class, JdbcTemplate.class }) // БЛОК №2
@ConditionalOnSingleCandidate(DataSource.class) // БЛОК №3
@AutoConfigureAfter(DataSourceAutoConfiguration.class) // БЛОК №4
public class JdbcTemplateAutoConfiguration {
private final DataSource dataSource;
public JdbcTemplateAutoConfiguration(DataSource dataSource) {
this.dataSource = dataSource;
}
@Bean
@Primary
@ConditionalOnMissingBean(JdbcOperations.class) // БЛОК №5
public JdbcTemplate jdbcTemplate() {
return new JdbcTemplate(this.dataSource);
}
@Bean
@Primary
@ConditionalOnMissingBean(NamedParameterJdbcOperations.class) // БЛОК №6
public NamedParameterJdbcTemplate namedParameterJdbcTemplate() {
return new NamedParameterJdbcTemplate(this.dataSource);
}
}БЛОК №1. Это обычный класс @Configuration.
БЛОК №2. Класс конфигурации должен быть проанализирован только в том случае, если тип DataSource.class и JdbcTemplate.class находятся где-то в пути к классам; в противном случае, без сомнения, будет выдана ошибка наподобие ClassNotFoundException.
БЛОК №3. Этот класс конфигурации понадобится, только если где-то в контексте приложения будет внесен bean-компонент DataSource.
БЛОК №4. Мы знаем, что если DataSourceAutoConfiguration разрешить, то будет внесен источник данных Н2, так что данная аннотация гарантирует введение этой конфигурации после запуска DataSourceAutoConfiguration. В случае ввода базы данных будет проанализирован текущий класс конфигурации.
БЛОК №5. Нам нужно внести JdbcTemplate, но только при условии, что пользователи (то есть мы с вами) еще не определили bean-компонент того же типа в наших собственных классах конфигурации.
БЛОК №6. Нам нужно внести NamedParameterJdbcTemplate, но только при условии, что такого шаблона еще нет.
Автоматическая конфигурация Spring Boot значительно уменьшает объем фактического кода и когнитивную нагрузку, связанную с этим кодом. Она освобождает нас, позволяя сосредоточиться на сути бизнес-логики, перекладывая всю рутину на среду. В случае необходимости контролировать какой-либо аспект набора компонентов мы имеем все возможности внесения Bean-компонентов конкретных типов, и они будут подключены к среде. Spring Boot — реализация принципа открыто-замкнутой среды: она открыта для расширения, но закрыта для изменения.
Переопределение части машины не требует перекомпиляции Spring или Spring Boot. Можно понять, что ваше приложение Spring Boot демонстрирует странное поведение, которое вам хочется переопределить или перенастроить. Важно знать, как это сделать. Укажите при запуске приложения ключ --Ddebug=true, и Spring Boot выдаст распечатку отчета об отладке — Debug Report, показывая все вычисленные условия и то, где у них были положительные или отрицательные соответствия. Пользуясь отчетом, нетрудно будет проанализировать происходящее в соответствующем классе автоматической конфигурации, чтобы прояснить его поведение.
Платформа Cloud Foundry
Spring Boot позволяет сконцентрироваться на сути самого приложения, но что хорошего мы получим от новоприобретенной производительности, если при этом не сможем добиться ввода приложения в производство? Эксплуатация программы — весьма непростая задача, но от ее решения никуда не деться. Одна из целей непрерывного развертывания нашего приложения в среде, имитирующей рабочую, заключается в проведении проверочных объединенных тестов и приемочных испытаний на работоспособность в условиях его развертывания в среде реальной эксплуатации. Очень важно получать изделие как можно раньше и чаще, поскольку существует только одно место, где заказчик, то есть сторона, наиболее заинтересованная в конечном результате деятельности команды, может убедиться в его работоспособности.
