 Приложения, работающие с электронными таблицами, такие как Microsoft Excel, широко применяются для хранения и исследования данных. В самом деле, электронная таблица - это удобный способ размещения данных и просмотра их различными способами. Можно без труда отсортировать данные по столбцам и тогда, чтобы узнать о каких-то свойствах данных, достаточно просто взглянуть на них, если, конечно, их объем не слишком велик.
Приложения, работающие с электронными таблицами, такие как Microsoft Excel, широко применяются для хранения и исследования данных. В самом деле, электронная таблица - это удобный способ размещения данных и просмотра их различными способами. Можно без труда отсортировать данные по столбцам и тогда, чтобы узнать о каких-то свойствах данных, достаточно просто взглянуть на них, если, конечно, их объем не слишком велик.
К сожалению, инструмент, удобный для просмотра и манипулирования данными, часто считают подходящим для хранения и совместного использования сложных данных. Но во многих случаях это не так.
Большинство пользователей хорошо знакомы с одной или несколькими электронными таблицами и свободно обращаются с данными, размещенными в несколько строк и столбцов, например представленными в электронной таблице StarOffice, которая хранит список клиентов (рис. 1):
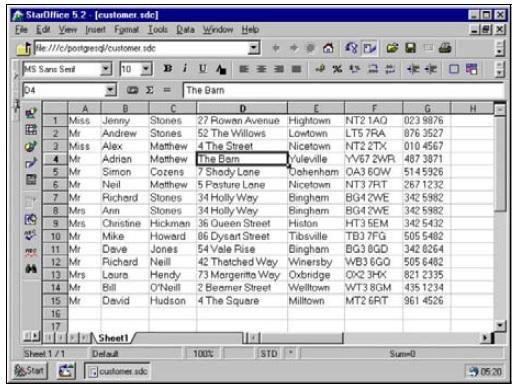
Рис. 1. Электронная таблица StarOffice с информацией о клиентах
Безусловно, такую информацию легко просматривать и модифицировать. Вероятно, даже не задумываясь об этом, мы сконструировали эту таблицу так, что она обладает некоторыми свойствами, которые окажутся удобными при проектировании баз данных. Каждому клиенту отведена отдельная строка, а каждый фрагмент информации о клиенте хранится в отдельном столбце. Например, имя и фамилия хранятся в разных столбцах, так что если потребуется выполнить сортировку по фамилии, это не создаст проблем.
Термины и определения
Прежде чем двигаться дальше, определим несколько терминов на примере небольшого участка данных. Наверняка вы все знаете о строках и столбцах, но давайте освежим эти знания (рис. 2):
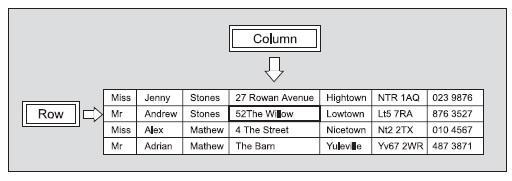
Рис. 2. Терминология электронных таблиц
Пересечение строки со столбцом образует ячейку. На снимке экрана StarOffice, представленном выше, ячейка с адресом «52 The Willow» выделена с помощью стрелок.
Недостатки электронных таблиц
Чем же плохо хранить информацию о клиентах в электронной таблице? Может быть, и ничем, если клиентов не слишком много, как и информации о каждом из них. А также если не нужно размещать данные, например о заказах, которые эти клиенты сделали, и если не очень много пользователей хотят одновременно обновлять информацию. Список возможных проблем зависит от конкретных обстоятельств.
Электронные таблицы очень удобны во многих и многих случаях, это замечательный инструмент для решения ряда задач. Однако, подобно тому как вы не стали бы (по крайней мере не следовало бы этого делать) забивать гвозди отверткой, в некоторых ситуациях не стоит использовать электронные таблицы.
Просто представьте себе, что большая компания с тысячами клиентов хранит их список в простой таблице. В большой компании обновления в такой список вносят, скорее всего, несколько человек. Блокировка файла может гарантировать, что в каждый момент времени только один пользователь обновляет список, при этом количество служащих, пытающихся ввести обновления, растет, и ждать своей очереди на редактирование им приходится все дольше и дольше. Хотелось бы сделать так, чтобы несколько человек могли одновременно читать, корректировать, добавлять и удалять строки. Очевидно, что простой блокировки недостаточно для того, чтобы эффективно решить эту проблему.