Если переход к эксплуатации станет затруднительным, то команда разработчиков неизбежно станет опасаться данного процесса и обретет неуверенность в своих действиях, увеличивая разрыв между созданием и производством. При этом увеличивается отставание в работе, результаты которой не переведены в плоскость реального использования, что означает возрастание риска каждой подвижки, поскольку в каждом выпуске становится больше бизнес-составляющей. Чтобы снизить риск ввода в эксплуатацию, нужно сократить объем действий и увеличить частоту развертывания. Если в таком применении выявится ошибка, то доработка и ее развертывание должны быть как можно менее затратными.
Замысел заключается в автоматизации всего, что может быть автоматизировано в цепочке получения желаемого результата, от управления программным продуктом до его запуска в производство, что не добавляет в процесс практической ценности. Развертывание не относится к видоизменениям в бизнесе, оно не добавляет результата к процессу. Оно должно быть полностью автоматизировано. Повышение производительности достигается за счет автоматизации.
Cloud Foundry — облачная платформа, предназначенная для оказания помощи. Это платформа в виде сервиса (Platform as a Service, PaaS). В Cloud Foundry основное внимание уделяется не жестким дискам, не оперативной памяти, не центральному процессору, не установке Linux и не доработкам, закрывающим бреши безопасности, предлагаемым в инфраструктуре в виде сервиса — Infrastructure as a Service (IaaS), и не контейнерам, которые можно получить в контейнерах в виде сервиса, а приложениям и их сервисам. Специалисты сосредотачиваются на приложениях и их сервисах и ни на чем другом. В моем блоге Cloud Foundry будет использоваться повсеместно, так что сейчас обратимся к развертыванию поэтапно разрабатываемого приложения Spring Boot, рассматривая наряду с этим поддержку конфигурации в среде Spring.
Существует несколько реализаций Cloud Foundry, каждая из которых основана на открытом коде Cloud Foundry. Все приложения, рассматриваемые в данной блоге, будут запускаться и развертываться в Pivotal Web Services. Эта платформа предлагает поднабор функций, предоставляемых компанией Pivotal в устанавливаемой на площадке заказчика (on-premise) системе Pivotal Cloud Foundry. Она базируется на Amazon Web Services, в регионе AWS East region. PWS поможет сделать первые шаги в работе с Cloud Foundry, поскольку является вполне возможным и допустимым вариантом, обслуживающим как небольшие, так и крупные проекты и сопровождаемым командой поддержки компании Pivotal.
Перейдите на главную страницу. Там будут поля входа в систему по существующей учетной записи или регистрации новой учетной записи (рис. 17).

Рис. 17. Главная страница PWS
После входа в систему появляется личный кабинет, и можно получать информацию о развернутых приложениях (рис. 18).

Рис. 18. Консоль PWS
Получив возможность работать в личном кабинете, следует убедиться в наличии интерфейса командной строки — cf command-line interface (CLI). Если его у вас еще не было, нужно зарегистрироваться.
Задайте соответствующий экземпляр Cloud Foundry, применив команду cf target api.run.pivotal.io, и затем зарегистрируйтесь, воспользовавшись командой cf login (пример 16).
Пример 16. Аутентификация и определение организации и пространства Cloud Foundry
➜ cf login
API endpoint: https://api.run.pivotal.io
Email> Адрес электронной почты защищен от спам-ботов. Для просмотра адреса в вашем браузере должен быть включен Javascript.
Password>
Authenticating...
OK
Select an org (or press enter to skip):
1. marketing
2. sales
3. back-office
Org> 1
Targeted org back-office
Targeted space development
API endpoint: https://api.run.pivotal.io (API version: 2.65.0)
User: Адрес электронной почты защищен от спам-ботов. Для просмотра адреса в вашем браузере должен быть включен Javascript.
Org: back-office // Блок №1
Space: development // Блок №2Блок №1. В Cloud Foundry может быть множество организаций, к которым данный пользователь имеет доступ.
Блок №2. В рамках данной организации может быть несколько сред (например, разработки — development, доводки — staging и объединения — integration).
Теперь, имея действительный личный кабинет и войдя в него, можно развернуть приложение в target/configuration.jar. Необходимо предоставить базу данных, используя команду cf create-service (пример 17).
Пример 17. Создание базы данных MySQL, ее привязка к нашему приложению и после этого запуск приложения
cf create-service p-mysql 100mb bootcamp-customers-mysql // Команда №1
cf push -p target/configuration.jar bootcamp-customers \ // Команда №2
--random-route --no-start
cf bind-service bootcamp-customers bootcamp-customers-mysql // Команда №3
cf start bootcamp-customers // Команда №4 Команда №1. Сначала нужно предоставить базу данных MySQL из сервиса MySQL (который называется p-mysql) по плану 100mb. Здесь ей присваивается логическое имя bootcamp-customers-mysql. Для перечисления других сервисов в каталоге сервисов экземпляра Cloud Foundry следует воспользоваться командой cf marketplace.
Команда №2. После этого в Cloud Foundry помещается компонент приложения target/configuration.jar. Мы назначим приложение и произвольный маршрут — random route (URL, в данном случае под доменом PWS cfapps.io), но пока запускать его не собираемся: ему по-прежнему нужна база данных!
Команда №3. База данных есть, но к ней нельзя обратиться, пока она не привязана к приложению. По сути, привязка заключается в выставлении в приложении переменных среды с соответствующей информацией в них о подключении.
Команда №4. После привязки приложения к базе данных его наконец-то можно запустить!
Добавляя приложение к Cloud Foundry, вы предоставляете его как приложение в двоичном коде в виде файла с расширением .jar, а не виртуальной машины или Linux-контейнера (хотя последний ему можно предоставить). При получении файла .jar платформа Cloud Foundry пытается определить природу приложения. К чему оно относится, к приложению Java? К приложению Ruby? К .NET-приложению? И в конечном итоге платформа останавливается на приложении Java. И файл .jar передается пакету Java buildpack. Этот пакет — каталог, наполненный сценариями, вызываемыми в соответствии с известным функциональным циклом. Можно указать URL и переопределить таким образом исходный пакет buildpack, или же можно позволить запуститься именно этому исходному пакету. Существуют buildpack-пакеты для всех разновидностей языков и платформ, включая Java, .NET, Node.js, Go, Python, Ruby и др. Java buildpack определит, что приложение представляет собой выполняемый метод main(String [] args) и поэтому является самодостаточным. Будет задействована самая последняя версия OpenJDK и указано, что наше приложение должно запускаться. Вся эта конфигурация запакована в Linux-контейнер, который затем диспетчер Cloud Foundry развернет в кластере. В одной среде Cloud Foundry может выполнять сотни тысяч контейнеров.
Приложение моментально будет развернуто, и на консоль выведется сообщение с URL, где было открыто приложение. Наши поздравления! Теперь приложение развернуто в экземпляре Cloud Foundry.
В приложении имеется один bean-компонент источника данных, в соответствии с чем Cloud Foundry автоматически заново отобразит его на единственный привязанный сервис MySQL, заменив исходное встроенное определение источника данных Н2 определением, указывающим на источник данных MySQL.
Существует множество аспектов развернутого приложения, которым можно дать описание при каждом развертывании. В первом запуске для конфигурации приложения мы воспользовались различными «заклинаниями» cf, но вскоре такие ухищрения могут превратиться в весьма утомительное занятие. Вместо этого оформим конфигурацию приложения в файле-манифесте Cloud Foundry, обычно называемом manifest.yml.
Файл manifest.yml для приложения, который будет работать при условии наличия источника данных MySQL, получившего указанное ранее имя, получит следующий вид (пример 18).
Пример 18. Манифест Cloud Foundry
---
applications:
- name: bootcamp-customers // Команда №1
buildpack: https://github.com/cloudfoundry/java-buildpack.git // Команда №2
instances: 1
random-route: true
path: target/spring-configuration.jar // Команда №3
services:
- bootcamp-customers-mysql // Команда №4
env:
DEBUG: "true"
SPRING_PROFILES_ACTIVE: cloud // Команда №5Команда №1. Мы предоставили логическое имя приложения...