Предположим, что также необходимо хранить подробную информацию о каждом заказе клиента. Если размещать эти данные следом за сведениями о каждом заказчике, то при увеличении количества заказов таблица становится все более и более сложной. Посмотрите, что получится, если попытаться вводить некоторую базовую информацию о заказах рядом с данными их заказчика (рис. 3):
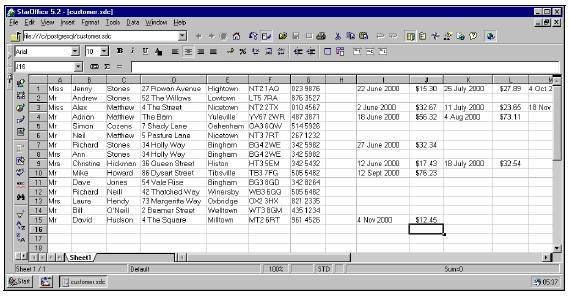
Рис. 3. Таблица с информацией о заказах
К сожалению, таблица уже не выглядит так красиво, как раньше. Теперь ее строки имеют произвольную длину, поэтому подсчитать, сколько клиент потратил денег, не так уж просто. Со временем будет превышено разрешенное для каждой строки количество столбцов. Это та же проблема повторяющихся групп, которая обсуждалась в этой статье.
Покажем на примере, насколько легко выйти за пределы возможностей электронной таблицы. Некто пытался создать таблицу для друга, у которого было свое небольшое дело. Он занимался производством изделий из кожи, при этом цена изделия зависела не только от количества времени, затраченного на его создание, но и от цены на кожу, пошедшую на изготовление. Владелец покупал кожу партиями, при этом в каждой партии цена единицы материала отличалась от предыдущей. Запасы кожи расходовались в порядке поступления (первый прибыл - первый использован), обычно из партии получалось несколько изделий. Требовалось создать электронную таблицу для:
- Наблюдения за складом
- Наблюдения за тем, сколько осталось партий кожи
- Отслеживания стоимости партии, использующейся в настоящий момент
- И, чтобы усложнить задачу, хранения количества различных сортов кожи
После нескольких дней попыток они поняли, что эта на первый взгляд простая задача отслеживания состояния имеющихся запасов неожиданно оказалась слишком сложной для решения при помощи электронной таблицы. Все дело в том, что количество записей должно быть переменным, что не очень-то согласуется с природой электронных таблиц.
Мы хотели показать, что электронные таблицы - это выдающееся средство для решения определенных задач, но область их применения ограничена.
В чем отличие таблицы от базы данных?
На первый взгляд кажется, что реляционная база данных, такая как PostgreSQL, во многом похожа на электронную таблицу, только является гораздо более гибким решением. Базы данных могут хранить значительно более сложную информацию и обладают рядом других свойств, например обеспечивают одновременный доступ нескольких пользователей, благодаря чему они удобнее для хранения данных.
Начнем с того, что сохраним в базе данных простой список клиентов, состоящий из одного листа, и посмотрим, какую выгоду можно извлечь из такого способа хранения. Позже в этой же главе будет рассказано о том, как PostgreSQL решает описанную ранее проблему с заказами клиентов.
Уже говорилось, что базы данных состоят из таблиц или, если применять формальную терминологию, из отношений. В этой книге авторы придерживаются понятия «таблица». Для начала необходимо спроектировать таблицу, в которой будет храниться информация о клиентах. Хорошая новость: уже имеющаяся электронная таблица является практически готовым решением, поскольку она хранит данные в некотором количестве строк и столбцов. Чтобы приступить к созданию основной таблицы базы данных, нужно ответить на три вопроса:
- Сколько нужно столбцов для хранения атрибутов, относящихся к каждому элементу?
- Какой тип данных будет храниться в каждом атрибуте (столбце)?
- Как различать разные строки, содержащие разные элементы?
Выбор столбцов
Вернемся к первоначальной электронной таблице с данными о клиентах. В ней уже представлен разумный набор столбцов для каждого клиента: имя, фамилия, почтовый индекс и т. д. С первым вопросом разобрались.