Команда №2. ...задали пакет buildpack...
Команда №3. ...указали, какой двоичный код используется...
Команда №4. ...определили зависимость от предоставляемых Cloud Foundry сервисов...
Команда №5. ...и указали переменные среды для переопределения свойств, на которые будет реагировать среда Spring Boot. Запись --Ddebug=true (или DEBUG: true) переписывает условия в автоматической конфигурации, а запись --Dspring.profiles.active=cloud указывает, какие профили или логические группировки с произвольными именами должны быть активизированы в приложении Spring. Эта конфигурация предписывает запуск всех bean-компонентов Spring без профилей, а также имеющих облачный профиль.
Теперь вместо написания всех этих cf-заклинаний нужно просто запустить команду cf push -f manifest.yml. Вскоре приложение будет запущено и готово к проверке.
Итак, мы увидели, что использование Cloud Foundry направлено на повышение производительности за счет автоматизации: платформа берет на себя возможный максимум трудоемких задач, позволяя сконцентрироваться на по-настоящему важной бизнес-логике. Мы работали в рамках консервативного подхода, предлагаемого Cloud Foundry: если приложению что-нибудь требуется, то можно объявить соответствующее количество cf-заклинаний или записей в manifest.yml, и платформа поддержит все нужды. Поэтому вызывает удивление тот факт, что, несмотря на незначительный вклад в платформу, сама Cloud Foundry программируется довольно просто. Она предоставляет довольно богатый API, поддерживающий практически все, что вам хочется сделать. Предпринимая дальнейшие шаги, команды Spring и Cloud Foundry разработали Java-клиент Cloud Foundry, поддерживающий все основные компоненты в реализации Cloud Foundry. Java-клиент Cloud Foundry также поддерживает высокоуровневые, более детализированные бизнес-операции,
соответствующие тому, что вы могли бы сделать с помощью интерфейса командной строки (CLI).
Java-клиент Cloud Foundry построен на основе проекта Pivotal Reactor 3.0. Reactor, в свою очередь, лежит в основе среды выполнения reactive web runtime в Spring 5. Java-клиент Cloud Foundry работает весьма быстро и построен на принципах reactive, поэтому практически не подвержен блокировкам.
В свою очередь, проект Reactor является реализацией инициативы Reactive Streams. Эта инициатива, сообщается на этом сайте, «представляет собой инициативу предоставления стандарта для асинхронного потока, обрабатываемого без блокирующего противодействия». Проект предоставляет язык и API для описания потенциально неограниченного потока живых данных, поступающих в асинхронном режиме. Reactor API упрощает написание кода, пользующегося преимуществами распараллеливания, избавляя от необходимости писать код для реализации параллельных вычислений. Ставится цель не допустить агрессивного потребления ресурсов и эффективным образом изолировать блокирующие части облачной рабочей нагрузки. Инициатива Reactive Streams определяет контроль обратного потока (backpressure); подписчик может сигнализировать издателю, что не хочет больше получать уведомления. По сути, он сопротивляется производителю, регулируя потребление до тех пор, пока не сможет себе его позволить.
Суть этого API — org.reactivestreams.Publisher, способный впоследствии производить от нуля до нескольких значений. Подписчик (Subscriber) подписывается на уведомления о новых значениях от издателя (Publisher):Mono и Flux.Mono<T> — издатель Publisher<T>, производящий одно значение. Flux<T> — издатель Publisher<T>, производящий от нуля до нескольких значений.
Элементы множества:
Synchronous;Asynchronous;One;Т;Future<T>;Many;Collection<T>;org.reactivestreams.Publisher<T>.
Мы не будем слишком глубоко вникать в реактивные потоки (reactive streams) или в проект Reactor, но учтем, что он закладывает основы удивительной эффективности Java API Cloud Foundry. Данный интерфейс поддается распараллеливанию обработки, которой очень трудно достичь с помощью команды cf интерфейса командной строки (CLI). Мы развернули то же самое приложение, используя CLI-команду cf, и файл manifest.yml; посмотрим на это в Java-коде. Особенно удобно применять Java-клиент Cloud Foundry в комплексных тестах. Чтобы задействовать Java-клиент Cloud Foundry, нужно сконфигурировать ряд объектов, требуемых для безопасного объединения с различными подсистемами в Cloud Foundry, включая подсистему обобщающей регистрации (log-aggregation subsystem), REST API Cloud Foundry и подсистему аутентификации Cloud Foundry. Мы покажем здесь конфигурацию упомянутых компонентов (пример 19), но вполне вероятно, что вам в ближайших выпусках Spring Boot уже не понадобится конфигурировать эти функциональные свойства.
Пример 19. Конфигурирование Java-клиента Cloud Foundry
package com.example;
import org.cloudfoundry.client.CloudFoundryClient;
import org.cloudfoundry.operations.DefaultCloudFoundryOperations;
import org.cloudfoundry.reactor.ConnectionContext;
import org.cloudfoundry.reactor.DefaultConnectionContext;
import org.cloudfoundry.reactor.TokenProvider;
import org.cloudfoundry.reactor.client.ReactorCloudFoundryClient;
import org.cloudfoundry.reactor.doppler.ReactorDopplerClient;
import org.cloudfoundry.reactor.tokenprovider.PasswordGrantTokenProvider;
import org.cloudfoundry.reactor.uaa.ReactorUaaClient;
import org.springframework.beans.factory.annotation.Value;
import org.springframework.boot.SpringApplication;
import org.springframework.boot.autoconfigure.SpringBootApplication;
import org.springframework.context.annotation.Bean;
@SpringBootApplication
public class CloudFoundryClientExample {
public static void main(String[] args) {
SpringApplication.run(CloudFoundryClientExample.class, args);
}
// Блок №1
@Bean
ReactorCloudFoundryClient cloudFoundryClient(
ConnectionContext connectionContext, TokenProvider tokenProvider) {
return ReactorCloudFoundryClient.builder()
.connectionContext(connectionContext).tokenProvider(tokenProvider).build();
}
// Блок №2
@Bean
ReactorDopplerClient dopplerClient(ConnectionContext connectionContext,
TokenProvider tokenProvider) {
return ReactorDopplerClient.builder().connectionContext(connectionContext)
.tokenProvider(tokenProvider).build();
}
// Блок №3
@Bean
ReactorUaaClient uaaClient(ConnectionContext connectionContext,
TokenProvider tokenProvider) {
return ReactorUaaClient.builder().connectionContext(connectionContext)
.tokenProvider(tokenProvider).build();
}
// Блок №4
@Bean
DefaultCloudFoundryOperations cloudFoundryOperations(
CloudFoundryClient cloudFoundryClient, ReactorDopplerClient dopplerClient,
ReactorUaaClient uaaClient, @Value("${cf.org}") String organization,
@Value("${cf.space}") String space) {
return DefaultCloudFoundryOperations.builder()
.cloudFoundryClient(cloudFoundryClient).dopplerClient(dopplerClient)
.uaaClient(uaaClient).organization(organization).space(space).build();
}
// Блок №5
@Bean
DefaultConnectionContext connectionContext(@Value("${cf.api}") String apiHost) {
if (apiHost.contains("://")) {
apiHost = apiHost.split("://")[1];
}
return DefaultConnectionContext.builder().apiHost(apiHost).build();
}
// Блок №6
@Bean
PasswordGrantTokenProvider tokenProvider(@Value("${cf.user}") String username,
@Value("${cf.password}") String password) {
return PasswordGrantTokenProvider.builder().password(password)
.username(username).build();
}
}БЛОК №1. ReactorCloudFoundryClient — клиент для Cloud Foundry REST API.
БЛОК №2. ReactorDopplerClient — клиент для Doppler, подсистемы Cloud Foundry, основанной на веб-сокетах и предназначенной для обобщающей регистрации.