Выбор типа данных для каждого столбца
Теперь необходимо определить, данные какого типа будут находиться в каждом столбце. В электронной таблице каждая ячейка может иметь свой тип, а в базе данных данные в столбце должны иметь один и тот же тип. Как в большинстве языков программирования, столбцы базы данных принадлежат какому-либо типу. Чаще всего используются стандартные типы данных, поэтому обычно выбирать приходится между целыми числами, числами с плавающей точкой, текстом фиксированной длины, текстом переменной длины и датами. О типах данных PostgreSQL будет более подробно рассказано далее в этой главе, а также в главе 8. Часто легче всего выбрать соответствующий тип, просто посмотрев на примеры данных.
В нашем случае для всех столбцов годится текстовый тип, несмотря на то что номера телефонов представлены цифрами. Если хранить номер телефона как число, это может привести к потере начальный нулей, нельзя будет указывать международные коды (+), использовать скобки для кодов регионов и т. д. Не требуется особых усилий для того, чтобы понять, что во многих случаях номер телефона - это нечто большее, чем просто строка цифр.
Может быть, символьная строка тоже не является лучшим выбором для хранения телефонного номера (случайно можно сохранить посторонние символы), но в качестве отправной точки, несомненно, подходит больше, чем числовой тип. В дальнейшем всегда можно уточнить начальный проект. Очевидно, что длина слов первого столбца (Mr, Mrs, Dr) невелика и не превышает четырех символов. Аналогично, почтовые индексы также имеют ограниченную максимальную длину. Поэтому поля этих двух столбцов будут иметь фиксированную длину, а для всех остальных столбцов оставим длину переменной, потому что невозможно предугадать размер, например, фамилии человека.
Еще одно важное отличие базы данных от электронной таблицы заключается в том, что количество столбцов в таблице базы данных должно быть одинаковым во всех строках. В первой версии нашей электронной таблицы это требование выполняется.
Определение уникальности строк
Последнее изменение, которое необходимо внести, чтобы преобразовать электронную таблицу в базу данных, не столь очевидно, его необходимость вызвана особенностями управления отношениями между таблицами, существующими в базах данных. Следует решить, как сделать каждую строку с данными заказчика отличной от всех остальных клиентских строк в базе данных.
Другими словами, как различать клиентов? В электронной таблице не надо об этом заботиться, а вот при проектировании базы данных этот вопрос является ключевым, т. к. правила построения реляционных баз данных требуют, чтобы каждая строка была в некотором роде уникальной.
Казалось бы, на этот вопрос есть очевидный ответ - «по фамилии», но, к сожалению, такой вариант не проходит. Вполне возможно, что два клиента будут носить одну и ту же фамилию. Можно было бы выбрать в качестве отличительного признака номер телефона, но это не годится в том случае, если два клиента живут по одному и тому же адресу. Теперь можно дать волю воображению и предложить использовать комбинацию имени и номера телефона.
Конечно же, маловероятно, что два клиента с одинаковыми фамилиями могут иметь одинаковые номера телефонов, но (не говоря уже о том, что это решение не очень красиво) возникает проблема с сопровождением. Что если клиент сменит телефонную компанию и номер телефона? По нашему определению уникальности получается, что он должен стать новым клиентом, т. к. формально он отличается от того клиента, который существовал ранее, хотя на самом деле, конечно же, известно, что это один и тот же клиент с разными номерами телефонов.
При проектировании базы данных часто возникает вопрос об однозначной идентификации. Нужен «первичный ключ» - простой способ отличать одну строку с данными заказчика от остальных строк. К сожалению, цель еще не достигнута, но не все потеряно, стандартным решением является присваивание каждому клиенту уникального номера.
Все клиенты по очереди получают уникальный номер; так мы получаем возможность однозначной идентификации клиентов, на которую не влияют изменение номера телефона, переезд клиента и даже смена его фамилии. Проблема уникальности записей настолько распространена, что в PostgreSQL существует даже специальный тип данных, serial, используемый при ее решении. Далее в этой главе будет рассказано о таком типе данных.
Порядок строк
Есть еще одно важное отличие между данными, хранящимися в электронной таблице, и теми же данными в базе данных - в таблице порядок строк обычно бывает очень важен, в то время как в базе данных никакого порядка нет. Когда вы обращаетесь к таблице базы данных, строки могут быть выведены в любом порядке, если только нет явной инструкции упорядочить их по какому-либо признаку.