БЛОК №3. ReactorUaaClient — клиент для UAA, подсистемы авторизации и аутентификации в Cloud Foundry.
БЛОК №4. Экземпляр DefaultCloudFoundryOperations предоставляет укрупненные операции, составляющие клиентов низкоуровневой подсистемы. Все начинается отсюда.
БЛОК №5. ConnectionContext описывает экземпляр Cloud Foundry, на который нужно нацелиться.
БЛОК №6. PasswordGrantTokenProvider описывает аутентификацию.
Имея все это в своем распоряжении, довольно легко получить подтверждение работоспособности. Код в простом примере 20 перечисляет все развернутые приложения в конкретном пространстве и организации.
Пример 20. Перечисление экземпляров приложений
package com.example;
import org.cloudfoundry.operations.CloudFoundryOperations;
import org.springframework.boot.CommandLineRunner;
import org.springframework.stereotype.Component;
@Component
class ApplicationListingCommandLineRunner implements CommandLineRunner {
private final CloudFoundryOperations cf; // БЛОК №1
ApplicationListingCommandLineRunner(CloudFoundryOperations cf) {
this.cf = cf;
}
@Override
public void run(String... args) throws Exception {
cf.applications().list().subscribe(System.out::println); // БЛОК №2
}
}БЛОК №1. Внедрение сконфигурированного экземпляра CloudFoundryOperations...
БЛОК №2. ...и использование его для перечисления всех развернутых приложений в этом конкретном пространстве и организации Cloud Foundry.
Чтобы рассмотреть образец, более приближенный к реальным условиям, развернем наше bootcamp-customers приложение, воспользовавшись Java-клиентом. Речь пойдет о простом комплексном тесте, предоставляющем сервис MySQL, который помещает приложение в среду Cloud Foundry (но не запускает его), выполняет привязку переменных среды, привязывает сервис MySQL и затем наконец-то запускает приложение. Сначала посмотрим на схематический код, в котором идентифицируется развертываемый файл с расширением .jar и имя приложения, а также имя сервиса (пример 21). Мы будем делегировать два компонента, ApplicationDeployer и ServicesDeployer.
Пример 21. Схематический код комплексного теста, предоставляющий приложение
package bootcamp;
import org.cloudfoundry.operations.CloudFoundryOperations;
import org.junit.Test;
import org.junit.runner.RunWith;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.beans.factory.annotation.Value;
import org.springframework.boot.autoconfigure.SpringBootApplication;
import org.springframework.boot.test.context.SpringBootTest;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.PropertySource;
import org.springframework.test.context.junit4.SpringJUnit4ClassRunner;
import java.io.File;
import java.time.Duration;
import java.util.HashMap;
import java.util.Map;
import java.util.concurrent.BrokenBarrierException;
import java.util.concurrent.CountDownLatch;
import java.util.concurrent.CyclicBarrier;
@RunWith(SpringJUnit4ClassRunner.class)
@SpringBootTest(classes = SpringConfigurationIT.Config.class)
public class SpringConfigurationIT {
@Autowired
private ApplicationDeployer applicationDeployer;
@Autowired
private ServicesDeployer servicesDeployer;
@Test
public void deploy() throws Throwable {
File projectFolder = new File(new File("."), "../spring-configuration");
File jar = new File(projectFolder, "target/spring-configuration.jar");
String applicationName = "bootcamp-customers";
String mysqlSvc = "bootcamp-customers-mysql";
Map<String, String> env = new HashMap<>();
env.put("SPRING_PROFILES_ACTIVE", "cloud");
Duration timeout = Duration.ofMinutes(5);
servicesDeployer.deployService(applicationName, mysqlSvc, "p-mysql", "100mb")
// БЛОК №1
.then(
applicationDeployer.deployApplication(jar, applicationName, env, timeout,
mysqlSvc)) // БЛОК №2
.block(); // БЛОК №3
}
@SpringBootApplication
public static class Config {
@Bean
ApplicationDeployer applications(CloudFoundryOperations cf) {
return new ApplicationDeployer(cf);
}
@Bean
ServicesDeployer services(CloudFoundryOperations cf) {
return new ServicesDeployer(cf);
}
}
}БЛОК №1. Сначала развертывание поддерживающего сервиса (экземпляра MySQL)...
БЛОК №2. ...затем развертывание приложения с гарантированной паузой пять минут...
БЛОК №3. ...а затем блокирование для продолжения теста.
В данном примере составляются два экземпляра Publisher, один из которых описывает обработку, необходимую для предоставления сервиса, а другой — обработку, требуемую для предоставления приложения. Финальный вызов в цепочке, .blоск(), запускает обработку; это конечный метод, активирующий весь поток выполнения кода.
ServicesDeployer получает требуемые параметры и предоставляет экземпляр MySQL (пример 22). Он также удаляет привязку экземпляров и сами экземпляры, если все это уже существует.
Пример 22. ServicesDeployer
package bootcamp;
import org.apache.commons.logging.Log;
import org.apache.commons.logging.LogFactory;
import org.cloudfoundry.operations.CloudFoundryOperations;
import org.cloudfoundry.operations.services.CreateServiceInstanceRequest;
import org.cloudfoundry.operations.services.DeleteServiceInstanceRequest;
import org.cloudfoundry.operations.services.ServiceInstanceSummary;
import org.cloudfoundry.operations.services.UnbindServiceInstanceRequest;
import org.reactivestreams.Publisher;
import reactor.core.publisher.Flux;
import reactor.core.publisher.Mono;
import java.util.function.Function;
class ServicesDeployer {
private final Log log = LogFactory.getLog(getClass());
private final CloudFoundryOperations cf;
ServicesDeployer(CloudFoundryOperations cf) {
this.cf = cf;
}
Mono<Void> deployService(String applicationName, String svcInstanceName,
String svcTypeName, String planName) {
return cf.services().listInstances().cache() // БЛОК №1
.filter(si1 -> si1.getName().equalsIgnoreCase(svcInstanceName)) // БЛОК №2
.transform(unbindAndDelete(applicationName, svcInstanceName)) // БЛОК №3
.thenEmpty(createService(svcInstanceName, svcTypeName, planName)); // БЛОК №4
}
private Function<Flux<ServiceInstanceSummary>, Publisher<Void>> unbindAndDelete(
String applicationName, String svcInstanceName) {
return siFlux -> Flux.concat(
unbind(applicationName, svcInstanceName, siFlux),
delete(svcInstanceName, siFlux));
}
private Flux<Void> unbind(String applicationName, String svcInstanceName,
Flux<ServiceInstanceSummary> siFlux) {
return siFlux.filter(si -> si.getApplications().contains(applicationName))
.flatMap(
si -> cf.services().unbind(
UnbindServiceInstanceRequest.builder().applicationName(applicationName)
.serviceInstanceName(svcInstanceName).build()));
}
private Flux<Void> delete(String svcInstanceName,
Flux<ServiceInstanceSummary> siFlux) {
return siFlux.flatMap(si -> cf.services().deleteInstance(
DeleteServiceInstanceRequest.builder().name(svcInstanceName).build()));
}
private Mono<Void> createService(String svcInstanceName, String svcTypeName,
String planName) {
return cf.services().createInstance(
CreateServiceInstanceRequest.builder().serviceName(svcTypeName)
.planName(planName).serviceInstanceName(svcInstanceName).build());
}
}БЛОК №1. Перечисление всех экземпляров приложения и их кэширование, чтобы последующие подписчики не выполняли повторное вычисление REST-вызова.
БЛОК №2. Фильтрация всех экземпляров сервиса с оставлением только одного, соответствующего конкретному имени.
БЛОК №3. Последующая отмена привязки (если она была) и удаление сервиса.
БЛОК №4. И наконец, создание сервиса заново.
Затем ApplicationDeployer предоставляет само приложение (пример 23). Оно привязывается к сервису, который только что был подготовлен с помощью ServicesDeployer.
Пример 23. ApplicationDeployer
package bootcamp;
import org.cloudfoundry.operations.CloudFoundryOperations;
import org.cloudfoundry.operations.applications.PushApplicationRequest;
import org.cloudfoundry.operations.applications.
SetEnvironmentVariableApplicationRequest;
import org.cloudfoundry.operations.applications.StartApplicationRequest;
import org.cloudfoundry.operations.services.BindServiceInstanceRequest;
import reactor.core.publisher.Flux;
import reactor.core.publisher.Mono;
import java.io.File;
import java.time.Duration;
import java.util.HashMap;
import java.util.Map;
class ApplicationDeployer {
private final CloudFoundryOperations cf;
ApplicationDeployer(CloudFoundryOperations cf) {
this.cf = cf;
}
Mono<Void> deployApplication(File jar, String applicationName,
Map<String, String> envOg, Duration timeout, String... svcs) {
return cf.applications().push(pushApp(jar, applicationName)) // БЛОК №1
.then(bindServices(applicationName, svcs)) // БЛОК №2
.then(setEnvironmentVariables(applicationName, new HashMap<>(envOg))) // БЛОК №3
.then(startApplication(applicationName, timeout)); // БЛОК №4
}
private PushApplicationRequest pushApp(File jar, String applicationName) {
return PushApplicationRequest.builder().name(applicationName).noStart(true)
.randomRoute(true)
.buildpack("https://github.com/cloudfoundry/java-buildpack.git")
.application(jar.toPath()).instances(1).build();
}
private Mono<Void> bindServices(String applicationName, String[] svcs) {
return Flux
.just(svcs)
.flatMap(
svc -> {
BindServiceInstanceRequest request = BindServiceInstanceRequest.builder()
.applicationName(applicationName).serviceInstanceName(svc).build();
return cf.services().bind(request);
}).then();
}
private Mono<Void> startApplication(String applicationName, Duration timeout) {
return cf.applications().start(
StartApplicationRequest.builder().name(applicationName)
.stagingTimeout(timeout).startupTimeout(timeout).build());
}
private Mono<Void> setEnvironmentVariables(String applicationName,
Map<String, String> env) {
return Flux
.fromIterable(env.entrySet())
.flatMap(
kv -> cf.applications().setEnvironmentVariable(
SetEnvironmentVariableApplicationRequest.builder().name(applicationName)
.variableName(kv.getKey()).variableValue(kv.getValue()).build())).then();
}
}
БЛОК №1. Сначала добавляется двоичный файл приложения (путь к нему), указываются пакет buildpack, память и свойства развертывания наподобие счетчика экземпляров. Важно отметить, что пока приложение не запускается. Это будет сделано после привязки переменных среды и сервисов. Данный шаг выполняется в автоматическом режиме, когда используются манифесты Cloud Foundry.
БЛОК №2. Привязка экземпляров сервиса к вашему приложению.
БЛОК №3. Установка переменных среды для приложения.
БЛОК №4. И наконец, запуск приложения.
На запуск всего набора уходит немного времени, и его тратится еще меньше, если указать, какие именно ответвления выполняемого кода должны запускаться в разных потоках. Java-клиент Cloud Foundry — довольно эффективный способ описания сложных систем, которому, наряду с некоторыми другими Я отдю предпочтение. Он также очень удобен, когда развертывание требует применения не только обычного набора сценариев оболочки.
Заключение
В этой статье мы вкратце рассмотрели вопросы начала работы со Spring Boot и поддерживающий инструментарий (например, набор Spring Tool Suite), создание конфигурации Java и затем способы перемещения приложения в облачную среду. Мы автоматизировали развертывание кода в среде его промышленной эксплуатации и увидели, что будет совсем не сложно освоить процесс непрерывного развертывания. В следующих моих блогах все вопросы, касающиеся Spring Boot и Cloud Foundry, мы рассмотрим более обстоятельно.